
Allen Institute for AI veröffentlicht Dolma:
Künstliche Intelligenz ist eines der spannendsten Forschungsfelder unserer Zeit. Insbesondere große Sprachmodelle auf Basis neuronaler Netze haben in den letzten Jahren enorme Fortschritte gemacht. Damit diese Entwicklung weitergehen kann, benötigen die Modelle riesige Mengen an Trainingsdaten.
Um hier mehr Transparenz und offene Forschung zu ermöglichen, hat das Allen Institute for AI jetzt mit “Dolma” das bisher größte öffentlich zugängliche Text-Dataset vorgestellt. Der amüsante Name ist dabei ein Wortspiel und steht für “Data to feed OLMo’s Appetite“, also Daten, um den Hunger von OLMo zu stillen.
OLMo ist das hauseigene Open Language Model des Instituts, das mit Hilfe von Dolma trainiert werden soll. In diesem Artikel wird die Entstehung von Dolma detailliert dokumentiert. Es gibt einen Überblick über die Design-Entscheidungen und Verarbeitungsschritte. Zudem wird Dolma mit anderen Datensätzen verglichen, die Entstehung transparent gemacht und die Veröffentlichung unter einer Open Source Lizenz erläutert.
Insgesamt zeigt Dolma, wie wichtig der verantwortungsvolle Umgang mit großen Mengen von Trainingsdaten für Fortschritte in der KI-Forschung ist. Nur auf Basis ethischer Prinzipien wie Offenheit und Nachvollziehbarkeit kann eine positive Zukunft mit KI gestaltet werden.
Das Allen Institute for AI hat Dolma veröffentlicht, ein offenes Corpus von 3 Billionen Tokens für das Vortraining von Sprachmodellen. Das Corpus ist das bisher größte frei verfügbare Dataset dieser Art.
Warum Dolma für die Forschung so bedeutend ist
Die Veröffentlichung von Dolma durch das Allen Institute for AI ist ein wichtiger Schritt für die Forschung im Bereich der großen Sprachmodelle:
- Durch die Freigabe eines so umfangreichen Text-Datasets ermöglicht das Institut vielen Forschenden, eigene Modelle in dieser Größenordnung zu trainieren und zu untersuchen. Bisher waren die dafür nötigen Trainingsdaten nur wenigen großen Firmen zugänglich.
- Da Dolma unter einer Open Source Lizenz steht, können Forschende den Datensatz nicht nur verwenden, sondern auch verbessern, erweitern und anpassen. Dies fördert Innovation und technologischen Fortschritt.
- Die detaillierte Dokumentation der Erstellung von Dolma schafft Transparenz. Andere können den Prozess nachvollziehen und von den gesammelten Erfahrungen profitieren. Dies beschleunigt die Entwicklung in diesem Bereich.
- Durch den offenen Zugang zu Datensatz und Modellen basierend auf Dolma wird es möglich, diese umfangreich zu analysieren und Verbesserungspotenziale zu identifizieren. Auch ethische Fragestellungen rund um große LMs können so besser untersucht werden.
- Insgesamt setzt die Veröffentlichung von Dolma einen neuen Standard für Offenheit und Transparenz in der LM-Forschung. Sie ermöglicht breiten Fortschritt auf Basis gemeinsamen Wissens.
Damit leistet das Allen Institute for AI einen essenziellen Beitrag auf dem Weg zu verantwortungsvoller und gemeinwohlorientierter KI-Forschung.
Hintergrund und Ziele
Seit März arbeitet AI2 an OLMo, einem offenen Sprachmodell zur Förderung der Forschung im Bereich großer NLP-Systeme. Ein Hauptziel ist es, OLMo auf transparente und offene Weise zu entwickeln.
Mit der Veröffentlichung von Dolma soll anderen Forschern ermöglicht werden, bessere Versionen des Datasets zu erstellen, die Beziehung zwischen Daten und trainierten Modellen zu untersuchen und Probleme in den Daten zu melden. Offene Daten sind auch wichtig für Forschung zur Attribution von Modellausgaben.
Inhalt und Kuratierung
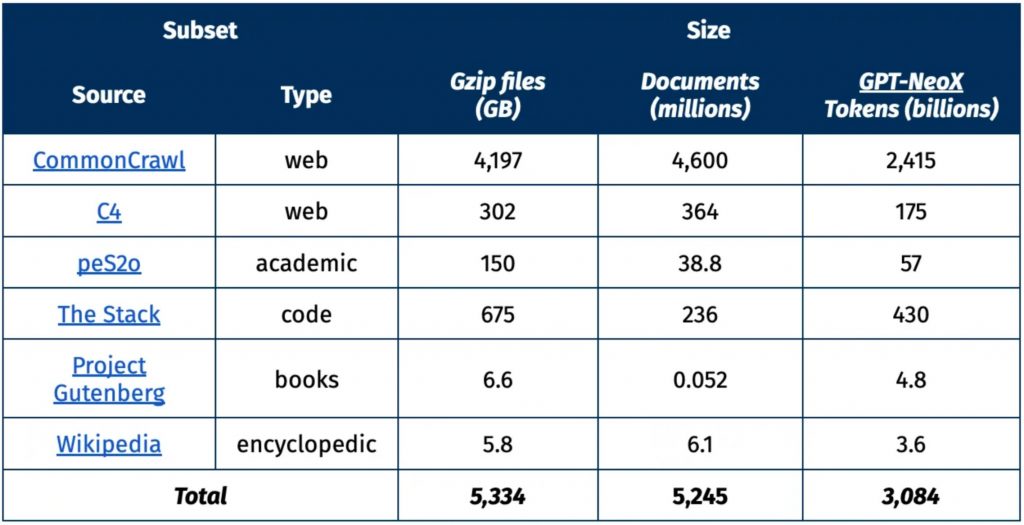
Dolma enthält:
Web-Inhalte
- Diverse Inhalte aus dem Web, z.B. Nachrichten, Blogs, Foren
Akademische Publikationen
- Wissenschaftliche Paper aus verschiedenen Disziplinen
Code
- Quellcode aus Open Source Projekten
Bücher
- Volltexte von frei verfügbaren Büchern, z.B. von Project Gutenberg
Enzyklopädische Inhalte
- Artikel aus Wikipedia und Wikidata
Bei der Kuratierung folgte AI2 etablierten Verfahren für die Erstellung von Trainingsdaten. Gleichzeitig wurde auf Risikominimierung geachtet, z.B. in Bezug auf persönliche Informationen.
Vergleich mit anderen Datasets
Mit 3 Billionen Tokens ist Dolma deutlich größer als bisher frei verfügbare Corpora:
- Pile: 0.8 Billionen Tokens
- C4: 0.8 Billionen Tokens
- OpenWebText2: 38 Milliarden Tokens
Nur die trainingsdaten großer Tech-Konzerne sind größer, aber nicht öffentlich verfügbar. Dolma ist daher das aktuell größte frei zugängliche Corpus für das LM-Vortraining.
Verwendung und Verfügbarkeit
Dolma steht unter der Impact-Lizenz von AI2 auf dem HuggingFace Hub zum Download bereit. Es kann für akademische Zwecke sowie von Non-Profit-Organisationen genutzt werden. Eine kommerzielle Nutzung ist nicht gestattet.
Erstellung von Dolma
Die Erstellung von Dolma umfasst die Transformation von Rohdaten aus verschiedenen Quellen in bereinigte plain-text Dokumente. Dabei gibt es zwei Kategorien von Verarbeitungsschritten:
Quellenspezifische Verarbeitung
Jede Datenquelle hat ihre eigenen Besonderheiten, die bei der Verarbeitung berücksichtigt werden müssen. Beispielsweise macht das Filtern von Dateien basierend auf ihrer Software-Lizenz nur bei Code Sinn.
Quellenübergreifende Verarbeitung
Oft möchte man die gleichen Verarbeitungsschritte auf mehrere Datenquellen anwenden, z.B. das Entfernen von persönlichen Informationen oder die Dekontaminierung gegenüber einem Evaluierungs-Set.
Insgesamt ergibt sich so eine Pipeline mit einer Kombination aus quellenspezifischen und -übergreifenden Transformationen. Im Folgenden die Pipelines für zwei Quellen: Webdaten aus Common Crawl und Code von Stack Overflow.
Wichtige Verarbeitungsschritte
Hier eine Zusammenfassung einiger besonders wichtiger Verarbeitungsschritte:
Nur Englisch
- Dolma enthält zunächst nur englischen Text, da die meiste LM-Forschung sich auf Englisch fokussiert
- Language Identification mit FastText, relativ großzügiger Schwellenwert um Dialekt-Biases zu vermeiden
Webdaten
- Webtexte sind trotz Limitationen zentral für viele LMs, daher auch in Dolma enthalten
- Herkunft: 24 Common Crawl Snapshots von 05/2020 bis 06/2023 plus C4-Dataset
- Umwandlung in Plain Text mit CCNet Pipeline und anschließende Qualitätsfilterung
Deduplizierung
- Entfernen von Duplikaten verbessert Lern-Effizienz
- Zweistufig: Innerhalb von Quellen auf Dokumentebene, dann innerhalb von Dokumenten auf Absatzebene
- Implementierung mit Bloom Filter
Risikominimierung
- Möglichst wenig schädigende oder persönliche Inhalte
- Kombination aus Klassifizierung und Regulären Ausdrücken, sehr restriktive Schwellenwerte
- Bester Umgang ist noch Forschungsfrage, Community-Standards entwickeln sich weiter
Code
- Ca. 10% Code gemischt unter Text verbessert LM-Leistung
- Quelle: The Stack, nur permissiv lizenzierter GitHub-Code
- Heuristiken aus Gopher, RedPajama etc. zum Filtern ungeeigneter Code-Dateien
Diverse Quellen
- Verschiedene Textsorten sind wichtig, z.B. wissenschaftliche Texte
- Enthalten: Wikipedia, Project Gutenberg, wissenschaftliche Papers (peS2o)
Dekontaminierung
- Entfernen von Eval-Daten aus Trainingskorpus vermeidet künstliche Leistungssteigerung
- Mit Bloom Filter nach doppelten Absätzen zwischen Trainings- und Evaluierungsdaten gesucht
- Weniger als 0.001% der Daten davon betroffen
Die Erstellung von Dolma folgt etablierten Verfahren, berücksichtigt aber auch neuere Erkenntnisse zur effizienten LM-Vorbereitung. Durch die Offenlegung können andere Forschende den Prozess reproduzieren und kritisch untersuchen.
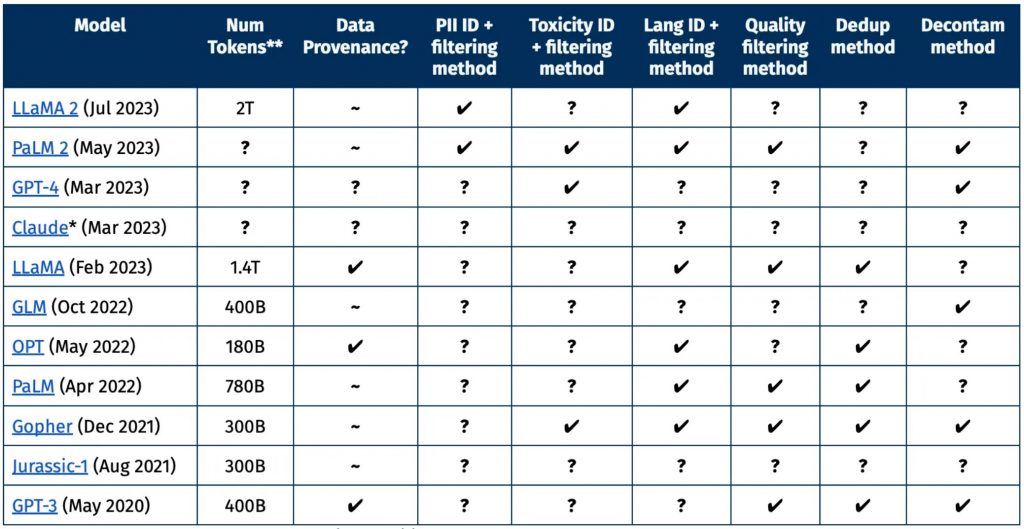
Vergleich mit geschlossenen Datensätzen
Viele große Sprachmodelle wurden auf nicht-öffentlichen Datensätzen trainiert. Oftmals gibt es wenig Transparenz über die Datenkuration. Um dies zu verdeutlichen, zeigt die folgende Tabelle einen Vergleich mit geschlossenen Datensätzen und Sprachmodellen im Bereich von 65+ Milliarden Parametern.
Daraus wird deutlich, dass viele Details zur Datenaufbereitung nicht offengelegt werden. Dies erschwert wissenschaftlichen Vergleiche und eine kritische Betrachtung der Trainingsdaten.
Bei der Erstellung von Dolma diente dieser eingeschränkte Einblick als Orientierung, um gängige Verfahren für einen repräsentativen Datensatz zu identifizieren und nachzubilden.
Vergleich mit anderen offenen Datensätzen
Im Gegensatz zu den oben genannten geschlossenen Datensätzen sind die in der folgenden Tabelle aufgeführten Corpora öffentlich zugänglich. Der Vergleich zeigt Gemeinsamkeiten wie die Nutzung von Web-Crawl-Daten und den Fokus auf Englisch. Es gibt aber auch Unterschiede, z.B. bei Risikominimierung oder Lizenzen.
Dolma unterscheidet sich durch seine Größe von über 3 Billionen Tokens und die Impact-Lizenz, die Zugang mit Risikominimierung verbindet.
Veröffentlichung von Dolma
Dolma wird unter der Impact-Lizenz von AI2 als mittelriskantes Artefakt bereitgestellt. Nutzer müssen u.a.:
- Kontaktdaten und Verwendungszweck angeben
- Derivate offenlegen und ebenfalls unter Impact lizenzieren
- Verbotene Anwendungen wie Überwachung oder Desinformation ausschließen
Die Lizenz verbindet offenen Zugang mit dem Ziel, Risiken zu vermeiden. Interessierte sollten die Lizenzbedingungen vor der Nutzung sorgfältig prüfen.
Mit Dolma setzt AI2 einen neuen Standard für offene Sprachmodell-Trainingsdaten. Die Größe und Lizenz ermöglichen breiten Zugang unter Berücksichtigung potenzieller Risiken.
Beitragende zur Erstellung und Dokumentation von Dolma, alphabetisch sortiert:
Aakanksha Naik, Abhilasha Ravichander, Akshita Bhagia, Dirk Groeneveld, Dustin Schwenk, Emma Strubell, Evan Pete Walsh, Hannaneh Hajishirzi, Ian Magnusson, Iz Beltagy, Jesse Dodge, Khyathi Chandu, Kyle Lo, Li Lucy, Luca Soldaini, Luke Zettlemoyer, Matt Peters, Nishant Subramani, Noah A. Smith, Oyvind Tafjord, Rodney Kinney, Russell Authur, Zejiang Shen
Fazit
Mit der Veröffentlichung von Dolma setzt das Allen Institute for Artificial Intelligence einen wichtigen Meilenstein in der Forschung an großen Sprachmodellen. Der umfangreiche Datensatz aus 3 Billionen Text-Token ermöglicht es Wissenschaftlern weltweit, eigene Modelle dieser Größenordnung zu trainieren und zu analysieren.
Bisher waren die benötigten riesigen Mengen an Trainingsdaten nur wenigen Unternehmen zugänglich. Durch den offenen Zugang zu Dolma wird die Entwicklung nun deutlich beschleunigt und breiter gestreut. Jeder kann auf Basis dieses Fundaments mitarbeiten, Innovationen vorantreiben und so unser Gesamtverständnis großer Sprachmodelle erweitern.
Die sorgfältige Dokumentation des Entstehungsprozesses schafft Transparenz und Nachvollziehbarkeit. Dolma zeigt, wie wichtig verantwortungsvoller Umgang mit Daten und technische Exzellenz Hand in Hand gehen müssen. Nur so kann künstliche Intelligenz unsere Gesellschaft positiv gestalten.
Die Veröffentlichung dieses richtungsweisenden Datensatzes ist ein großer Schritt auf dem Weg zu einer Zukunft, in der KI-Systeme allen Menschen dienen. Das Allen Institute hat mit Dolma demonstriert, dass Offenheit und Gemeinwohlorientierung der einzig gangbare Weg sind, um dieses Ziel zu erreichen.
Quellen: Allen Blog, Lizenz, DOLMA Datasheet,
#KI #ai #offenescorpus #3billionentokens #transparenz #reproduzierbarkeit #nlp #lm