
OpenAI differenziert sein Angebot an künstlicher Intelligenz weiter aus und präsentiert die GPT-4.1 Modellreihe. Diese neueste Generation von Sprachmodellen wurde entwickelt, um dir als Nutzer oder Entwickler maßgeschneiderte Optionen für eine Vielzahl von Anwendungsfällen zu bieten. Mit den drei Varianten – GPT-4.1 nano, GPT-4.1 mini und dem Flaggschiff GPT-4.1 – schafft OpenAI ein abgestuftes System, das unterschiedliche Schwerpunkte auf Geschwindigkeit, Intelligenz und Kosten legt. Die richtige Wahl aus diesen OpenAI Modellen ist entscheidend, um nicht nur die bestmöglichen Ergebnisse zu erzielen, sondern auch die KI Preise effektiv zu managen.
Aber welches Modell der GPT-4.1-Familie passt am besten zu deinen spezifischen Anforderungen? Worin liegen die genauen Unterschiede in Leistung und Preisgestaltung, basierend auf den neuesten Ankündigungen? Und was bedeuten die spezifischen API-Bezeichnungen und Preisdetails für deine Projekte? Dieser Artikel liefert dir einen detaillierten, konsolidierten Überblick über die Fähigkeiten, Merkmale und die aktualisierte Kostenstruktur der GPT-4.1 Generation von OpenAI. Hier findest du alle relevanten Informationen aus den aktuellen Quellen, um eine fundierte Entscheidung zu treffen und das volle Potenzial dieser fortschrittlichen KI-Werkzeuge auszuschöpfen.
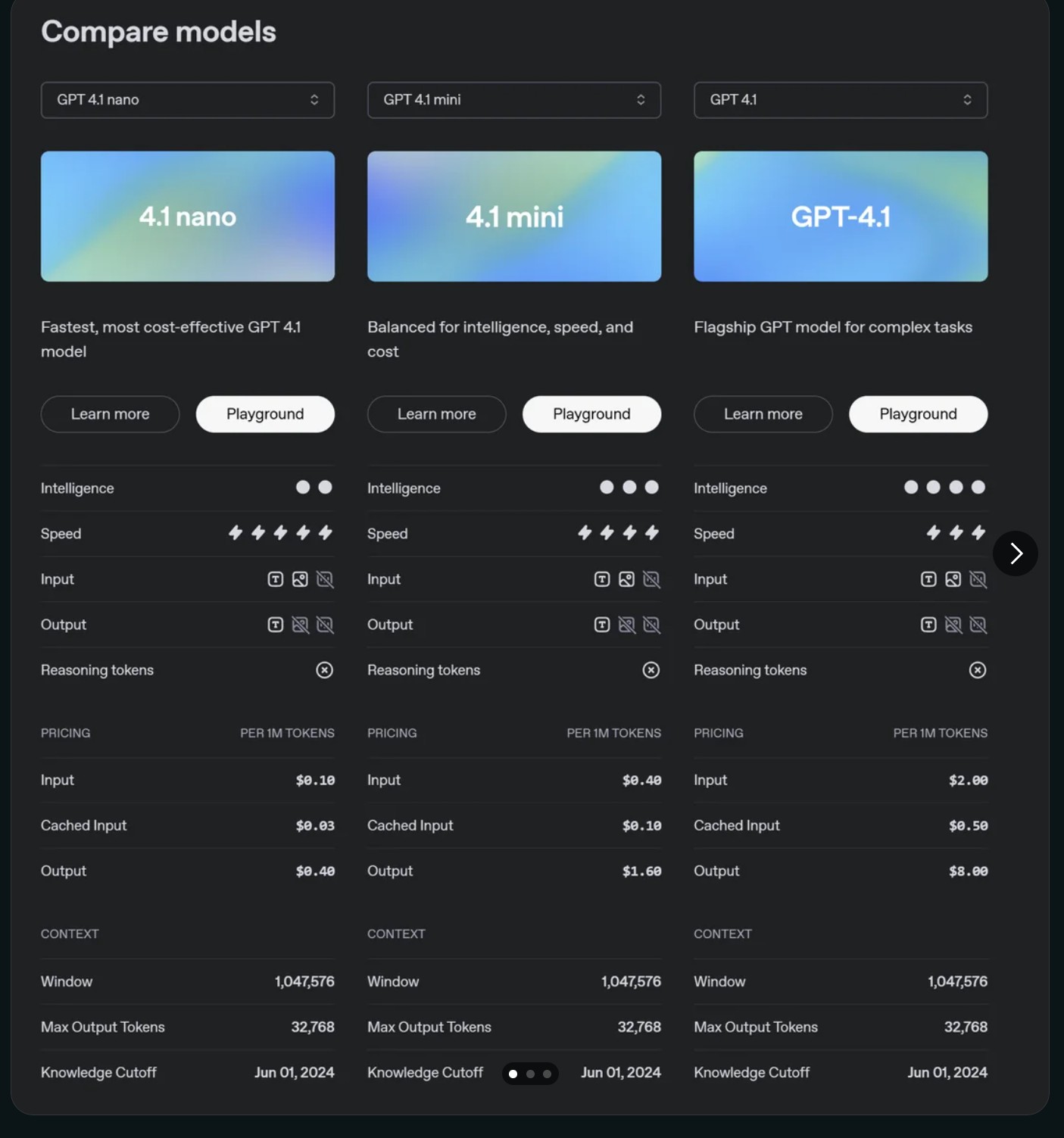
Das musst Du wissen – GPT-4.1 Kernfakten
- GPT-4.1 nano (
gpt-4.1-nano-2025-04-14): Das schnellste und kostengünstigste Modell der Reihe (Input $0.10, Cached Input $0.025, Output $0.40 pro 1 Mio. Tokens), ideal für Effizienz und hohe Geschwindigkeit. - GPT-4.1 mini (
gpt-4.1-mini-2025-04-14): Bietet eine ausgewogene Balance zwischen Intelligenz (Bewertung 3/4), Geschwindigkeit (4/5) und Kosten. Ein vielseitiger Allrounder. - GPT-4.1 (
gpt-4.1-2025-04-14): Das intelligenteste Flaggschiff-Modell (Bewertung 4/4) für hochgradig komplexe Aufgaben, verbunden mit den höchsten Kosten (Input $2.00, Output $8.00 pro 1 Mio. Tokens). - Einheitliche Basis: Alle drei Modelle teilen sich ein beeindruckendes Kontextfenster von 1.047.576 Tokens, ermöglichen einen maximalen Output von 32.768 Tokens und haben einen Wissensstand bis zum 1. Juni 2024. Sie können laut Icon-Darstellung Text, Bilder und Audio verarbeiten.
- Preisstruktur & API: Die Kosten pro Million Tokens variieren stark nach Modell und Nutzung (Input, Output, Cached Input). Es gibt spezifische API-Namen mit Datum für jedes Modell. Hinweise deuten auf potenziell abweichende Batch API Preise hin.
Die GPT-4.1 Familie im Detail: Drei Stufen für deine KI-Anforderungen
Mit der Einführung der GPT-4.1 Serie verfolgt OpenAI klar eine Strategie der Diversifizierung. Anstatt eines „One-size-fits-all“-Ansatzes erhalten Entwickler und Anwender nun eine fein abgestufte Auswahl. Dies ermöglicht es dir, das Werkzeug präzise auf die Anforderungen deines Projekts abzustimmen – sowohl hinsichtlich der benötigten Leistung als auch des verfügbaren Budgets. Die spezifischen API-Namen mit Datumsstempel (z.B. -2025-04-14) deuten auf versionierte Modelle hin, was für die Reproduzierbarkeit und Verwaltung von API-Integrationen wichtig ist.
GPT-4.1 nano (gpt-4.1-nano-2025-04-14): Wenn jede Millisekunde zählt
Das GPT-4.1 nano ist das Einstiegsmodell der Familie, optimiert für maximale Geschwindigkeit und Kosteneffizienz. Laut OpenAI ist es das „schnellste, kosteneffektivste GPT 4.1 Modell“. Die visuelle Bewertung aus den Quellen bestätigt dies: Es erreicht die Höchstwertung bei der Geschwindigkeit (5/5), während die Intelligenz mit (1/4) angegeben wird. Das legt nahe, dass dieses Modell ideal für Aufgaben ist, bei denen schnelle Antwortzeiten und geringe Latenz kritisch sind, auch wenn dafür Abstriche bei der Tiefe der Analyse oder der Komplexität der generierten Inhalte gemacht werden müssen.
Trotz seiner Positionierung am unteren Ende der Intelligenzskala scheint das nano-Modell laut der Icon-Darstellung in der Lage zu sein, multimodale Daten zu verarbeiten: Es kann Text-, Bild- und Audio-Input verarbeiten und entsprechenden Output generieren. Eine interessante Angabe ist jedoch, dass ihm – wie auch den anderen beiden Modellen in der Vergleichsübersicht – die Fähigkeit zur Verarbeitung von „Reasoning Tokens“ abgesprochen wird (gekennzeichnet durch ein ‚X‘). Dies könnte auf eine sehr spezifische technische Definition dieser Tokens hindeuten oder bedeuten, dass bestimmte fortgeschrittene Schlussfolgerungsfähigkeiten in diesem Vergleich nicht berücksichtigt wurden.
Die Preisgestaltung ist der Hauptanziehungspunkt des nano-Modells und wurde mit den neuesten Informationen präzisiert:
- Input: $0.10 pro 1 Million Tokens
- Cached Input: $0.025 pro 1 Million Tokens (korrigierter Wert)
- Output: $0.40 pro 1 Million Tokens
Diese extrem niedrigen Kosten machen das gpt-4.1-nano-2025-04-14 besonders attraktiv für:
- Anwendungen mit sehr hohem Anfragevolumen (z.B. Echtzeit-Monitoring).
- Einfache Chatbots für FAQs oder Standard-Kundenservice.
- Schnelle Textklassifizierungs-, Tagging- oder Sentiment-Analyse-Aufgaben.
- Automatisierte Erstellung sehr kurzer Zusammenfassungen oder Extraktion von Schlüsselwörtern.
- Content-Filterung und einfache Moderationsaufgaben.
Wenn Geschwindigkeit und Kosten die wichtigsten Faktoren sind und die Aufgabe keine tiefe semantische Analyse oder komplexe Kreativität erfordert, ist GPT-4.1 nano die wirtschaftlichste und reaktionsschnellste Option der Reihe.
GPT-4.1 mini (gpt-4.1-mini-2025-04-14): Der intelligente Allrounder
Das GPT-4.1 mini positioniert sich als das mittlere Modell der Serie und schlägt eine Brücke zwischen dem schnellen nano und dem leistungsstarken Flaggschiff. OpenAI beschreibt es treffend als „ausgewogen für Intelligenz, Geschwindigkeit und Kosten“. Die Bewertungen unterstreichen dies: Die Intelligenz ist mit (3/4) deutlich höher als beim nano, während die Geschwindigkeit mit (4/5) immer noch sehr hoch ist. Es bietet somit eine solide kognitive Leistung zu einem moderaten Preis.
Wie seine Geschwister verarbeitet auch das gpt-4.1-mini-2025-04-14 laut den Icons Text-, Bild- und Audio-Input und -Output. Die Angabe „Keine Reasoning Tokens“ gilt laut Quelle auch hier.
Die Preise für das GPT-4.1 mini liegen erwartungsgemäß im Mittelfeld:
- Input: $0.40 pro 1 Million Tokens
- Cached Input: $0.10 pro 1 Million Tokens
- Output: $1.60 pro 1 Million Tokens
Mit dieser Konfiguration ist das mini-Modell ein vielseitiger Allrounder, der für eine breite Palette von Aufgaben geeignet ist, die mehr Intelligenz erfordern als das nano-Modell liefern kann, aber nicht zwingend die Spitzenleistung (und die Kosten) des Flaggschiffs benötigen. Mögliche Einsatzszenarien umfassen:
- Fortgeschrittenere Kundenservice-Anwendungen mit besserem Verständnis für komplexere Anfragen.
- Generierung von Marketingtexten, Blog-Entwürfen, detaillierteren Produktbeschreibungen.
- Datenextraktion und Analyse aus längeren oder komplexeren Dokumenten.
- Qualitativ hochwertige Übersetzungen mit besserer Erfassung von Nuancen.
- Unterstützung bei Programmieraufgaben mittlerer Komplexität.
Wenn du ein starkes OpenAI Modell suchst, das ein exzellentes Gleichgewicht zwischen kognitiven Fähigkeiten, Geschwindigkeit und den KI Preisen bietet, ist gpt-4.1-mini-2025-04-14 wahrscheinlich eine sehr gute Wahl.
GPT-4.1 (gpt-4.1-2025-04-14): Das Flaggschiff für maximale Leistung
An der Spitze der Hierarchie steht das GPT-4.1, das Flaggschiff-Modell, konzipiert für „komplexe Aufgaben“. Hier liegt der Fokus eindeutig auf maximaler kognitiver Leistungsfähigkeit. Es erreicht die Höchstbewertung bei der Intelligenz (4/4) und behält dabei eine hohe Geschwindigkeit (4/5), gleichauf mit dem mini-Modell. Dies deutet darauf hin, dass OpenAI signifikante Fortschritte bei der Steigerung der Intelligenz gemacht hat, ohne die Performance stark zu beeinträchtigen.
Die multimodalen Fähigkeiten (Text, Bild, Audio In/Out) sind laut Icons identisch mit den anderen Modellen. Die Angabe „Keine Reasoning Tokens“ bleibt auch hier gemäß der vorliegenden Quelle bestehen. Obwohl dies kontraintuitiv für ein Flaggschiff-Modell erscheint, das für komplexe Aufgaben gedacht ist, muss dies im Kontext der spezifischen Vergleichsmetrik gesehen werden. Die Beschreibung als „Flaggschiff für komplexe Aufgaben“ impliziert dennoch starke Schlussfolgerungs- und Problemlösungsfähigkeiten.
Die Spitzenposition und hohe Leistungsfähigkeit spiegeln sich deutlich in den KI Preisen wider:
- Input: $2.00 pro 1 Million Tokens
- Cached Input: $0.50 pro 1 Million Tokens
- Output: $8.00 pro 1 Million Tokens
Das gpt-4.1-2025-04-14 ist somit signifikant teurer als die anderen Modelle, insbesondere bei der Generierung von Output (Faktor 4 zwischen Output und Input). Cached Input bietet auch hier eine Kostenersparnis. Dieses Modell ist die erste Wahl, wenn höchste Präzision, tiefes semantisches Verständnis, komplexes logisches Schließen und kreative Spitzenleistungen gefordert sind:
- Wissenschaftliche Forschung, Analyse komplexer Datensätze, Hypothesengenerierung.
- Entwicklung und Debugging von komplexem Software-Code, Architekturentwürfe.
- Erstellung anspruchsvoller und nuancierter kreativer Inhalte (z.B. Fachartikel, detaillierte Berichte).
- Unterstützung bei strategischer Planung und komplexer Entscheidungsfindung.
- Entwicklung hochentwickelter, kontextsensitiver Dialogsysteme und Tutoren.
Wenn die Aufgabe maximale kognitive Fähigkeiten erfordert und die Kosten eine untergeordnete Rolle spielen, ist das GPT-4.1 Flaggschiff-Modell die logische Wahl.
Direkter Vergleich: Leistung und Kosten der GPT-4.1 Modelle
Um die Auswahl zu erleichtern, hier eine tabellarische Übersicht der Kernmerkmale und Preise der drei GPT-4.1 Modelle, basierend auf den konsolidierten Informationen:
| Merkmal | GPT-4.1 nano | GPT-4.1 mini | GPT-4.1 (Flaggschiff) |
|---|---|---|---|
| API Name | gpt-4.1-nano-2025-04-14 | gpt-4.1-mini-2025-04-14 | gpt-4.1-2025-04-14 |
| Beschreibung | Schnellstes, kosteneffektivstes | Ausgewogen (Intelligenz/Speed/Kosten) | Flaggschiff für komplexe Aufgaben |
| Intelligenz (1-4) | 1 / 4 | 3 / 4 | 4 / 4 |
| Speed (1-5) | 5 / 5 | 4 / 5 | 4 / 5 |
| Input Preis ($/1M) | $0.10 | $0.40 | $2.00 \$ |
| \ | **Cached Input** (/1M) | $0.025 | $0.10 |
| \ | **Output Preis** (/1M) | $0.40 | $1.60 |
| Modalitäten (In/Out) | Text, Bild, Audio | Text, Bild, Audio | Text, Bild, Audio |
| Reasoning Tokens | Nein (lt. Quelle) | Nein (lt. Quelle) | Nein (lt. Quelle) |
| Kontextfenster | 1.047.576 Tokens | 1.047.576 Tokens | 1.047.576 Tokens |
| Max Output Tokens | 32.768 Tokens | 32.768 Tokens | 32.768 Tokens |
| Knowledge Cutoff | 1. Juni 2024 | 1. Juni 2024 | 1. Juni 2024 |
In Google Sheets exportieren
Diese Tabelle verdeutlicht die klaren Abstufungen: Das GPT-4.1 nano ist der Preisführer mit Fokus auf Geschwindigkeit. Das GPT-4.1 mini bietet einen Kompromiss für viele Standardaufgaben. Das GPT-4.1 Flaggschiff liefert maximale Intelligenz zu einem Premium-Preis. Die Wahl des richtigen Modells aus dem Portfolio der OpenAI Modelle ist eine strategische Entscheidung, die die benötigte Leistung gegen die entstehenden KI Preise abwägt.
Technische Eckdaten: Was alle GPT-4.1 Modelle gemeinsam haben
Trotz der Unterschiede in Intelligenz und Preis gibt es eine solide gemeinsame technische Basis für alle drei GPT-4.1 Modelle:
- Kontextfenster (Context Window): Mit 1.047.576 Tokens können alle Modelle extrem große Mengen an Informationen verarbeiten. Das ist ideal für die Analyse langer Dokumente, die Aufrechterhaltung langer Dialoge oder die Berücksichtigung umfangreicher Codebasen.
- Maximale Output Tokens: Jede einzelne Antwort eines Modells kann bis zu 32.768 Tokens lang sein. Dies ermöglicht die Generierung ausführlicher Texte, detaillierter Berichte oder umfangreicher Code-Snippets in einem Zug.
- Wissensstichtag (Knowledge Cutoff): Das Training der Modelle wurde am 1. Juni 2024 abgeschlossen. Informationen oder Ereignisse nach diesem Datum sind den Modellen nicht bekannt, es sei denn, sie werden explizit im Input bereitgestellt.
- Multimodalität: Die Icons in den Quellen deuten darauf hin, dass alle drei Modelle Text-, Bild- und Audiodaten als Input verarbeiten und entsprechenden Output generieren können. Dies eröffnet vielfältige Anwendungsmöglichkeiten über reinen Text hinaus.
- Reasoning Tokens: Wie bereits erwähnt, wird in der Vergleichsübersicht für alle drei Modelle angegeben, dass sie keine „Reasoning Tokens“ unterstützen. Dies sollte bei der Bewertung der Fähigkeiten im Hinterkopf behalten werden, auch wenn die Beschreibung des Flaggschiff-Modells auf hohe Komplexitätsbewältigung hindeutet.
Diese Einheitlichkeit vereinfacht die Entwicklung und potenzielle Migration zwischen den Modellen, da die grundlegenden Limits und Fähigkeiten (abgesehen von Intelligenz/Geschwindigkeit) konsistent sind.
Die Preisstruktur entschlüsselt: Input, Output, Cache und Batch
Die Kosten für die Nutzung der OpenAI Modelle basieren auf der Anzahl der verarbeiteten Tokens, wobei ein Token ungefähr einem Teil eines Wortes entspricht. Die KI Preise der GPT-4.1 Serie sind wie folgt gestaffelt:
- Input Tokens: Kosten für die Tokens, die du an die API sendest (deine Prompts, Fragen, Daten).
- Output Tokens: Kosten für die Tokens, die das Modell als Antwort generiert. Diese sind durchweg viermal teurer als Input-Tokens, was den höheren Rechenaufwand für die Generierung widerspiegelt.
- Cached Input Tokens: Eine deutlich günstigere Option, die darauf hindeutet, dass OpenAI Mechanismen zur effizienten Wiederverwendung von bereits verarbeitetem Kontext anbietet. Dies kann Kosten bei wiederholten oder kontextuell ähnlichen Anfragen erheblich senken. Der Preis für Cached Input beim nano-Modell wurde auf $0.025/1M Tokens korrigiert.
- Batch API Preise: Eine der Quellen zeigt eine Option für „Batch API price“. Dies legt nahe, dass es separate, möglicherweise günstigere Tarife geben könnte, wenn Anfragen gebündelt und asynchron über eine spezielle Batch-API eingereicht werden. Details dazu wären der offiziellen OpenAI-Dokumentation zu entnehmen.
Die signifikanten Preisunterschiede zwischen den Modellen (insbesondere beim Output des Flaggschiffs) und die Kostenstruktur selbst erfordern eine sorgfältige Planung und Optimierung der API-Nutzung, um die Wirtschaftlichkeit sicherzustellen.
Fazit: Die richtige Wahl im GPT-4.1 Universum treffen
OpenAI’s Einführung der GPT-4.1 Modellfamilie mit den klar definierten Stufen nano, mini und Flaggschiff ist ein logischer Schritt in einem reifer werdenden KI-Markt. Sie bietet dir als Anwender oder Entwickler die Flexibilität, genau das OpenAI Modell auszuwählen, das deinen Anforderungen an Leistung und Budget am besten entspricht. Ob du nun maximale Geschwindigkeit und minimale KI Preise mit dem GPT-4.1 nano benötigst, einen intelligenten Allrounder im GPT-4.1 mini suchst oder die Spitzenleistung des GPT-4.1 Flaggschiffs für komplexe Herausforderungen brauchst – die Auswahl ist da.
Die Entscheidung wird durch die transparent dargestellten Unterschiede in Intelligenzbewertung, Geschwindigkeit und den klar kommunizierten Preisen erleichtert. Gleichzeitig sorgt die einheitliche technische Basis – das riesige Kontextfenster, die hohen Output-Limits, die multimodalen Fähigkeiten und der gemeinsame Wissensstichtag – für Konsistenz und erleichtert die Integration und Skalierung. Die spezifischen API-Namen (gpt-4.1-...-2025-04-14) unterstreichen den professionellen Anspruch und die Versionierbarkeit der Modelle.
Die Preisstruktur mit den Unterschieden zwischen Input, Output und Cached Input sowie dem Hinweis auf mögliche Batch-API-Tarife erfordert eine bewusste Auseinandersetzung mit der Kostenoptimierung. Es ist wichtig, nicht nur das passende Modell zu wählen, sondern auch die API-Aufrufe effizient zu gestalten.
Während OpenAI auch andere Modelle wie GPT-4o oder Preview-Versionen neuerer Generationen anbietet (wie in einer der Quellen ersichtlich), fokussiert sich die GPT-4.1-Reihe auf ein abgestuftes Angebot innerhalb einer etablierten Architektur. Letztlich hängt die optimale Wahl von deinen Zielen ab: Was muss die KI leisten? Wie schnell? Zu welchem Preis? Mit den hier zusammengefassten Informationen bist du gut gerüstet, um das Potenzial der GPT-4.1 Modelle für deine Projekte voll auszuschöpfen und innovative Lösungen zu realisieren.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #GPT41 #OpenAI #Sprachmodell #API, GPT 4 1 Modelle







