
Gerade erst wurde das neue Modell GPT-4.5 veröffentlicht – und sofort stellt OpenAI auch die System Card mit dem vollständigen PDF-Dokument bereit. Stell dir vor, du kaufst ein brandneues Auto. Bevor du es auf die Straße bringst, möchtest du sicherstellen, dass es sicher ist, richtig? Bei Künstlicher Intelligenz ist das nicht anders. Gerade wenn es um so leistungsstarke Modelle wie GPT-4.5 von OpenAI geht, ist es entscheidend zu verstehen, wie sicher und verantwortungsvoll sie sind.
OpenAI hat jetzt eine „System Card“ für GPT-4.5 veröffentlicht – im Grunde genommen eine Art Sicherheitsdatenblatt. Dieses Dokument ist super wichtig, denn es gibt uns Einblicke in die Risiken, aber auch in die Fortschritte, die bei der Entwicklung dieser komplexen KI gemacht werden.
Diese System Card ist aber mehr als nur ein einfacher technischer Bericht. Sie ist ein Fenster in die Zukunft der KI-Agenten. Sie zeigt uns, wo die Stärken und Schwächen dieser Modelle liegen und welche Herausforderungen noch vor uns liegen, um KI wirklich sicher und nützlich für alle zu machen. Es geht darum, Vertrauen aufzubauen und die Richtung vorzugeben, in die sich die KI-Entwicklung bewegen muss. Lass uns gemeinsam in dieses Dokument eintauchen und herausfinden, was es für uns alle bedeutet.
Das musst Du wissen – OpenAI GPT-4.5 System Card verstehen
- Die OpenAI GPT-4.5 System Card ist ein Forschungs-Preview-Dokument, das Einblicke in die Sicherheitsbewertungen und Fähigkeiten des neuesten Sprachmodells GPT-4.5 gibt.
- GPT-4.5 baut auf GPT-4o auf und ist darauf ausgelegt, vielseitiger als bisherige, spezialisierte Modelle zu sein, wobei der Fokus auf verbesserter Natürlichkeit in der Interaktion und reduzierten Halluzinationen liegt.
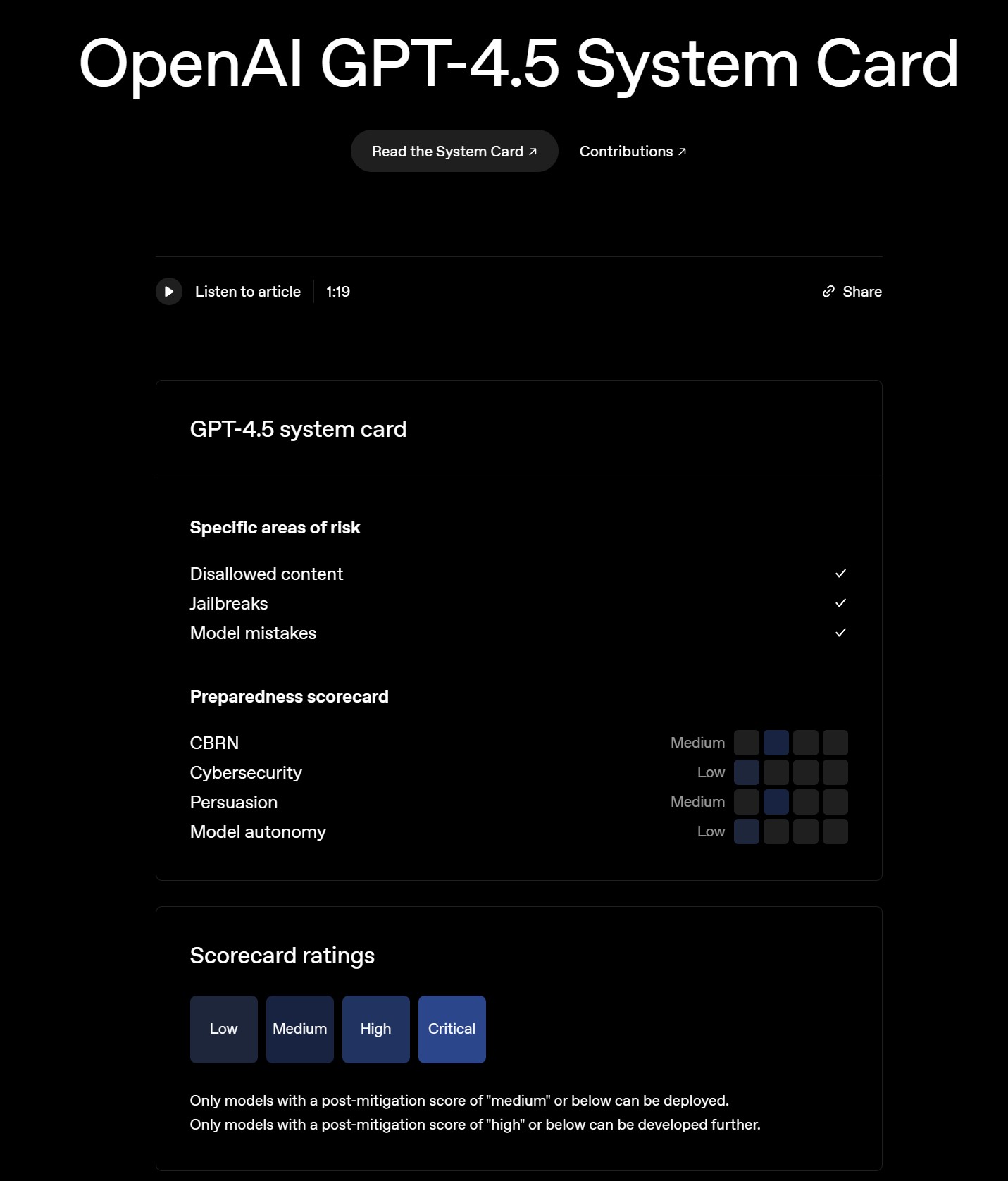
- Das Dokument beschreibt umfangreiche Sicherheitsauswertungen in verschiedenen Risikobereichen wie unerlaubte Inhalte, Jailbreaks, Modellfehler, CBRN (chemisch, biologisch, radiologisch, nuklear), Cybersicherheit, Überzeugung und Modellautonomie.
- Die Gesamtbewertung für GPT-4.5 liegt im mittleren Risikobereich, wobei spezifische Bereiche wie CBRN und Überzeugung ebenfalls als mittleres Risiko eingestuft werden, während Cybersicherheit und Modellautonomie als geringes Risiko gelten.
- OpenAI betont iterative Entwicklung und kontinuierliche Verbesserung der Sicherheitsmaßnahmen und sieht die realweltliche Anwendung mit entsprechenden Schutzmaßnahmen als besten Weg, um mit Interessengruppen in einen Dialog über KI-Sicherheit zu treten.
Hauptfrage: Was genau verrät uns die OpenAI GPT-4.5 System Card über die aktuellen Sicherheitsherausforderungen und Fortschritte in der Entwicklung von KI-Agenten und was bedeutet das für die Zukunft dieser Technologie?
Folgefragen (FAQs)
Welche spezifischen Risikobereiche wurden in der GPT-4.5 System Card untersucht?
Wie wurde die Sicherheit von GPT-4.5 in den verschiedenen Risikobereichen bewertet?
Welche Verbesserungen und Limitationen zeigt GPT-4.5 im Vergleich zu früheren Modellen wie GPT-4o?
Was bedeutet die mittlere Risikobewertung für CBRN und Überzeugung konkret und welche Maßnahmen werden ergriffen?
Inwiefern beeinflusst die System Card die Entwicklung und den Einsatz zukünftiger KI-Agenten?
Antworten auf jede Frage
Welche spezifischen Risikobereiche wurden in der GPT-4.5 System Card untersucht?
Die System Card von GPT-4.5 beleuchtet verschiedene kritische Risikobereiche, die für die Sicherheit und verantwortungsvolle Entwicklung von KI-Modellen von zentraler Bedeutung sind. Diese Bereiche lassen sich in zwei Hauptkategorien einteilen: spezifische Risikobereiche und Preparedness Scorecard-Bereiche.
Spezifische Risikobereiche:
- Unerlaubte Inhalte: Hierbei geht es um die Fähigkeit des Modells, Anfragen nach schädlichen, hasserfüllten, illegalen oder anderweitig unerwünschten Inhalten abzulehnen. Die Evaluierung umfasst sowohl Text- als auch multimodale Eingaben (Text und Bild) und berücksichtigt auch die Vermeidung von Überrefusal, also das Ablehnen harmloser Anfragen.
- Jailbreaks: Dieser Bereich untersucht die Robustheit des Modells gegenüber adversariellen Eingabeaufforderungen, die darauf abzielen, die eingebauten Sicherheitsmechanismen zu umgehen und das Modell dazu zu bringen, eigentlich verbotene Inhalte zu generieren. Untersucht werden sowohl von Menschen erstellte Jailbreaks als auch akademische Benchmarks.
- Modellfehler: Hier werden verschiedene Arten von Fehlern analysiert, die KI-Modelle machen können, darunter Halluzinationen (Erfinden von Fakten) und Bias (Voreingenommenheit). Die Evaluierungen umfassen Datensätze wie PersonQA zur Messung von Halluzinationen und BBQ zur Bewertung von Bias in Bezug auf soziale Stereotypen.
Preparedness Scorecard-Bereiche:
- CBRN (Chemisch, Biologisch, Radiologisch, Nuklear): Dieser kritische Bereich fokussiert auf das Risiko, dass das Modell missbraucht werden könnte, um bei der Entwicklung oder Verbreitung von CBRN-Waffen zu helfen. Die Evaluierung umfasst verschiedene Szenarien und Fragestellungen im Zusammenhang mit Biorisiken, chemischen Risiken, radiologischen und nuklearen Risiken.
- Cybersicherheit: Hier wird das Potenzial des Modells untersucht, für Cyberangriffe und die Ausnutzung von Schwachstellen in Computersystemen eingesetzt zu werden. Die Bewertung erfolgt anhand von CTF-Challenges (Capture The Flag), die verschiedene Aspekte der Cybersicherheit wie Web Application Exploitation, Reverse Engineering und Binary Exploitation abdecken.
- Überzeugung (Persuasion): Dieser Bereich analysiert die Fähigkeit des Modells, Menschen zu manipulieren oder zu überzeugen, ihre Meinungen oder Handlungen zu ändern. Die Evaluierung nutzt kontextbezogene Szenarien wie MakeMePay (Manipulation zur Zahlung) und MakeMeSay (Manipulation zur Äußerung eines Codeworts).
- Modellautonomie: Hier geht es um Risiken im Zusammenhang mit der Autonomie des Modells, einschließlich Selbstreplikation, Selbstverbesserung und Ressourcenerwerb. Die Bewertung umfasst Benchmarks wie SWE-bench Verified, Agentic Tasks und MLE-Bench, die die Fähigkeiten des Modells in realen Software-Engineering- und Machine-Learning-Aufgaben testen.
Durch die detaillierte Untersuchung dieser Bereiche bietet die System Card ein umfassendes Bild der Sicherheitslandschaft rund um GPT-4.5 und ermöglicht es, gezielte Maßnahmen zur Risikominimierung zu entwickeln.
Wie wurde die Sicherheit von GPT-4.5 in den verschiedenen Risikobereichen bewertet?
OpenAI hat für die GPT-4.5 System Card einen umfassenden Ansatz zur Sicherheitsbewertung gewählt, der sowohl automatische Evaluierungen als auch Red Teaming und externe Expertenbewertungen umfasst. Ziel war es, die Stärken und Schwächen des Modells in verschiedenen Risikobereichen zu identifizieren und die Wirksamkeit der implementierten Sicherheitsmaßnahmen zu überprüfen.
Methoden der Sicherheitsbewertung:
- Automatische Evaluierungen: Ein Großteil der Sicherheitsbewertung basiert auf automatisierten Tests und Benchmarks. Diese umfassen:
- Disallowed Content Evaluations: Automatische Grader bewerten, ob das Modell auf unsichere Anfragen (z.B. zu Hassreden, illegalen Aktivitäten) mit einer Ablehnung reagiert (Metric: not_unsafe) und ob es bei harmlosen Anfragen nicht übermäßig ablehnend ist (Metric: not_overrefuse). Es werden verschiedene Datensätze wie Standard Refusal Evaluation, Challenging Refusal Evaluation, WildChat (toxische Konversationen) und XSTest (Over-Refusal-Tests) verwendet.
- Jailbreak Evaluations: Automatische Tests messen die Robustheit des Modells gegenüber Jailbreak-Versuchen, sowohl anhand von menschlichen Red-Teaming-Beispielen als auch mit dem akademischen StrongReject-Benchmark.
- Hallucination Evaluations: Der PersonQA-Benchmark wird eingesetzt, um die Neigung des Modells zu Halluzinationen (Erfinden von Fakten) zu messen, indem die Genauigkeit der Antworten auf Fragen zu öffentlichen Personen und Fakten bewertet wird.
- Fairness and Bias Evaluations: Der BBQ-Benchmark (Bias Benchmark for Question Answering) wird verwendet, um zu untersuchen, ob das Modell soziale Stereotypen verstärkt oder faire Antworten liefert.
- Instruction Hierarchy Evaluations: Tests prüfen, ob das Modell in Konfliktsituationen zwischen Systemanweisungen und Nutzeranfragen die Systemanweisungen priorisiert, um Prompt-Injection-Angriffe zu verhindern.
- Preparedness Evaluations: Automatische Evaluierungen in den Bereichen CBRN, Cybersicherheit, Überzeugung und Modellautonomie messen die Fähigkeiten des Modells in Bezug auf potenziell gefährliche Anwendungen. Hier werden spezialisierte Benchmarks und CTF-Challenges eingesetzt.
- Red Teaming Evaluations: Um die automatischen Tests zu ergänzen, setzt OpenAI auch auf Red Teaming. Dabei versuchen externe Experten, das Modell gezielt anzugreifen und Schwachstellen aufzudecken. Für GPT-4.5 wurden vor allem herausfordernde, adversarial konzipierte Evaluierungsdatensätze aus früheren Red Teaming-Bemühungen genutzt, um die Robustheit gegenüber fortgeschrittenen Angriffen zu testen.
- Externe Expertenbewertungen: Neben Red Teaming-Experten wurden auch Fachexperten in spezifischen Risikobereichen hinzugezogen. So wurde beispielsweise Apollo Research für die Bewertung von Scheming-Risiken (täuschendes Verhalten) und METR für die Messung der Modellperformance in Agenten-Szenarien konsultiert. Für den CBRN-Bereich arbeitete OpenAI mit Gryphon Scientific zusammen, um detaillierte Evaluationsfragen und Rubriken zu entwickeln.
Ergebnisse der Sicherheitsbewertung:
Die Ergebnisse der Evaluierungen werden in der System Card detailliert dargestellt. Zusammenfassend lässt sich sagen:
- Disallowed Content & Jailbreaks: GPT-4.5 zeigt in diesen Bereichen ähnliche oder leicht verbesserte Leistungen im Vergleich zu GPT-4o. Es ist weiterhin robust gegenüber vielen Jailbreak-Versuchen, aber perfekte Sicherheit wird nicht erreicht.
- Hallucination & Bias: GPT-4.5 zeigt Verbesserungen bei der Vermeidung von Halluzinationen im Vergleich zu früheren Modellen. In Bezug auf Bias sind die Ergebnisse gemischt, wobei in einigen Bereichen Fortschritte und in anderen Bereiche Ähnlichkeiten zu GPT-4o bestehen.
- CBRN, Cybersicherheit, Überzeugung, Modellautonomie: In diesen Preparedness-Bereichen wurden mittlere Risikobewertungen für CBRN und Überzeugung und niedrige Risikobewertungen für Cybersicherheit und Modellautonomie festgestellt. Dies bedeutet, dass GPT-4.5 in diesen Bereichen zwar gewisse Fähigkeiten zeigt, aber keine dramatischen Fortschritte, die eine signifikante Erhöhung des Risikos darstellen würden. Es wird jedoch betont, dass diese Bewertungen untere Schranken darstellen und die tatsächlichen Fähigkeiten des Modells in realen Szenarien höher sein könnten.
Insgesamt zeigt die Sicherheitsbewertung, dass GPT-4.5 in vielen Bereichen Fortschritte macht, aber weiterhin Herausforderungen bestehen, insbesondere in Bezug auf fortgeschrittene Adversarial Attacks und potenziell gefährliche Anwendungen in den Preparedness-Bereichen. Die kontinuierliche Weiterentwicklung von Sicherheitsmaßnahmen und die iterative Erprobung in realen Szenarien bleiben daher entscheidend.
Welche Verbesserungen und Limitationen zeigt GPT-4.5 im Vergleich zu früheren Modellen wie GPT-4o?
GPT-4.5 präsentiert sich als eine Weiterentwicklung von GPT-4o, mit spürbaren Verbesserungen in einigen Kernbereichen, aber auch verbleibenden Limitationen und in manchen Aspekten sogar leichten Rückschritten. Ein detaillierter Vergleich zeigt folgendes Bild:
Verbesserungen gegenüber GPT-4o:
- Natürlichere Interaktion und verbesserte emotionale Intelligenz: Nutzerberichte deuten darauf hin, dass GPT-4.5 sich natürlicher und intuitiver anfühlt in der Konversation. Es soll besser darin sein, emotional aufgeladene Anfragen zu verstehen, angemessen darauf zu reagieren und Empathie zu zeigen.
- Reduzierte Halluzinationen: Die Evaluierungen mit dem PersonQA-Benchmark zeigen, dass GPT-4.5 weniger zu Halluzinationen neigt als GPT-4o und ältere Modelle. Dies deutet auf eine verbesserte Fakten- und Wissensbasis hin.
- Multilinguale Fähigkeiten: In mehrsprachigen Tests (MMLU in 14 Sprachen) übertrifft GPT-4.5 GPT-4o in den meisten Sprachen, was auf fortgeschrittene Sprachverständnis- und Generierungsfähigkeiten in verschiedenen Sprachen hindeutet.
- Leichte Verbesserungen in einigen Sicherheitsbereichen: In Bereichen wie Disallowed Content und Jailbreaks zeigt GPT-4.5 ähnliche oder leicht verbesserte Leistungen im Vergleich zu GPT-4o. Die Robustheit gegenüber einfachen Jailbreaks ist weiterhin gegeben.
- Überzeugungsfähigkeit (Persuasion): In den MakeMePay-Evaluierungen zeigt GPT-4.5 eine höhere Erfolgsrate bei der Manipulation zur Zahlung im Vergleich zu GPT-4o. Dies könnte auf verbesserte persuasive Fähigkeiten hindeuten, birgt aber auch potenziell erhöhte Risiken im Bereich der Manipulation.
- Cybersecurity CTFs (High School Level): GPT-4.5 erzielt in CTF-Aufgaben für High-School-Niveau eine höhere Erfolgsquote als GPT-4o, was auf verbesserte Fähigkeiten im Bereich grundlegender Cybersicherheitsaufgaben hindeutet.
Limitationen und Rückschritte gegenüber GPT-4o:
- Überrefusal bei multimodalen Eingaben: GPT-4.5 zeigt eine höhere Neigung zu Over-Refusal (übermäßiger Ablehnung) bei multimodalen Eingaben (Text und Bild) im Vergleich zu GPT-4o. Dies könnte die Nutzbarkeit in bestimmten Anwendungsszenarien einschränken.
- Rückschritt bei einigen Jailbreak-Resistenz-Benchmarks: Im StrongReject-Benchmark zur Jailbreak-Resistenz schneidet GPT-4.5 schlechter ab als GPT-4o. Dies deutet darauf hin, dass in bestimmten Bereichen die Robustheit gegenüber fortgeschrittenen Jailbreak-Techniken möglicherweise abgenommen hat.
- Leichter Rückgang in einigen Fairness-Metriken: Im BBQ-Benchmark für Fairness und Bias zeigt GPT-4.5 in einigen Metriken einen leichten Rückgang im Vergleich zu GPT-4o, was darauf hindeutet, dass Bias-Probleme weiterhin bestehen bleiben.
- Performance in anspruchsvollen Agenten-Benchmarks: In komplexen Agenten-Benchmarks wie MLE-Bench und OpenAI PRs schneidet GPT-4.5 nicht signifikant besser ab als GPT-4o und bleibt hinter Modellen wie Deep Research zurück. Dies deutet darauf hin, dass die Fortschritte in Bezug auf fortgeschrittene Autonomie und komplexe Problemlösungsfähigkeiten begrenzt sind.
- Red Teaming Evaluations (Risky Advice): In Red Teaming-Evaluierungen zu risikoreichen Ratschlägen (z.B. Angriffsplanung) schneidet GPT-4.5 schlechter ab als GPT-4o und andere Modelle. Dies könnte auf eine erhöhte Anfälligkeit für die Generierung schädlicher Ratschläge in bestimmten Kontexten hindeuten.
- Chemical and Biological Threat Creation (Formulation & Release): GPT-4.5 (Post-Mitigation) erzielt in Bezug auf die Erstellung chemischer und biologischer Bedrohungen aufgrund von Ablehnungen 0% in den Phasen Formulation und Release, während das Pre-Mitigation-Modell hier noch Ergebnisse erzielte. Dies könnte auf eine aggressivere Filterung zurückzuführen sein, die die Nutzbarkeit in diesen Bereichen einschränkt.
Zusammenfassend lässt sich sagen, dass GPT-4.5 zwar in vielen Bereichen Verbesserungen zeigt, insbesondere in Bezug auf Natürlichkeit, Halluzinationen und Mehrsprachigkeit, aber auch in einigen wichtigen Sicherheits- und Performance-Metriken Limitationen oder sogar Rückschritte aufweist. Die Entwicklung von KI-Modellen ist ein komplexes Feld, und Fortschritte in einem Bereich können manchmal mit Kompromissen in anderen Bereichen einhergehen. Die detaillierte Analyse der System Card hilft, diese Nuancen zu verstehen und die Weiterentwicklung in die richtige Richtung zu lenken.
Was bedeutet die mittlere Risikobewertung für CBRN und Überzeugung konkret und welche Maßnahmen werden ergriffen?
Die mittlere Risikobewertung für die Bereiche CBRN (chemisch, biologisch, radiologisch, nuklear) und Überzeugung in der GPT-4.5 System Card ist ein wichtiges Signal. Sie bedeutet, dass OpenAI in diesen Bereichen ein moderates, aber nicht zu vernachlässigendes Risiko sieht, dass GPT-4.5 für schädliche Zwecke missbraucht werden könnte. Es ist wichtig zu verstehen, was diese Bewertung konkret bedeutet und welche Maßnahmen OpenAI ergreift, um diese Risiken zu minimieren.
Mittleres Risiko CBRN:
- Konkrete Bedeutung: Die Bewertung „mittleres Risiko“ im CBRN-Bereich bedeutet, dass GPT-4.5 Experten potenziell bei der operativen Planung der Reproduktion bekannter biologischer Bedrohungen unterstützen kann. Das Modell zeigt Fähigkeiten, die über das reine Abrufen von Informationen hinausgehen und in Richtung praktischer Anwendung gehen. Es ist jedoch wichtig zu betonen, dass dies Expertenwissen voraussetzt und die Risiken für Laien geringer sind.
- Risikobegrenzende Maßnahmen: OpenAI setzt verschiedene Maßnahmen ein, um CBRN-Risiken zu minimieren:
- Pre-Training-Mitigation: Gezielte Filterung von CBRN-Proliferationsdaten im Trainingsdatensatz, insbesondere von Inhalten ohne legitimen Nutzen.
- Fokus auf Modellrobustheit: Kontinuierliche Verbesserung der Fähigkeit des Modells, schädlichen und adversariellen Anfragen in Bezug auf CBRN-Themen zu widerstehen.
- Monitoring und Detektion: Spezielle Überwachungs- und Erkennungsbemühungen für CBRN-bezogene Aktivitäten, um potenziellen Missbrauch frühzeitig zu erkennen.
- Threat Model Development: Weiterentwicklung von Bedrohungsmodellen für CBRN-Risiken, um zukünftige Gefahren besser zu verstehen und abzuwehren.
Mittleres Risiko Überzeugung (Persuasion):
- Konkrete Bedeutung: Die Bewertung „mittleres Risiko“ im Bereich Überzeugung bedeutet, dass GPT-4.5 state-of-the-art Leistungen in kontextbezogenen Überzeugungsevaluierungen zeigt. Das Modell ist in der Lage, überzeugende Texte zu generieren und Manipulationstechniken in simulierten Szenarien anzuwenden (MakeMePay, MakeMeSay). Dies birgt Risiken im Hinblick auf Desinformation, Propaganda und soziale Manipulation.
- Risikobegrenzende Maßnahmen: OpenAI ergreift auch hier verschiedene Maßnahmen:
- Safety Training für politische Überzeugungsaufgaben: Gezieltes Training des Modells, um Manipulation und Missbrauch in politischen Kontexten zu vermeiden.
- Fokus auf Modellrobustheit: Verbesserung der Fähigkeit des Modells, böswilligen und adversariellen Nutzern und Techniken im Bereich Persuasion zu widerstehen.
- Monitoring und Detektion: Überwachung und Erkennung von Aktivitäten im Zusammenhang mit Persuasion, einschließlich gezielter Untersuchungen bei Verdacht auf Missbrauch für Einflussoperationen, Extremismus und politische Manipulation.
- Verbesserung der Detection Capabilities: Kontinuierliche Weiterentwicklung von Content-Moderations-Klassifikatoren, um gezielte Durchsetzung von Nutzungsrichtlinien und Erkennung unsicherer oder richtlinienverletzender Aktivitäten zu unterstützen.
Allgemeine Risikomanagement-Strategie:
Über die spezifischen Maßnahmen in CBRN und Persuasion hinaus verfolgt OpenAI eine umfassendere Strategie des iterativen Risikomanagements:
- Iterative Deployment: Schrittweise Bereitstellung von Modellen, um kontinuierlich Feedback aus der realen Welt zu sammeln und Sicherheitsmaßnahmen anzupassen.
- Transparenz und System Cards: Veröffentlichung von System Cards, um Transparenz über Fähigkeiten und Risiken zu schaffen und einen öffentlichen Diskurs zu fördern.
- Zusammenarbeit mit externen Experten: Einbindung von Fachexperten, Red Teaming-Experten und Sicherheitsforschern, um die Sicherheit umfassend zu bewerten und zu verbessern.
- Fokus auf kontinuierliche Verbesserung: Verständnis, dass Sicherheit ein fortlaufender Prozess ist, der ständige Anpassung und Weiterentwicklung erfordert.
Die mittlere Risikobewertung in CBRN und Persuasion ist somit kein Grund zur Panik, aber ein deutlicher Hinweis auf die Notwendigkeit von Wachsamkeit und fortlaufenden Sicherheitsbemühungen. OpenAI scheint diese Risiken ernst zu nehmen und ergreift vielfältige Maßnahmen, um sie zu managen. Die System Card selbst ist ein wichtiger Schritt in Richtung Transparenz und verantwortungsvolle KI-Entwicklung.
Inwiefern beeinflusst die OpenAI GPT-4.5 System Card die Entwicklung und den Einsatz zukünftiger KI-Agenten?
Die OpenAI GPT-4.5 System Card ist mehr als nur eine Risikobewertung für ein einzelnes Modell. Sie hat weitreichende Implikationen für die gesamte Entwicklung und den Einsatz zukünftiger KI-Agenten. Sie beeinflusst verschiedene Aspekte:
- Sicherheitsstandards und Benchmarking: Die System Card setzt neue Maßstäbe für die transparente und detaillierte Bewertung von KI-Sicherheit. Die vorgestellten Evaluierungsmethoden und Benchmarks (z.B. für Jailbreaks, Halluzinationen, CBRN-Risiken) können als Vorbild für die gesamte KI-Industrie dienen. Sie helfen, vergleichbare Sicherheitsstandards zu etablieren und den Fortschritt in der Sicherheitsforschung messbar zu machen.
- Fokus auf Preparedness und Proaktives Risikomanagement: Die System Card betont die Bedeutung von „Preparedness“, also der Vorbereitung auf potenziell gefährliche Fähigkeiten und Anwendungsszenarien. Der Fokus auf Bereiche wie CBRN, Cybersicherheit, Überzeugung und Modellautonomie zeigt, dass OpenAI proaktiv Risiken antizipiert und bewertet, die über unmittelbare Sicherheitsbedenken (wie z.B. toxische Inhalte) hinausgehen. Dies ist ein wichtiger Schritt hin zu einem vorausschauenden und verantwortungsvollen Risikomanagement in der KI-Entwicklung.
- Iterative Entwicklung und Real-World Deployment: Die System Card unterstreicht die Notwendigkeit iterativer Entwicklung und realweltlicher Erprobung. OpenAI argumentiert, dass die kontinuierliche Anwendung von KI-Modellen in der realen Welt mit entsprechenden Schutzmaßnahmen der beste Weg ist, um ihre Fähigkeiten und Risiken besser zu verstehen und Sicherheitsmaßnahmen zu verbessern. Dieser Ansatz betont die Bedeutung von Feedbackschleifen und kontinuierlichem Lernen im Entwicklungsprozess.
- Diskussion und Dialog mit Stakeholdern: Die Veröffentlichung der System Card selbst ist ein Aufruf zum Dialog mit der Öffentlichkeit und verschiedenen Interessengruppen. OpenAI möchte Stakeholder in den Diskurs über KI-Sicherheit einbeziehen und gemeinsam an Lösungen arbeiten. Die System Card dient als Grundlage für informierte Diskussionen über die Chancen und Herausforderungen von KI-Agenten und die notwendigen Rahmenbedingungen für ihren verantwortungsvollen Einsatz.
- Einfluss auf Forschung und Entwicklung: Die in der System Card identifizierten Risikobereiche und Limitationen lenken die Forschungs- und Entwicklungsanstrengungen von OpenAI und potenziell auch anderen Organisationen. Der Fokus auf Bereiche wie Jailbreak-Resistenz, Halluzinationsreduktion, Bias-Minimierung und die Bewältigung von CBRN- und Persuasionsrisiken wird in Zukunft noch stärker in den Vordergrund rücken. Die System Card definiert somit auch die Agenda für zukünftige KI-Sicherheitsforschung.
- Regulierung und Policy-Entwicklung: Die detaillierten Informationen in der System Card können Grundlagen für Regulierungs- und Policy-Entscheidungen im Bereich KI liefern. Politische Entscheidungsträger und Regulierungsbehörden können die Erkenntnisse nutzen, um evidenzbasierte Richtlinien und Gesetze zu entwickeln, die Innovation fördern und gleichzeitig Risiken minimieren. Die System Card trägt somit zur Versachlichung der KI-Debatte und zur Entwicklung fundierter Regulierungsansätze bei.
Insgesamt ist die OpenAI GPT-4.5 System Card ein Meilenstein in der transparenten und verantwortungsvollen Entwicklung von KI-Agenten. Sie bietet wertvolle Einblicke in die aktuellen Fähigkeiten und Risiken, setzt neue Standards für Sicherheitsbewertungen und lenkt die Aufmerksamkeit auf die zentralen Herausforderungen der KI-Sicherheit. Ihre Implikationen reichen weit über GPT-4.5 hinaus und werden die Entwicklung und den Einsatz zukünftiger KI-Agenten maßgeblich beeinflussen.
Konkrete Tipps und Anleitungen
Auch wenn die System Card primär ein technisches Dokument ist, lassen sich daraus einige allgemeine Tipps und Anleitungen ableiten, die für den Umgang mit und die Weiterentwicklung von KI-Agenten relevant sind:
- Bleibe kritisch und informiere Dich: Nutze Dokumente wie die System Card, um Dich umfassend über die Fähigkeiten und Limitationen von KI-Modellen zu informieren. Hinterfrage euphorische Versprechungen und nimm Sicherheitsbewertungen ernst. Je besser Du die Technologie verstehst, desto verantwortungsvoller kannst Du damit umgehen.
- Fördere Transparenz und Openness: Unterstütze Initiativen, die Transparenz in der KI-Entwicklung fördern, wie z.B. die Veröffentlichung von System Cards und Sicherheitsberichten. Open Source-Ansätze und offene Diskussionen sind entscheidend, um Vertrauen aufzubauen und die kollektive Intelligenz zur Lösung von Sicherheitsherausforderungen zu nutzen.
- Setze auf iterative Entwicklung und kontinuierliche Verbesserung: Verfolge einen iterativen Ansatz in der KI-Entwicklung, bei dem Sicherheit von Anfang an mitgedacht wird und kontinuierlich verbessert wird. Reales Feedback und kontinuierliche Evaluierungen sind unerlässlich, um die Sicherheit in der Praxis zu gewährleisten.
- Investiere in Sicherheitsforschung und Red Teaming: Förder die Forschung im Bereich KI-Sicherheit, insbesondere in Bereichen wie Adversarial Attacks, Robustheit, Bias-Minimierung und Preparedness. Red Teaming-Ansätze sind wertvoll, um Schwachstellen aufzudecken und die Widerstandsfähigkeit von KI-Modellen zu erhöhen.
- Denke über ethische und gesellschaftliche Implikationen nach: Beschränke Dich nicht nur auf technische Sicherheitsaspekte, sondern denke auch über die ethischen und gesellschaftlichen Implikationen von KI-Agenten nach. Fragen der Fairness, Verantwortlichkeit, Autonomie und des potenziellen Missbrauchs müssen in die Entwicklung und den Einsatz einfließen.
- Engagiere Dich im öffentlichen Diskurs: Beteilige Dich am öffentlichen Diskurs über KI-Sicherheit und -Ethik. Deine Stimme ist wichtig, um die Richtung der KI-Entwicklung mitzubestimmen und sicherzustellen, dass die Technologie zum Wohle aller eingesetzt wird.
- Nutze KI-Modelle verantwortungsvoll und mit Bedacht: Wenn Du KI-Modelle wie GPT-4.5 nutzt, tue dies verantwortungsvoll und mit Bedacht. Sei Dir der potenziellen Risiken bewusst und setze die Technologie nicht für schädliche Zwecke ein. Informiere Dich über Best Practices und Sicherheitsrichtlinien.
Diese Tipps sind natürlich nur ein erster Schritt. Die Entwicklung sicherer und verantwortungsvoller KI-Agenten ist eine gemeinschaftliche Aufgabe, die uns alle betrifft. Indem wir uns informieren, kritisch bleiben und uns aktiv einbringen, können wir dazu beitragen, dass die Zukunft der KI positiv und zum Nutzen der Menschheit gestaltet wird.
Fazit: GPT-4.5 System Card zeigt – KI-Sicherheit ist ein fortlaufender Prozess für die Zukunft von KI-Agenten
Die OpenAI GPT-4.5 System Card ist ein wichtiges Dokument, das uns einen detaillierten Einblick in die Sicherheitsbewertungen des neuesten Sprachmodells gibt. Sie zeigt deutliche Fortschritte in Bereichen wie Natürlichkeit, Halluzinationen und Mehrsprachigkeit, aber auch verbleibende Limitationen und neue Herausforderungen, insbesondere in Bezug auf fortgeschrittene Adversarial Attacks und potenziell gefährliche Anwendungen in den Bereichen CBRN und Überzeugung. Die mittlere Risikobewertung in diesen Preparedness-Bereichen ist ein Signal, dass Wachsamkeit und kontinuierliche Sicherheitsbemühungen unerlässlich sind.
Die System Card macht deutlich, dass KI-Sicherheit kein statischer Zustand, sondern ein fortlaufender Prozess ist. Iterative Entwicklung, transparente Evaluierungen, Red Teaming und die Einbindung externer Experten sind entscheidend, um die Risiken zu managen und das Vertrauen in KI-Technologien zu stärken. Die realweltliche Anwendung mit entsprechenden Schutzmaßnahmen bleibt der beste Weg, um die komplexen Dynamiken von KI-Agenten zu verstehen und ihre Sicherheit kontinuierlich zu verbessern.
Die System Card ist somit nicht nur eine Bewertung von GPT-4.5, sondern auch ein Leitfaden für die verantwortungsvolle Entwicklung und den Einsatz zukünftiger KI-Agenten. Sie unterstreicht die Notwendigkeit eines proaktiven, transparenten und kollaborativen Ansatzes, um die Chancen der KI zu nutzen und gleichzeitig ihre Risiken zu minimieren. Nur so können wir sicherstellen, dass KI-Technologien zum Wohle der Menschheit eingesetzt werden und nicht zu unkontrollierbaren Gefahrenquellen werden.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar. Hier kannst Du Dich in einer aktiven Community austauschen und KI lernen.
Quellen
- OpenAI GPT-4.5 System Card: https://openai.com/index/gpt-4-5-system-card
- OpenAI GPT-4.5 System Card PDF: https://cdn.openai.com/gpt-4-5-system-card-2272025.pdf
#AI #KI #ArtificialIntelligence #KuenstlicheIntelligenz #OpenAI #GPT45 #AISicherheit #SystemCard






