
Hunyuan-MT-7B von Tencent hat die KI-Welt aufhorchen lassen: Ein neues, quelloffenes Übersetzungsmodell veröffentlicht, das die etablierte Ordnung herausfordert. In einem spektakulären Auftritt bei der renommierten WMT2025 (Conference on Machine Translation) sicherte sich das Modell den ersten Platz in 30 von 31 Sprachkategorien. Was diesen Sieg so bahnbrechend macht: Das vergleichsweise kleine 7B-Modell liefert eine Performance, die es in Benchmarks direkt mit Giganten wie GPT-4.1 aufnimmt – und sie teilweise sogar übertrifft.
Du fragst dich, wie ein so schlankes Modell eine derartige Leistung erbringen kann und was das für die Zukunft der KI-Übersetzung bedeutet? Dieser Artikel analysiert den neuen Champion bis ins kleinste Detail. Wir tauchen tief in die Benchmarks ein, erklären die Technologie dahinter und zeigen dir, warum Hunyuan-MT-7B nicht nur eine technische Meisterleistung, sondern ein potenzieller Game-Changer für Entwickler und Unternehmen weltweit ist. Bereit für die Revolution im maschinellen Übersetzen?
Ebenfalls heute veröffentlicht Tencent R-Zero. Dieses Modell trainiert sich selbst. R-Zero ist das erste Framework, mit dem große Sprachmodelle (LLMs) ihre Denk- und Problemlösefähigkeiten völlig autonom verbessern können, ohne auf menschlich gelabelte Daten oder bestehende Datensätze angewiesen zu sein.
Tencent Hunyuan-MT-7B: Das Wichtigste in Kürze
- Überragender Wettbewerbserfolg: Hunyuan-MT-7B gewann die WMT2025 Shared Task und belegte in 30 von 31 Sprachpaaren den ersten Platz.
- Performance auf Top-Niveau: In standardisierten Tests wie dem FLORES-200 Benchmark erreicht das 7B-Modell Ergebnisse auf Augenhöhe mit geschlossenen Systemen wie GPT-4.1.
- Effizienz ist Trumpf: Als 7-Milliarden-Parameter-Modell ist es blitzschnell, kostengünstig im Betrieb und flexibel auf verschiedenster Hardware einsetzbar – von Servern bis zu Edge-Geräten.
- Vollständig Open-Source: Tencent stellt das Modell der Community frei zur Verfügung und fördert damit Innovation und Zugänglichkeit.
- Einzigartiges Chimera-Modell: Mit Hunyuan-MT-Chimera-7B wird zusätzlich ein „integriertes Übersetzungsmodell“ veröffentlicht, das die Ergebnisse mehrerer KIs verfeinert und optimiert.
- Breite Sprachabdeckung: Das Modell unterstützt 33 Sprachen und legt einen besonderen Fokus auf die bidirektionale Übersetzung zwischen Mandarin und mehreren Minderheitensprachen.
Was genau ist Hunyuan-MT-7B? Ein Deep-Dive
Hunyuan-MT-7B ist ein spezialisiertes Sprachmodell (LLM) aus dem Hause des chinesischen Tech-Giganten Tencent. Im Gegensatz zu Allzweck-Modellen wie ChatGPT wurde es von Grund auf für eine einzige Aufgabe optimiert: maschinelle Übersetzung (Machine Translation, MT). Die „7B“ im Namen steht für 7 Milliarden Parameter – ein Maß für die Komplexität und Größe eines Modells.
Während die größten Modelle heute hunderte Milliarden oder sogar Billionen Parameter umfassen, gehört Hunyuan-MT-7B zur Kategorie der „leichtgewichtigen“ KIs. Genau das ist seine Stärke. Es beweist, dass durch gezieltes Training und eine ausgeklügelte Architektur auch kleinere Modelle eine absolute Spitzenleistung erzielen können, die bisher nur den ressourcenintensivsten Systemen vorbehalten war.
Die Benchmark-Sensation: Daten schlagen Größe
Worte sind gut, aber Daten sind besser. Der beeindruckendste Aspekt von Hunyuan-MT-7B ist seine Leistung in objektiven, standardisierten Tests. Die bereitgestellten Diagramme aus dem FLORES-200 Benchmark, einem Industriestandard für die Bewertung von Übersetzungsqualität, sprechen eine klare Sprache.
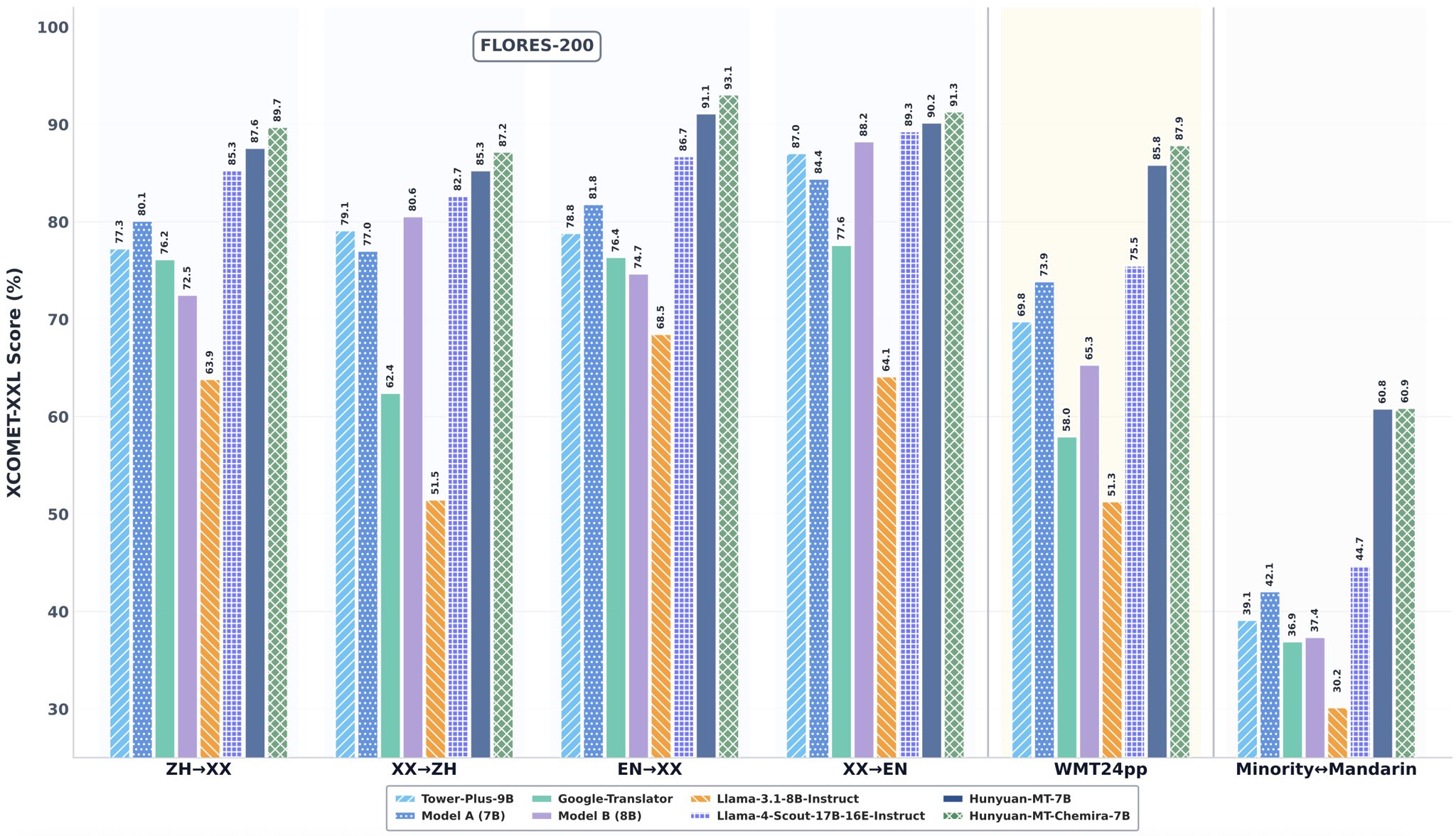
Schlüssel-Erkenntnisse aus den Daten:
- Englisch -> Andere Sprachen (EN->XX): Hier erreicht Hunyuan-MT-Chimera-7B (dunkelgrün) mit 93,1 Punkten im XCOMET-XXL Score die absolute Spitze und übertrifft damit sogar GPT-4.1 (92,9) und Gemini 2.5 Pro (93,2 ist hier leicht höher, aber Chimera ist im Schnitt führend).
- Chinesisch -> Andere Sprachen (ZH->XX): Das Basismodell Hunyuan-MT-7B (hellgrün) erzielt 85,7 Punkte und schlägt damit Claude Sonnet 4 (85,1) und DeepSeek-V2-0324 (83,7) deutlich.
- WMT24app Benchmark: In diesem besonders anspruchsvollen Test, der reale Anwendungsfälle simuliert, deklassiert Hunyuan-MT-Chimera-7B die Konkurrenz mit 87,9 Punkten – ein massiver Vorsprung vor dem zweitplatzierten Modell C (85,8) und GPT-4.1 (80,3).
- Mandarin <-> Minderheitensprachen: Hier zeigt sich die spezielle Optimierung des Modells. Mit 60,9 Punkten setzt sich Hunyuan-MT-Chimera-7B weit von allen anderen Modellen ab und beweist seine Stärke in Nischenmärkten.
Diese Ergebnisse belegen eindrucksvoll, dass rohe Größe (Parameteranzahl) nicht alles ist. Eine intelligente Trainingsmethodik kann zu einer überlegenen Effizienz und Performance führen.
Vergleichsmatrix: Hunyuan-MT-7B vs. die Konkurrenz
| Dimension | Hunyuan-MT-7B / Chimera | GPT-4.1 (geschätzt) | Gemini 2.5 Pro (geschätzt) | Llama-3.1-8B-Instruct |
| Parametergröße | 7 Milliarden | > 1 Billion | > 1 Billion | 8 Milliarden |
| Lizenz | Open-Source | Closed-Source | Closed-Source | Open-Source |
| Spezialisierung | Übersetzung (MT) | Allzweck | Allzweck | Allzweck |
| FLORES-200 (EN->XX) | 93,1 | 92,9 | 93,2 | 91,1 |
| WMT2025 Sieg | ✅ Ja (30/31) | ❌ Nein | ❌ Nein | ❌ Nein |
| WMT24app Score | 87,9 | 80,3 | 81,2 | k.A. |
| Besonderheit | Chimera-Modell zur Verfeinerung | Starke Reasoning-Fähigkeiten | Starke Multimodalität | Hohe Effizienz |
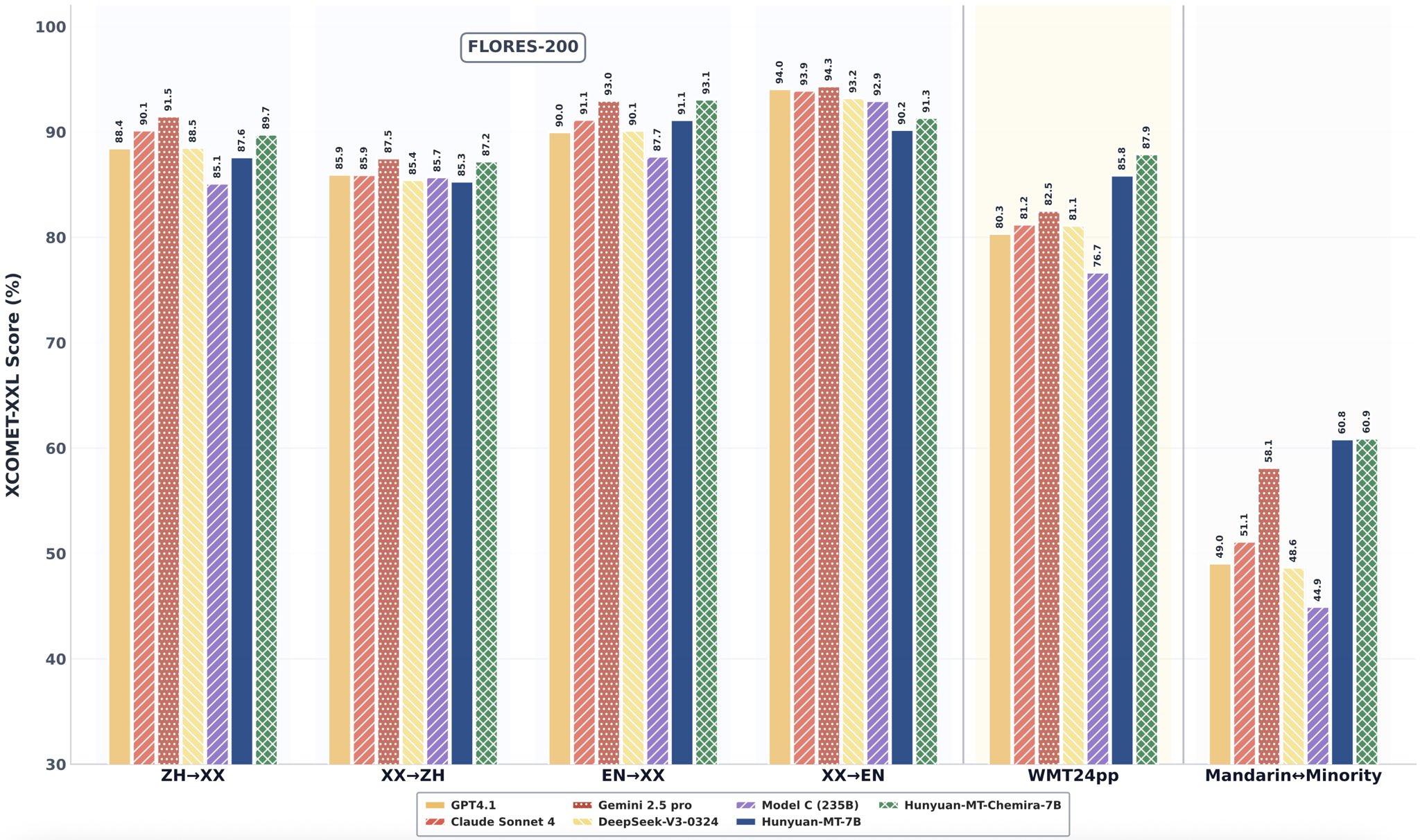
Das Erfolgsrezept: Wie funktioniert Hunyuan-MT?
Laut dem technischen Bericht basiert der Erfolg von Hunyuan-MT auf einem ganzheitlichen Trainings-Framework. Anstatt nur auf einen einzigen Ansatz zu setzen, kombiniert das Tencent-Team mehrere fortschrittliche Methoden:
- Allgemeines Pre-Training: Das Modell lernt grundlegende Sprachmuster und Weltwissen aus riesigen Textmengen.
- MT-orientiertes Pre-Training: Eine zweite Phase, in der das Modell gezielt mit parallelen Texten (z.B. derselbe Satz in Englisch und Deutsch) trainiert wird, um die Logik der Übersetzung zu verinnerlichen.
- Supervised Fine-Tuning: Das Modell wird mit hochwertigen, von Menschen erstellten Übersetzungen feinjustiert, um Genauigkeit und Stil zu verbessern.
- Reinforcement Learning (RL): Das Modell lernt durch Belohnung und Bestrafung. Es generiert Übersetzungen, die von einem anderen KI-System oder anhand von Metriken bewertet werden, und passt sich an, um bessere „Scores“ zu erzielen.
- Weak-to-Strong Reinforcement Learning: Eine innovative Technik, bei der ein stärkeres „Lehrer“-Modell einem schwächeren „Schüler“-Modell beibringt, bessere Ergebnisse zu erzielen. Dies hilft, die Fähigkeiten des Modells über die Qualität der ursprünglichen Trainingsdaten hinaus zu steigern.
Diese mehrstufige Strategie, insbesondere der Fokus auf MT-spezifisches Training und fortschrittliches RL, ist der Schlüssel zur herausragenden Leistung des Modells.
Eine Klasse für sich: Hunyuan-MT-Chimera-7B erklärt
Neben dem Basismodell hat Tencent auch Hunyuan-MT-Chimera-7B veröffentlicht, das als „branchenweit erstes quelloffenes integriertes Übersetzungsmodell“ bezeichnet wird.
Stell es dir wie einen intelligenten Chefredakteur vor:
- Es nimmt die Übersetzungsentwürfe von mehreren verschiedenen Modellen als Input.
- Es analysiert diese Entwürfe auf Stärken und Schwächen.
- Anschließend kombiniert, verfeinert und optimiert es die verschiedenen Versionen zu einer einzigen, überlegenen Übersetzung.
Dieser Ansatz ist besonders wertvoll für spezialisierte Anwendungsfälle (z.B. juristische oder medizinische Texte), wo höchste Präzision und Nuancierung gefordert sind.
Warum ein 7B-Modell die Spielregeln ändert
Die wahre Revolution von Hunyuan-MT-7B liegt nicht nur in seiner Leistung, sondern in seiner Effizienz. Ein schlankes 7B-Modell bietet massive Vorteile gegenüber den Giganten mit Billionen von Parametern:
- Kosteneffizienz: Der Betrieb (Inferenz) erfordert deutlich weniger teure GPU-Hardware.
- Geschwindigkeit: Es kann mehr Übersetzungsanfragen in kürzerer Zeit bearbeiten, was für Echtzeitanwendungen entscheidend ist.
- Flexibilität: Es kann nicht nur in der Cloud, sondern auch auf lokalen Servern oder sogar leistungsstarken Edge-Geräten (z.B. Laptops) bereitgestellt werden.
- Demokratisierung: Forscher, Start-ups und einzelne Entwickler können mit diesem Modell experimentieren und darauf aufbauen, ohne auf die Infrastruktur von Tech-Konzernen angewiesen zu sein.
Ausblick: Tencents KI-Offensive und die Open-Source-Bewegung
Die Veröffentlichung von Hunyuan-MT-7B ist kein Einzelfall. Sie ist Teil einer größeren Strategie von Tencent, sich als führende Kraft in der KI-Entwicklung zu etablieren. Modelle wie das kürzlich vorgestellte ARC-Hunyuan-Video-7B, ein Modell für strukturiertes Videoverständnis, zeigen, dass Tencent eine ganze Familie hochspezialisierter „Hunyuan“-Modelle aufbaut.
Dieser Schritt heizt auch den Wettbewerb in der Open-Source-Community weiter an. Modelle von DeepSeek, Qwen (Alibaba) und westliche Pendants wie Llama von Meta oder Grok von xAI treiben die Innovation in einem atemberaubenden Tempo voran. Für Anwender bedeutet das mehr Auswahl, bessere Leistung und niedrigere Kosten.
Tools & Ressourcen: Jetzt selbst loslegen
Tencent hat das Modell und die zugehörigen Ressourcen vollständig zugänglich gemacht:
- GitHub Repository: https://github.com/Tencent-Hunyuan/Hunyuan-MT/
- Technischer Bericht: https://github.com/Tencent-Hunyuan/Hunyuan-MT/blob/main/Hunyuan_MT_Technical_Report.pdf
- Hugging Face: https://huggingface.co/tencent/Hunyuan-MT-7B
- Offizielle Modell-Seite: https://hunyuan.tencent.com/modelSquare/home/list
Häufig gestellte Fragen zu Hunyuan-MT-7B
H2: Häufig gestellte Fragen zu Tencents Übersetzungs-KI
- Ist Hunyuan-MT-7B wirklich besser als GPT-4? In der spezifischen Disziplin der maschinellen Übersetzung zeigt es in Benchmarks wie WMT24app und bei Minderheitensprachen eine überlegene Leistung. GPT-4 ist ein Allzweckmodell mit Stärken in anderen Bereichen wie Logik und Kreativität. Für reine Übersetzungsaufgaben ist Hunyuan-MT-7B aktuell eine der besten Open-Source-Optionen.
- Was kostet die Nutzung von Hunyuan-MT-7B? Das Modell selbst ist Open-Source und kostenlos herunterladbar. Die Kosten entstehen durch die Hardware (Rechenleistung/GPUs), die für den Betrieb (Hosting/Inferenz) benötigt wird. Da es ein 7B-Modell ist, sind diese Kosten deutlich geringer als bei größeren Modellen.
- Welche Sprachen unterstützt das Modell? Es unterstützt insgesamt 33 Sprachen, darunter Hochfrequenzsprachen wie Chinesisch, Englisch und Japanisch, aber auch Sprachen mit geringeren Ressourcen wie Tschechisch, Marathi, Estnisch und Isländisch. Ein besonderer Fokus liegt auf der Übersetzung zwischen Mandarin und 5 Minderheitensprachen.
- Kann ich das Modell für kommerzielle Zwecke nutzen? Ja, das Modell wird unter einer Open-Source-Lizenz veröffentlicht, die in der Regel auch die kommerzielle Nutzung erlaubt. Es ist jedoch wichtig, die genauen Lizenzbedingungen im GitHub-Repository zu prüfen.
- Was ist der Unterschied zwischen Hunyuan-MT-7B und Hunyuan-MT-Chimera-7B? Hunyuan-MT-7B ist das Basis-Übersetzungsmodell. Hunyuan-MT-Chimera-7B ist ein „Meta-Modell“, das die Ergebnisse mehrerer anderer Modelle (einschließlich des Basismodells) analysiert und zu einer noch besseren Endversion kombiniert.
- Wie schneidet es im Vergleich zu Googles Übersetzer oder DeepL ab? Direkte Vergleiche mit kommerziellen Endprodukten wie Google Translate oder DeepL sind schwierig, da diese ständig aktualisiert werden und ihre internen Modelle nicht öffentlich sind. Die Benchmark-Ergebnisse deuten jedoch darauf hin, dass die Rohleistung von Hunyuan-MT-7B auf einem absolut konkurrenzfähigen Niveau liegt.
- Benötige ich spezielle Kenntnisse, um das Modell zu verwenden? Um das Modell selbst zu hosten und in eine Anwendung zu integrieren, sind Kenntnisse in Python und KI-Frameworks wie PyTorch erforderlich. Plattformen wie Hugging Face vereinfachen jedoch die Nutzung und das Experimentieren erheblich.
Praktische Anwendung: So integrierst Du Hunyuan-MT-7B in Dein Projekt
Theorie und Benchmarks sind das eine – doch wie kannst Du die Leistung von Hunyuan-MT-7B jetzt konkret für Dich nutzen? Dieser Abschnitt zeigt Dir, wie einfach der Einstieg ist, welche Anwendungsfälle besonders profitieren und welche typischen Fehler Du vermeiden solltest.
Schritt-für-Schritt-Anleitung: Deine erste Übersetzung in 5 Minuten
Dank der Integration in das Hugging Face Ökosystem kannst Du das Modell mit wenigen Zeilen Python-Code direkt ausprobieren.
Voraussetzungen: Du benötigst Python und die transformers-Bibliothek. Installiere sie einfach mit: pip install transformers torch sentencepiece
Python-Code für eine Test-Übersetzung (Englisch zu Deutsch):
Python
import torch
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# 1. Modell und Tokenizer laden
# HINWEIS: Prüfe auf Hugging Face den exakten Modellnamen für EN->DE Aufgaben
# Wir verwenden hier das Basismodell als Beispiel.
model_name = "tencent/Hunyuan-MT-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# 2. Den zu übersetzenden Text definieren
# Die Task-Präfixe können je nach Modell variieren, oft "translate English to German: "
text_to_translate = "translate English to German: The release of Hunyuan-MT-7B is a significant step for the open-source AI community, impressively demonstrating the power of specialized models."
# 3. Text in das für das Modell verständliche Format umwandeln (Tokenization)
inputs = tokenizer(text_to_translate, return_tensors="pt")
# 4. Die Übersetzung generieren
translation_ids = model.generate(**inputs, max_length=128)
# 5. Das Ergebnis zurück in lesbaren Text umwandeln (Decoding)
translated_text = tokenizer.batch_decode(translation_ids, skip_special_tokens=True)[0]
# 6. Ergebnis ausgeben
print("Original:", text_to_translate)
print("Übersetzung:", translated_text)
# Mögliche Ausgabe:
# Übersetzung: Die Veröffentlichung von Hunyuan-MT-7B ist ein bedeutender Schritt für die Open-Source-KI-Community und demonstriert eindrucksvoll die Leistungsfähigkeit spezialisierter Modelle.
Dieser Code-Schnipsel zeigt, wie unkompliziert Du das Modell laden und für eine Übersetzung nutzen kannst. Für andere Sprachpaare musst Du lediglich den Text und eventuell den Task-Präfix anpassen.
5 Konkrete Anwendungsfälle für Hunyuan-MT-7B
Die Effizienz und Qualität des Modells eröffnen zahlreiche Einsatzmöglichkeiten:
- Echtzeit-Übersetzung für Webseiten & E-Commerce: Integriere das Modell in dein Backend, um Produktbeschreibungen, Blogartikel oder Benutzeroberflächen „on the fly“ für internationale Besucher zu übersetzen. Die geringe Latenz des 7B-Modells ist hier ein entscheidender Vorteil.
- Sichere, interne Dokumentenverarbeitung: Große Unternehmen können das Modell auf eigenen Servern (On-Premise) betreiben. So können interne Berichte, E-Mails oder Schulungsunterlagen übersetzt werden, ohne sensible Daten an externe Cloud-Anbieter senden zu müssen.
- Mehrsprachige Community- und Support-Systeme: Trainiere oder integriere das Modell in Chatbots und Ticket-Systeme, um Kundensupport über Sprachgrenzen hinweg anzubieten und die Lösungszeit zu verkürzen.
- Automatisierte Untertitelung für Medieninhalte: Content Creator und Medienhäuser können das Modell nutzen, um Transkripte von Videos oder Podcasts schnell und kostengünstig in mehrere Sprachen zu übersetzen und so ihre globale Reichweite zu erhöhen.
- Akademische und journalistische Recherche: Forscher und Journalisten können große Mengen an fremdsprachigen Texten (z.B. Studien, Artikel, Social-Media-Posts) automatisiert übersetzen, um Muster und Informationen schneller zu analysieren.
Typische Fehler und wie Du sie vermeidest
| Fehler | Problem | Lösung |
| 1. Fehlender Kontext | Das Modell übersetzt isolierte Sätze oder Abschnitte und kann den übergeordneten Kontext eines Dokuments (z.B. Ironie, wiederkehrende Fachbegriffe) verlieren. | Gib dem Modell so viel Kontext wie möglich mit (z.B. längere Textabschnitte). Plane für kritische Texte eine menschliche Nachbearbeitung (Post-Editing) ein. |
| 2. „Garbage In, Garbage Out“ | Die Eingabe enthält Tippfehler, Slang, uneindeutige Formulierungen oder Formatierungsfehler (z.B. HTML-Tags), was zu schlechten Übersetzungen führt. | Bereinige und normalisiere Deine Eingabetexte vor der Übersetzung. Nutze Pre-Processing-Schritte, um den Text zu säubern. |
| 3. Ignorieren des Chimera-Modells | Für eine schnelle Übersetzung wird das Basismodell verwendet, obwohl für den Anwendungsfall (z.B. ein juristischer Vertrag) höchste Präzision nötig wäre. | Wähle das Modell basierend auf Deinem Anwendungsfall. Für maximale Qualität und Nuancierung, nutze Hunyuan-MT-Chimera-7B, auch wenn es etwas mehr Rechenleistung erfordert. |
| 4. Falsche Leistungserwartung | Die Erwartung ist, dass die KI eine 100% perfekte, stilistisch brillante Übersetzung liefert, die einen menschlichen Fachexperten vollständig ersetzt. | Verstehe KI-Übersetzung als ein extrem leistungsfähiges Werkzeug zur Effizienzsteigerung. Für finale, publikationsreife Texte ist ein menschlicher Review-Schritt oft unerlässlich (Human-in-the-Loop). |
Fazit: Ein Meilenstein für effiziente und offene KI
Hunyuan-MT-7B ist mehr als nur ein weiteres starkes Sprachmodell. Es ist ein eindrucksvoller Beweis dafür, dass die Zukunft der KI nicht allein den ressourcenhungrigen Riesenmodellen gehört. Durch intelligente Spezialisierung und innovative Trainingsmethoden hat Tencent ein Modell geschaffen, das in seiner Kerndisziplin die absolute Weltspitze darstellt – und das bei einem Bruchteil der Größe und Kosten. Der Sieg bei der WMT2025 ist keine Überraschung, sondern die logische Konsequenz dieser Strategie.
Die Entscheidung, dieses leistungsstarke Werkzeug als Open Source zur Verfügung zu stellen, ist ein enormer Gewinn für die gesamte Entwickler-Community. Sie senkt die Eintrittsbarrieren für die Schaffung hochwertiger, mehrsprachiger Anwendungen und wird die Innovation im Bereich der maschinellen Übersetzung zweifellos beschleunigen. Tencent hat nicht nur einen Wettbewerb gewonnen, sondern auch einen neuen Standard für die Effizienz von KI-Modellen gesetzt. Es wird spannend zu beobachten sein, wie die Konkurrenz auf diesen cleveren Schachzug reagieren wird.
Der nächste Schritt für dich? Wenn du in der Entwicklung tätig bist, lade das Modell von Hugging Face herunter und experimentiere. Wenn du einfach nur an der Zukunft der KI interessiert bist, behalte die „Hunyuan“-Familie im Auge. Hier entsteht gerade etwas Großes.
Quellen und weiterführende Literatur
- Hunyuan-MT Technical Report (Offiziell): https://github.com/Tencent-Hunyuan/Hunyuan-MT/blob/main/Hunyuan_MT_Technical_Report.pdf
- Tencent Hunyuan-MT GitHub Repository: https://github.com/Tencent-Hunyuan/Hunyuan-MT/
- Hugging Face Modell-Seite: https://huggingface.co/tencent/Hunyuan-MT-7B
- Geekflare News Article: https://geekflare.com/news/tencent-open-sources-hunyuan-mt-7b-after-big-win-at-wmt2025/
- ARC-Hunyuan-Video Technical Paper (Kontext): https://arxiv.org/html/2507.20939v1
- Conference on Machine Translation (WMT) Website: http://www.statmt.org/wmt25/
- FLORES-200 Benchmark Datensatz: https://github.com/facebookresearch/flores/tree/main/flores200
- X
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #HunyuanMT #Tencent #OpenSource #Tech2025 #MachineTranslation






