
Großartige Neuigkeiten aus der Welt der KI-gestützten Suche! Die Perplexity Sonar Modelle haben kürzlich für Furore gesorgt, indem sie nicht nur einen Spitzenplatz, sondern gleich die vordersten Ränge in der renommierten LM Search Arena Evaluation erobert haben. Diese Bewertung, die auf echten Nutzerpräferenzen basiert, zeigt, wie gut KI-Modelle tatsächlich bei Suchanfragen abschneiden. Dass Perplexity Sonar hier nicht nur mithält, sondern dominiert, ist ein starkes Signal für die Qualität der KI Suche von Perplexity.
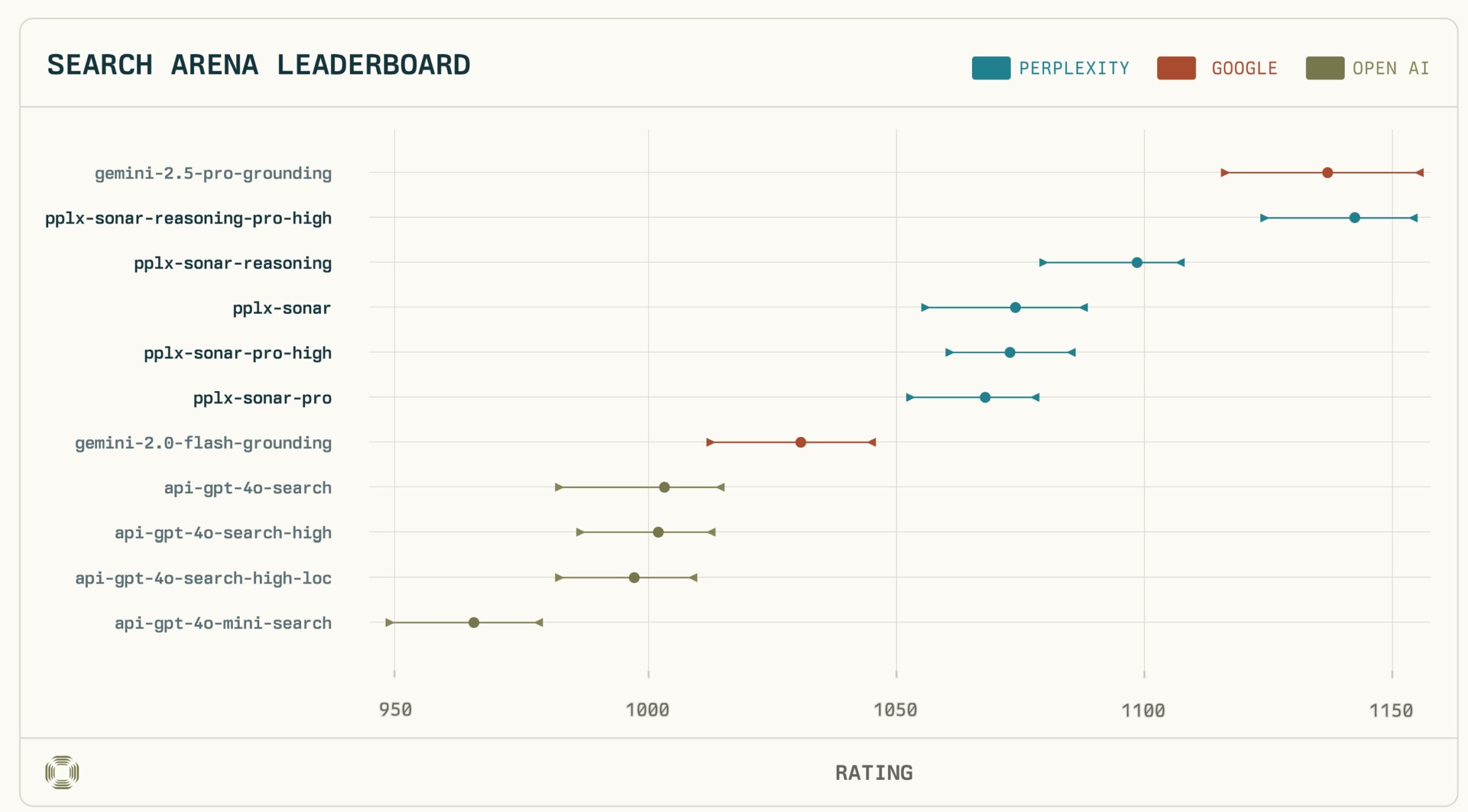
Das Top-Modell Sonar-Reasoning-Pro-High teilt sich statistisch gesehen den ersten Platz mit Googles Gemini-2.5-Pro-Grounding – ein beeindruckendes Ergebnis. Noch bemerkenswerter: Perplexity-Modelle sicherten sich die Ränge 1 bis 4 und übertrafen damit andere evaluierte Modelle von Google und OpenAI deutlich. In direkten Vergleichen konnte Sonar-Reasoning-Pro-High das Google-Modell sogar in 53% der Fälle schlagen.
Was steckt hinter diesem Erfolg? Die Analyse der LM Search Arena zeigt klare Präferenzen für Modelle, die umfassende Antworten liefern, viele hochwertige Quellen zitieren und über „Reasoning“-Fähigkeiten verfügen. Perplexity Sonar scheint genau diese Kriterien hervorragend zu erfüllen. Wenn du mehr darüber erfahren möchtest, wie Perplexity die KI Suche neu definiert, was die Benchmarks genau aussagen und wie du die leistungsstarke Search API nutzen kannst (inklusive Preisübersicht), bist du hier genau richtig.
Das musst Du wissen – Perplexity Sonar Highlights (Aktualisiert)
- Geteilter Platz 1: Perplexity Sonar-Reasoning-Pro-High (Score 1136 ±21/−19) teilt sich statistisch den ersten Platz in der LM Search Arena mit Google Gemini-2.5-Pro-Grounding (Score 1142 +14/-17).
- Klare Dominanz: Perplexity-Modelle belegen die Ränge 1 bis 4 und übertreffen damit Gemini 2.0 Flash sowie alle GPT-4o-Suchmodelle von OpenAI in dieser Evaluation.
- Nutzerfokus im Benchmark: Die LM Search Arena (über 10.000 Votes, 11 Modelle, März/April 2025) bewertet Leistung bei realen, komplexen Anfragen (Coding, Recherche etc.) basierend auf menschlichen Präferenzen.
- Erfolgsfaktoren: Nutzer bevorzugen längere Antworten, höhere Zitatanzahl (Sonar zitiert 2-3x mehr Quellen als Gemini) und Zitate aus Community-Quellen – alles Stärken von Sonar.
- Reasoning zählt: Modelle mit expliziten Reasoning-Fähigkeiten (wie Sonar-Reasoning-Pro und Sonar-Reasoning) wurden von Nutzern bevorzugt und belegen Top-3-Positionen.
- API & Preise: Die Search API bietet flexible Modi; Preise für Sonar-Modelle sind oft deutlich günstiger als Konkurrenz (siehe Tabelle). Webinar dazu fand am 24. April statt.
LM Search Arena – Der anspruchsvolle Praxistest für KI-Suche
Benchmarks sind essenziell, um die Flut an neuen KI-Modellen einordnen zu können. Die LM Search Arena, betrieben von LM Arena (bekannt für Chatbot-Vergleiche), hebt sich dabei besonders hervor. Anders als Tests wie SimpleQA, die sich oft auf enge, faktenbasierte Fragen konzentrieren, simuliert die Search Arena die reale Nutzung von KI Suche viel genauer.
Zwischen dem 18. März und dem 13. April 2025 wurden über 10.000 menschliche Präferenzurteile für 11 verschiedene suchgestützte Sprachmodelle gesammelt. Die Nutzer stellten dabei typische, oft längere und komplexere Anfragen aus Bereichen wie Coding, Schreiben, Recherche oder Produktempfehlungen. Ein besonderer Fokus lag auch auf aktuellen Ereignissen, bei denen die Fähigkeit zur Integration neuester Informationen entscheidend ist. Die zentrale Frage war stets: Welche der beiden (anonym präsentierten) Antworten erfüllt Deine Informationsbedürfnisse besser?
In diesem anspruchsvollen und praxisnahen Umfeld haben die Perplexity Sonar Modelle auf ganzer Linie überzeugt:
- Geteilte Führung: Sonar-Reasoning-Pro-High erreichte einen Arena Score von 1136 (mit einer Unsicherheit von +21/-19 Punkten), was statistisch einem Gleichstand mit Google Gemini-2.5-Pro-Grounding (Score 1142, +14/-17) entspricht. Die leichte Punktedifferenz liegt innerhalb der statistischen Fehlermargen. Der 53%-Sieg in direkten Duellen untermauert die Ebenbürtigkeit bzw. leichte Präferenz für Sonar.
- Dominanz im Spitzenfeld: Besonders beeindruckend ist die Breite der Spitzenleistung: Die Ränge 1 bis 4 wurden allesamt von Perplexity-Modellen belegt. Das bedeutet, dass nicht nur das Top-Modell, sondern die gesamte Sonar-Familie (inklusive Sonar-Reasoning, Sonar-Pro-High und Sonar-Pro) die Konkurrenz von Google (Gemini 2.0 Flash Grounding landete weiter hinten) und OpenAI (alle getesteten GPT-4o Search Varianten) in dieser Evaluation hinter sich ließ.
Dieser Erfolg in der LM Search Arena ist somit mehr als nur ein Achtungserfolg. Er demonstriert eine konsistente Überlegenheit der Perplexity Sonar Modelle in Szenarien, die der realen KI Suche am nächsten kommen, und validiert den Entwicklungsansatz durch direktes Nutzerfeedback.
Was macht Perplexity Sonar so stark? Analyse der Erfolgsfaktoren
Der Triumph von Perplexity Sonar in der LM Search Arena lässt sich auf konkrete Merkmale zurückführen, die von den menschlichen Bewertern offenbar besonders geschätzt wurden. Die Auswertung der über 10.000 Präferenzurteile offenbarte klare Korrelationen zwischen bestimmten Antwort-Eigenschaften und der Nutzerzufriedenheit:
1. Länge und Tiefe der Antworten: Die Analyse zeigte eine signifikante positive Korrelation (Koeffizient 0.255, p<0.05) zwischen der Länge einer Antwort und der Nutzerpräferenz. Das bedeutet: Nutzer bevorzugen tendenziell ausführlichere, tiefgehendere Antworten gegenüber knappen Zusammenfassungen. Perplexity Sonar scheint hier zu punkten, indem es darauf abzielt, Anfragen umfassend zu behandeln und nicht nur Oberflächeninformationen zu liefern.
2. Überlegene Zitierpraxis und Suchtiefe: Ein noch stärkerer Faktor war die Anzahl der Zitate (Koeffizient 0.234, p<0.05). Antworten mit mehr Quellen-Belegen wurden signifikant häufiger bevorzugt. Hier glänzt Perplexity Sonar besonders: Die Modelle zitieren im Durchschnitt 2- bis 3-mal mehr Quellen als vergleichbare Gemini-Modelle. Dies spricht für eine größere „Suchtiefe“ – die Modelle durchsuchen und berücksichtigen offenbar mehr Informationen, bevor sie eine Antwort synthetisieren. Kontrollexperimente bestätigten dies: Wenn man den Einfluss der Zitate herausrechnete, rückten die Modellrankings näher zusammen. Das legt nahe, dass die gründlichere Recherche und die transparente Darstellung der Quellen ein wesentlicher Differenzierungsfaktor für Sonar ist.
3. Nutzung von Community-Quellen: Interessanterweise korrelierte auch die Verwendung von Zitaten aus Community-Webquellen (wie Foren, Diskussionsplattformen etc.) positiv mit der Nutzerpräferenz. Dies deutet darauf hin, dass Nutzer den Wert von aktuellen, praxisnahen Informationen aus solchen Quellen erkennen und schätzen. Perplexity Sonar integriert diese Art von Information effektiv neben autoritativen Quellen und YouTube-Videos.
4. Der „Reasoning Advantage“: Die Rangliste zeigte eine klare Präferenz für Modelle mit expliziten „Reasoning“-Fähigkeiten. Sonar-Reasoning-Pro und Sonar-Reasoning belegten zwei der Top-3-Positionen. Diese Modelle sind darauf ausgelegt, nicht nur Informationen abzurufen, sondern auch logische Schlussfolgerungen zu ziehen, Argumente abzuwägen und komplexere Zusammenhänge zu verstehen. Dass Nutzer diese Fähigkeiten bei Suchanfragen bevorzugen, unterstreicht den Trend hin zu anspruchsvolleren KI-Assistenten, die über reine Informationsretrieval hinausgehen.
Zusammenfassend lässt sich sagen: Perplexity Sonar gewinnt, weil es die von Nutzern gewünschte Kombination aus Tiefe, Transparenz (durch Zitate), Quellenvielfalt und intelligenter Verarbeitung (Reasoning) liefert. Die gründliche Recherche und die Fähigkeit, komplexe Informationen verständlich aufzubereiten, sind klare Stärken.
API-Zugang, Flexible Modi und Preise: Sonar für Entwickler
Der Erfolg von Perplexity Sonar ist nicht nur für Endnutzer relevant. Über die Perplexity Search API können Entwickler und Unternehmen diese leistungsstarke Technologie in ihre eigenen Anwendungen integrieren. Die API bietet Zugriff auf die verschiedenen Sonar-Modelle und ermöglicht es, die KI Suche an spezifische Bedürfnisse anzupassen.
Ein interessantes Feature der Search API sind die flexiblen Suchmodi. Diese erlauben es Dir, eine Balance zwischen maximaler Performance (tiefe Suche, umfassende Antworten) und Kosteneffizienz bzw. Geschwindigkeit zu finden. Je nach Anwendungsfall kannst Du also steuern, wie intensiv das Modell recherchiert und antwortet.
Preisgestaltung im Vergleich:
Die neuen Informationen beinhalten auch eine Preisübersicht (Stand: April 2025, pro 1.000 API-Anfragen), die zeigt, dass Perplexity hier oft sehr wettbewerbsfähig ist:
| Modell | Preis pro 1.000 Requests | Anbieter |
|---|---|---|
| Gemini 2.5 Pro Grounding | $35 | |
| Sonar Reasoning Pro High | $14 | Perplexity |
| Sonar Reasoning | $5 | Perplexity |
| Sonar | $5 | Perplexity |
| Sonar Pro High | $14 | Perplexity |
| Sonar Pro | $6 | Perplexity |
| Gemini 2.0 Flash Grounding | $35 | |
| GPT 4o Search | $35 | OpenAI |
| GPT 4o Search High | $50 | OpenAI |
| GPT 4o Mini Search | $30 | OpenAI |
(Preise können sich ändern. Stand der Tabelle bezieht sich auf die bereitgestellte Quelle von ca. April 2025)
Wie die Tabelle verdeutlicht, sind die Perplexity Sonar Modelle, insbesondere die Varianten ohne „High“, preislich äußerst attraktiv (z.B. $5 für Sonar Reasoning) im Vergleich zu den Top-Modellen von Google ($35) oder den High-End-Suchmodellen von OpenAI ($50). Selbst das Top-Modell Sonar Reasoning Pro High ist mit $14 deutlich günstiger als die direkte Konkurrenz von Google. Dies macht die Integration von hochwertiger KI Suche über die Search API auch für preissensible Projekte realistisch.
Das bereits erwähnte Webinar mit CTO Denis Yarats am 24. April bot tiefere Einblicke in diese API und ihre Anwendungsmöglichkeiten. Die Aufzeichnung oder zukünftige Webinare könnten für Interessierte wertvoll sein.
Fazit: Perplexity Sonar etabliert sich als führende Kraft
Die Ergebnisse der LM Search Arena vom April 2025 sprechen eine klare Sprache: Perplexity Sonar dominiert das Feld der suchgestützten Sprachmodelle, belegt die Ränge 1 bis 4 und schlägt namhafte Konkurrenz von Google und OpenAI in einem praxisnahen Benchmark, der auf menschlichen Präferenzen basiert. Der geteilte erste Platz von Sonar-Reasoning-Pro-High mit Gemini-2.5-Pro-Grounding, gepaart mit Siegen in direkten Vergleichen, unterstreicht die Spitzenleistung.
Die Analyse der Erfolgsfaktoren bestätigt, dass Perplexity auf die richtigen Merkmale setzt: Nutzer schätzen die umfassenden Antworten, die hohe Anzahl an Zitaten als Beleg für gründliche Recherche und die Nutzung vielfältiger, auch Community-basierter Quellen. Der Vorteil von Modellen mit Reasoning-Fähigkeiten wird ebenfalls deutlich. Perplexity Sonar liefert genau das und hebt sich insbesondere durch seine überlegene Suchtiefe und Zitierpraxis ab.
Für Nutzer von Perplexity, insbesondere Pro-Abonnenten, die Sonar als Standardmodell wählen können, sind diese Ergebnisse eine Bestätigung der hohen Qualität und Zuverlässigkeit der KI Suche. Für Entwickler bietet die Perplexity Search API eine leistungsstarke und, wie die Preise zeigen, oft kosteneffiziente Möglichkeit, diese Top-Technologie zu nutzen. Die flexiblen Suchmodi erlauben eine Anpassung an individuelle Bedürfnisse.
Obwohl Perplexity stolz auf dieses Ergebnis ist, betont das Unternehmen sein Engagement für kontinuierliche Verbesserung auf Basis von Nutzerfeedback. Die LM Search Arena liefert dafür wertvolle Daten. Insgesamt etabliert sich Perplexity Sonar mit dieser Leistung endgültig als eine führende Kraft im Bereich der KI Suche, die innovative Ansätze erfolgreich umsetzt und Maßstäbe für die Branche setzt.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #Perplexity #Sonar #SearchAPI #LMSearchArena, Perplexity Sonar







