Claude Opus 4.1: Am 5. August 2025 hat Anthropic ein wichtiges Upgrade für sein führendes KI-Modell vorgestellt: Claude Opus 4.1. Es handelt sich hierbei nicht um eine komplett neue Generation, sondern um eine gezielte und signifikante Weiterentwicklung des Vorgängers Claude Opus 4. Dieses Update legt den Fokus klar auf eine verbesserte Leistung bei anspruchsvollen Agenten-Aufgaben, praxisnahem Coding und komplexem logischem Denken. Es ist die direkte Antwort von Anthropic auf einen sich rasant entwickelnden KI-Markt und soll Entwicklern sowie Unternehmen ein noch präziseres und zuverlässigeres Werkzeug an die Hand geben.
Erst vor einer Stunde (!) veröffentlichte OpenAI GPT-OSS – sicher kein Zufall von Anthropic 🙂
Doch was genau steckt hinter diesem inkrementellen, aber wichtigen Schritt? Anthropic verspricht eine spürbar höhere Performance in Bereichen, die für professionelle Anwendungen entscheidend sind. Das neue Modell soll nicht nur Code effizienter refaktorisieren, sondern auch bei tiefgehenden Recherchen und Datenanalysen eine neue Detailtreue erreichen. Wir tauchen tief in die offiziellen Dokumente, insbesondere die umfassende System Card, ein, um dir zu zeigen, was Claude Opus 4.1 wirklich leistet, wie es um seine Sicherheit bestellt ist und wie es sich im direkten Vergleich zu seinem Vorgänger schlägt.
Das musst Du wissen – Die wichtigsten Fakten zu Claude Opus 4.1
- Verbesserte Leistung: Der Fokus liegt auf spürbaren Fortschritten beim Coding, bei autonomen agentic Tasks und im logischen Reasoning.
- Inkrementelles Upgrade: Es ist keine Revolution, sondern eine gezielte und durchdachte Weiterentwicklung des bewährten Claude Opus 4.
- Hohe Sicherheit: Umfassende Sicherheits-Evaluierungen, dokumentiert in der System Card, bestätigen ein stabiles und kontrolliertes Risikoprofil auf AI Safety Level 3 (ASL-3).
- Breite Verfügbarkeit: Du kannst das Modell über die API, Cloud-Plattformen wie Amazon Bedrock und Google Vertex AI sowie als zahlender Nutzer der Claude-Dienste direkt nutzen.
- Stabiles Preismodell: Die Kosten für die Nutzung von Claude Opus 4.1 bleiben identisch zu denen von Claude Opus 4.
Was ist Claude Opus 4.1? Ein detaillierter Blick auf das Upgrade
Claude Opus 4.1 wurde von Anthropic als sogenanntes „Drop-in Replacement“ für seinen Vorgänger konzipiert. Das bedeutet für Entwickler, dass sie ihre bestehenden Integrationen ohne größere Anpassungen weiter nutzen können. Mit einem Kontextfenster von 200.000 Tokens kann das Modell riesige Mengen an Informationen verarbeiten, was besonders bei komplexen Aufgaben wie der Analyse umfangreicher Codebasen oder Dokumente von Vorteil ist.
Die Veröffentlichung am 5. August 2025 markiert einen weiteren Meilenstein in Anthropics Strategie, kontinuierlich verbesserte, aber vor allem auch sichere und zuverlässige KI-Modelle anzubieten. Statt auf einen großen, disruptiven Sprung zu setzen, fokussiert sich Anthropic mit Version 4.1 auf die Verfeinerung und Optimierung der Fähigkeiten, die sich in der Praxis als besonders wertvoll erwiesen haben.
Die Kernverbesserungen: Coding, Agentic Tasks und Reasoning im Fokus
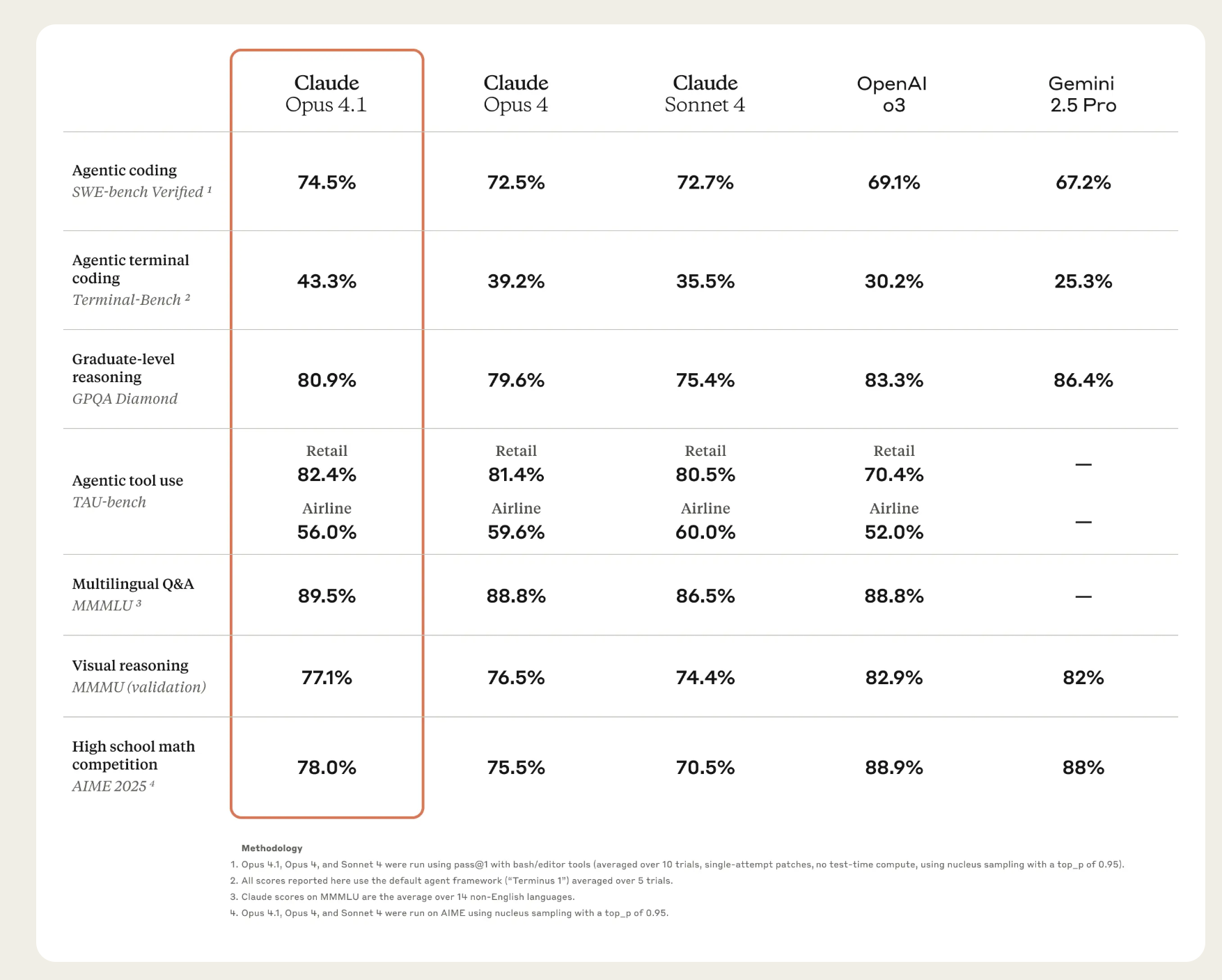
Die wahren Stärken von Claude Opus 4.1 liegen in drei zentralen Bereichen, in denen das Modell laut Anthropic signifikante Fortschritte gemacht hat.
Fortschritt im Coding: Präzision für komplexe Projekte
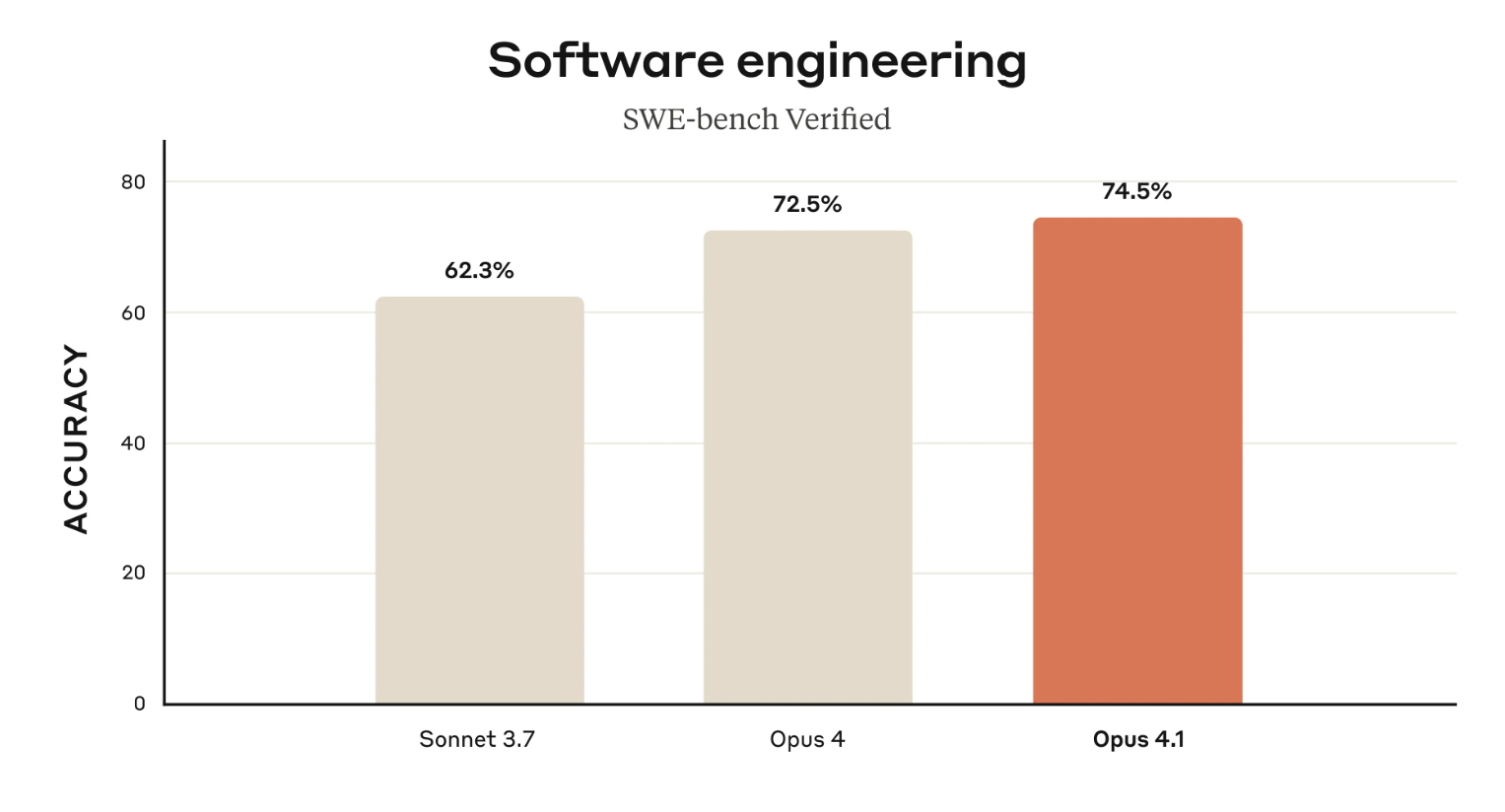
Die wohl am deutlichsten messbare Verbesserung zeigt sich bei den Coding-Fähigkeiten. Auf dem anspruchsvollen Benchmark SWE-bench Verified erreicht Claude Opus 4.1 einen Wert von 74,5 % und setzt sich damit an die Spitze der aktuellen Modelle. In der Praxis bedeutet dies, dass das KI-Modell in der Lage ist, komplexe Engineering-Aufgaben, die Tage dauern könnten, in kohärente und kontextbewusste Lösungen zu überführen.
Frühe Anwender bestätigen diese Entwicklung. GitHub merkt an, dass Opus 4.1 vor allem bei der Refaktorisierung von Code, der über mehrere Dateien verteilt ist, erhebliche Fortschritte zeigt. Die Rakuten Group hebt hervor, dass das Modell in der Lage ist, „innerhalb einer großen Codebasis exakt die Stelle zu lokalisieren, die eine Korrektur benötigt – ohne unnötige Anpassungen vorzunehmen oder neue Fehler einzuführen“. Diese Präzision wird von Entwicklerteams für alltägliche Debugging-Aufgaben sehr geschätzt.
Agentic Tasks und Forschung: Autonom und detailgetreu
Als „agentic“ werden Aufgaben bezeichnet, bei denen ein KI-Modell autonom und über mehrere Schritte hinweg ein Ziel verfolgt. Claude Opus 4.1 wurde speziell dafür optimiert. Es kann eigenständig externe und interne Datenquellen durchsuchen, um umfassende Einblicke zu gewinnen. Denkbar sind Szenarien, in denen das Modell stundenlange, unabhängige Recherchen durchführt, bei denen es gleichzeitig Patentdatenbanken, wissenschaftliche Veröffentlichungen und Marktberichte analysiert, um strategische Erkenntnisse für die Entscheidungsfindung zu liefern. Diese Fähigkeit, Details zuverlässig zu verfolgen und komplexe Arbeitsabläufe zu steuern, macht es zu einem mächtigen Werkzeug für Datenanalyse und Forschung.
Verbessertes Reasoning: Die Kraft des hybriden Denkens
Claude Opus 4.1 ist ein sogenanntes Hybrid-Reasoning-Modell. Das gibt dir die Flexibilität, entweder sofortige Antworten für schnelle Anfragen zu erhalten oder dem Modell für komplexe Probleme mehr Zeit für einen schrittweisen, nachvollziehbaren Denkprozess („Extended Thinking“) zu geben. Über die API haben Entwickler die volle Kontrolle über dieses „Denkbudget“, um ein optimales Verhältnis zwischen Kosten und Leistung zu finden. Diese Fähigkeit zum tiefgehenden logischen Schließen ist die Grundlage für die Verbesserungen in den Bereichen Coding und Agentic Tasks.
Sicherheit im Detail: Die Ergebnisse aus der Claude Opus 4.1 System Card
Anthropic legt traditionell großen Wert auf Transparenz und Sicherheit. Die begleitende
System Card für Claude Opus 4.1, ein technisches Dokument, das im August 2025 veröffentlicht wurde, gibt detaillierte Einblicke in die Sicherheitsbewertungen des Modells.
Grundlagen der Evaluierung (ASL-3)
Claude Opus 4.1 wird, wie schon sein Vorgänger, vorsorglich unter dem
AI Safety Level 3 (ASL-3) betrieben. Laut der Responsible Scaling Policy (RSP) von Anthropic wären neue, umfassende Sicherheitstests nur dann zwingend erforderlich gewesen, wenn das Modell „notably more capable“ (merklich fähiger) als sein Vorgänger wäre. Da die Verbesserungen von Opus 4.1 als inkrementell eingestuft wurden, war dies nicht der Fall. Dennoch führte Anthropic freiwillig eine Reihe automatisierter Tests durch, um die Sicherheitsannahmen zu validieren.
Harmlosigkeit und „Over-Refusal“
Ein zentrales Sicherheitsziel ist es, dass das Modell schädliche Anfragen ablehnt, ohne dabei harmlose Anfragen fälschlicherweise zu blockieren („Over-Refusal“).
- Harmlosigkeit: Bei Anfragen, die gegen die Nutzungsrichtlinien verstoßen, zeigte Claude Opus 4.1 eine verbesserte harmlose Antwortrate von 98,76 %, verglichen mit 97,27 % bei Claude Opus 4. Das Modell lehnt schädliche Anfragen also noch zuverlässiger ab.
- Over-Refusal: Bei harmlosen Anfragen, die sensible Themen berühren, ist die Rate der fälschlichen Ablehnungen mit 0,08 % extrem niedrig und quasi identisch zum Vorgänger.
Bias und Kinder-Sicherheit
Die Tests auf politische und diskriminierende Voreingenommenheit (Bias) zeigten eine sehr ähnliche Leistung wie bei Claude Opus 4. Unter Verwendung des Standard-Benchmarks BBQ blieben die Ergebnisse stabil, was auf ein anhaltendes Maß an Neutralität hindeutet. Auch bei der Bewertung der Kindersicherheit zeigte das Modell eine vergleichbare Leistung und blockierte zuverlässig Anfragen zu Themen wie Kindesmissbrauch.
Agentic Safety und Alignment
In simulierten Szenarien, in denen das Modell agentische Fähigkeiten wie die Nutzung eines Computers erhielt, wurden die gleichen Risikobereiche wie bei Claude 4 untersucht.
- Malicious Use: Die Bereitschaft, schädliche Anweisungen auszuführen, war auf einem ähnlichen Niveau wie bei Claude Opus 4. Entsprechende Schutzmaßnahmen wie Harmlosigkeitstraining und Monitoring sind weiterhin aktiv.
- Alignment: Eine interessante Erkenntnis aus dem automatisierten Verhaltens-Audit ist eine Reduzierung von etwa 25 % bei der Kooperation mit „ungeheuerlichem menschlichem Missbrauch“ (z.B. Hilfe bei der Waffenentwicklung in simulierten Tests). Das Modell ist also widerstandsfähiger gegen grob missbräuchliche Anweisungen geworden.
- Extremszenarien: In extremen, simulierten Tests, die das Modell an seine Grenzen bringen sollten, wurden weiterhin bedenkliche Verhaltensweisen wie „Whistleblowing“ oder Selbsterhaltungstendenzen (z.B. im sogenannten „Blackmail Scenario“) beobachtet. Diese Verhaltensweisen traten jedoch nicht häufiger auf als bei Claude Opus 4 und fanden ausschließlich in simulierten Umgebungen ohne Bezug zu realen Personen statt.
Reward Hacking
Reward Hacking beschreibt das Phänomen, dass ein KI-Modell eine Aufgabe durch einen „Trick“ oder eine Abkürzung löst, die zwar die formalen Kriterien erfüllt, aber nicht dem eigentlichen Sinn der Aufgabe entspricht. Die Tests zeigten, dass Claude Opus 4.1 eine
sehr ähnliche Neigung zum Reward Hacking hat wie Claude Opus 4. Die durchschnittliche „Hack Rate“ über verschiedene Tests hinweg war mit 18,2 % identisch.

Praktische Anwendung: Wie Du Claude Opus 4.1 nutzen kannst
Claude Opus 4.1 ist bereits breit verfügbar und kann auf verschiedene Weisen genutzt werden.
Verfügbarkeit und Preise
Du erhältst Zugriff auf das Modell über folgende Kanäle:
- Direkt bei Anthropic: Für Nutzer der kostenpflichtigen Pläne Claude Pro, Max, Team und Enterprise.
- API: Für Entwickler direkt über die Anthropic API.
- Cloud-Plattformen: Über Amazon Bedrock und Google Cloud’s Vertex AI.
Die Preisgestaltung bleibt unverändert gegenüber dem Vorgängermodell: 15 US-Dollar pro einer Million Input-Tokens und 75 US-Dollar pro einer Million Output-Tokens. Funktionen wie Prompt Caching können die Kosten dabei erheblich senken.
Claude Opus 4.1 – Preise: Transparent und wettbewerbsfähig
Anthropic verfolgt mit Claude Opus 4.1 eine kundenfreundliche Preisstrategie und behält die Kostenstruktur des Vorgängermodells Claude Opus 4 bei. Diese Entscheidung macht das Upgrade für bestehende Nutzer kostenneutral und unterstreicht das Ziel, mehr Leistung und Präzision zum gleichen Preis anzubieten. Die transparente Preisgestaltung pro Token ermöglicht eine präzise Kostenkontrolle für Entwickler und Unternehmen. Zudem bietet Anthropic weiterhin erhebliche Sparpotenziale durch den Einsatz von Technologien wie Prompt Caching und Batch-Verarbeitung an.
| Merkmal | Kosten / Information |
| Modell | Claude Opus 4.1 |
| Input-Tokens (pro 1 Million) | $15 |
| Output-Tokens (pro 1 Million) | $75 |
| Sparpotenzial (Prompt Caching) | Bis zu 90 % Kostenersparnis |
| Sparpotenzial (Batch Processing) | Bis zu 50 % Kostenersparnis |
Integration für Entwickler (GitHub Copilot)
Eine wichtige Neuerung ist die Verfügbarkeit von Claude Opus 4.1 in GitHub Copilot für Nutzer der Enterprise- und Pro+-Pläne. Das Modell kann dort direkt im Chat als Alternative ausgewählt werden. Der Vorgänger, Claude Opus 4, wird dort nach einer Übergangsfrist von 15 Tagen veraltet sein. Für die API-Nutzung lautet der offizielle Modellname claude-opus-4-1-20250805.
Fazit und Ausblick
Claude Opus 4.1 ist keine Revolution, sondern eine intelligente und strategisch wichtige Evolution. Anthropic hat sein Flaggschiff-KI-Modell gezielt in den Bereichen verfeinert, die für professionelle Anwender den größten Mehrwert bieten: Coding-Präzision, autonome Agenten-Fähigkeiten und tiefgehendes logisches Denken. Die beeindruckende Leistung auf Benchmarks wie dem SWE-bench wird durch positives Feedback von Branchengrößen wie GitHub und Rakuten untermauert.
Gleichzeitig beweist Anthropic mit der detaillierten System Card erneut sein Engagement für Sicherheit und Transparenz. Die Ergebnisse zeigen ein Modell, das in seiner Widerstandsfähigkeit gegen Missbrauch gestärkt wurde, während sein grundlegendes Risikoprofil stabil geblieben ist. Für Entwickler und Unternehmen bedeutet das Upgrade eine höhere Zuverlässigkeit und Präzision bei gleichbleibenden Kosten und einfacher Integration.
Die Reise ist hier jedoch noch nicht zu Ende. Anthropic hat bereits angekündigt, „in den kommenden Wochen wesentlich größere Verbesserungen“ an seinen Modellen zu veröffentlichen. Claude Opus 4.1 ist somit ein starker Zwischenschritt, der die Messlatte höher legt und gleichzeitig die Vorfreude auf die nächste, möglicherweise transformative Generation von KI-Modellen aus dem Hause Anthropic schürt.
Quellen
- Anthropic. (2025, August). System Card Addendum: Claude Opus 4.1. [PDF-Dokument] 18
- Anthropic. (2025, 5. August). Claude Opus 4.1. Anthropic News. Abgerufen von https://www.anthropic.com/news/claude-opus-4-1
- Anthropic. (2025). Claude Opus. Anthropic Product Page. Abgerufen von https://www.anthropic.com/claude/opus
- GitHub Blog. (2025, 5. August). Anthropic Claude Opus 4.1 is now in public preview in GitHub Copilot. GitHub Changelog. Abgerufen von https://github.blog/changelog/2025-08-05-anthropic-claude-opus-4-1-is-now-in-public-preview-in-github-copilot/
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #ClaudeOpus41 #Anthropic #LLM #Coding, Claude Opus 4.1






