
Stell dir vor, du könntest leistungsstarke KI-Modelle trainieren, die komplexe Schlussfolgerungen ziehen können – und das mit einem Bruchteil der üblichen Kosten und Ressourcen. Klingt zu gut, um wahr zu sein? Forscher der University of Southern California (USC) haben genau das geschafft und präsentieren Tina, eine Familie kleiner, aber beeindruckend fähiger Reasoning-Modelle. Diese Modelle nutzen geschickt Reinforcement Learning (RL) in Kombination mit Low-Rank Adaptation (LoRA), um auf einem kompakten 1,5-Milliarden-Parameter-Basismodell erstaunliche Ergebnisse zu erzielen.
Die Entwicklung starker, mehrstufiger Reasoning-Fähigkeiten in Sprachmodellen (LMs) ist eine der großen Herausforderungen in der KI-Forschung, trotz enormer Fortschritte bei allgemeinen Aufgaben. Solche Fähigkeiten sind entscheidend für komplexe Problemlösungsbereiche wie wissenschaftliche Forschung oder strategische Planung. Bisherige Ansätze wie Supervised Fine-Tuning (SFT) sind oft teuer und riskieren, dass Modelle nur oberflächlich imitieren, statt echtes logisches Verständnis zu entwickeln. Reinforcement Learning bietet eine Alternative, ist aber traditionell ressourcenintensiv. Tina zeigt nun einen neuen, überraschend effizienten Weg auf, der hochwertige KI-Reasoning-Fähigkeiten demokratisiert und für eine breitere Forschung zugänglich macht – mit Post-Training-Kosten von gerade einmal 9 US-Dollar!
Das musst Du wissen – Tina Modelle im Überblick
- Kleine Modelle, große Leistung: Tina basiert auf einem kompakten 1.5B-Parameter-Modell und erreicht oder übertrifft dennoch die Reasoning-Leistung von State-of-the-Art (SOTA) Modellen, die auf derselben Basis aufbauen.
- Effizienz durch LoRA & RL: Der Schlüssel liegt in der Kombination von Reinforcement Learning (RL) und der parameter-effizienten Low-Rank Adaptation (LoRA). LoRA passt nur einen kleinen Teil der Modellparameter an, was das Training extrem ressourcenschonend macht.
- Beeindruckende Ergebnisse: Das beste Tina-Modell zeigt eine Verbesserung der Reasoning-Leistung um über 20 % und erreicht 43,33 % Pass@1 im anspruchsvollen AIME24-Benchmark.
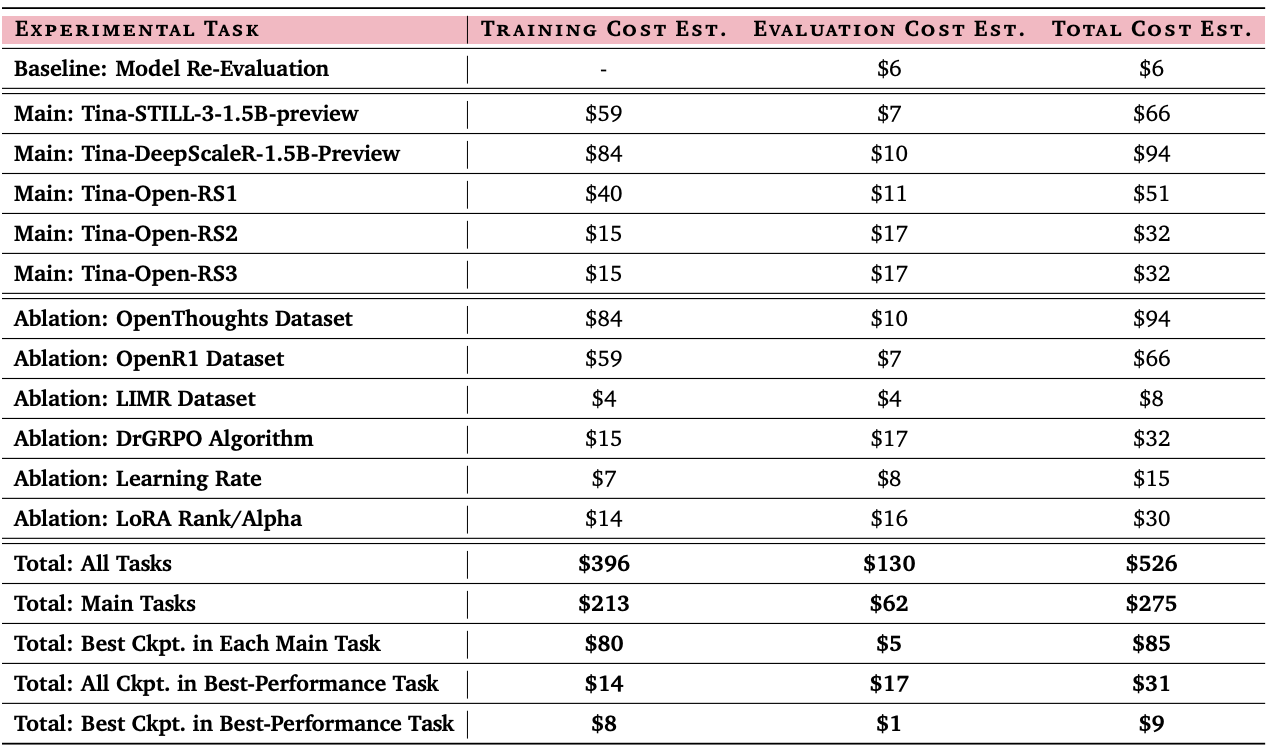
- Minimale Kosten: Die Post-Training- und Evaluierungskosten für das Top-Modell beliefen sich auf nur 9 US-Dollar – eine geschätzte 260-fache Kostenreduktion gegenüber vergleichbaren Ansätzen.
- Open Source & Zugänglich: Alle Ressourcen, einschließlich Code, Trainingsprotokolle und Modell-Checkpoints, sind vollständig Open Source, um die Forschung zu fördern und den Zugang zu erleichtern.
Die Herausforderung: Effizientes KI-Reasoning
Die Fähigkeit von KI-Modellen, logisch zu schlussfolgern und komplexe Probleme Schritt für Schritt zu lösen (Reasoning), ist ein heiliger Gral der KI-Entwicklung. Während große Modelle wie GPT-4 oder o1 beeindruckende allgemeine Fähigkeiten zeigen, bleibt tiefgehendes Reasoning oft eine Hürde.
Traditionelle Methoden zur Verbesserung dieser Fähigkeiten haben Nachteile:
- Supervised Fine-Tuning (SFT): Hier lernen Modelle, indem sie Schritt-für-Schritt-Demonstrationen von leistungsfähigeren Modellen imitieren. Das funktioniert zwar, erfordert aber große Mengen hochwertiger Demonstrationsdaten („Reasoning Traces“), die teuer zu erstellen sind. Zudem besteht die Gefahr, dass die Modelle nur die Struktur der Beispiele nachahmen („shallow mimicry“), ohne die zugrunde liegende Logik wirklich zu verstehen.
- Reinforcement Learning (RL): RL ermöglicht es Modellen, direkt aus Belohnungssignalen zu lernen. Das fördert eine breitere Erkundung verschiedener Lösungswege und potenziell tieferes Verständnis. Allerdings sind klassische RL-Ansätze oft rechenintensiv, komplex zu implementieren und erfordern erhebliche Hardware-Ressourcen.
Die Frage war also: Wie können wir KI-Modelle entwickeln, die stark im Reasoning sind, ohne Unsummen für Training und Hardware auszugeben?
Tina: Der minimalistische Ansatz mit LoRA und RL
Hier setzen die Forscher der USC mit Tina an. Ihr Ansatz verfolgt konsequent das Prinzip des Minimalismus: kleine Modelle, minimale Parameter-Updates und geringer Hardware- und Budgetbedarf.
Das Fundament: Ein kompaktes Basismodell
Als Grundlage dient das DeepSeek-R1-Distill-Qwen-1.5B Modell – ein bereits relativ kleines Modell mit „nur“ 1,5 Milliarden Parametern. Die Idee ist, zu zeigen, dass man nicht zwingend gigantische Modelle braucht, um starke Reasoning-Fähigkeiten zu entwickeln.
Die Methode: Parameter-effizientes RL mit LoRA
Der entscheidende Kniff ist die Anwendung von Low-Rank Adaptation (LoRA) während des Reinforcement Learning (RL)-Prozesses.
- Reinforcement Learning (RL): Das Modell lernt durch Versuch und Irrtum, indem es für korrekte oder gute logische Schlussfolgerungen „belohnt“ wird. Die Forscher nutzten einen effizienten GRPO-ähnlichen Ansatz (Group Relative Policy Optimization), der ohne separate „Value Networks“ auskommt und das Training weiter vereinfacht und beschleunigt. Dies baut auf Erkenntnissen aus anderen Open-Source-Projekten wie STILL, Sky-T1, SimpleRL, PRIME und DeepScaleR auf, die bereits nach effizienten Wegen suchten, die Reasoning-Fähigkeiten großer Modelle wie o1 nachzubilden.
- Low-Rank Adaptation (LoRA): Statt das gesamte Modell (alle 1,5 Milliarden Parameter) während des RL-Trainings anzupassen, werden mit LoRA nur sehr wenige zusätzliche, kleine Matrizen („Low-Rank“-Matrizen) trainiert. Diese repräsentieren die Änderungen am ursprünglichen Modell. Der Großteil des Basismodells bleibt eingefroren. Dies reduziert den Rechenaufwand und den Speicherbedarf drastisch.
Die Hypothese der Forscher ist, dass LoRA dem Modell schnell beibringt, die strukturellen Formate von Reasoning-Aufgaben zu erkennen und zu nutzen, die durch das RL belohnt werden, während das im Basismodell bereits vorhandene Wissen weitgehend erhalten bleibt. Es ist also eine Art gezielte Anpassung an die „Denkweise“, die für das Reasoning erforderlich ist, ohne das gesamte Weltwissen neu lernen zu müssen.
Training: Effizient und kostengünstig
Das Training der Tina-Modelle unterstreicht den Effizienzgedanken:
- Hardware: Es wurden lediglich zwei NVIDIA L40S GPUs verwendet, gelegentlich ergänzt durch RTX 6000 Ada GPUs – eine moderate Ausstattung im Vergleich zu den riesigen GPU-Clustern, die oft für das Training großer Modelle benötigt werden.
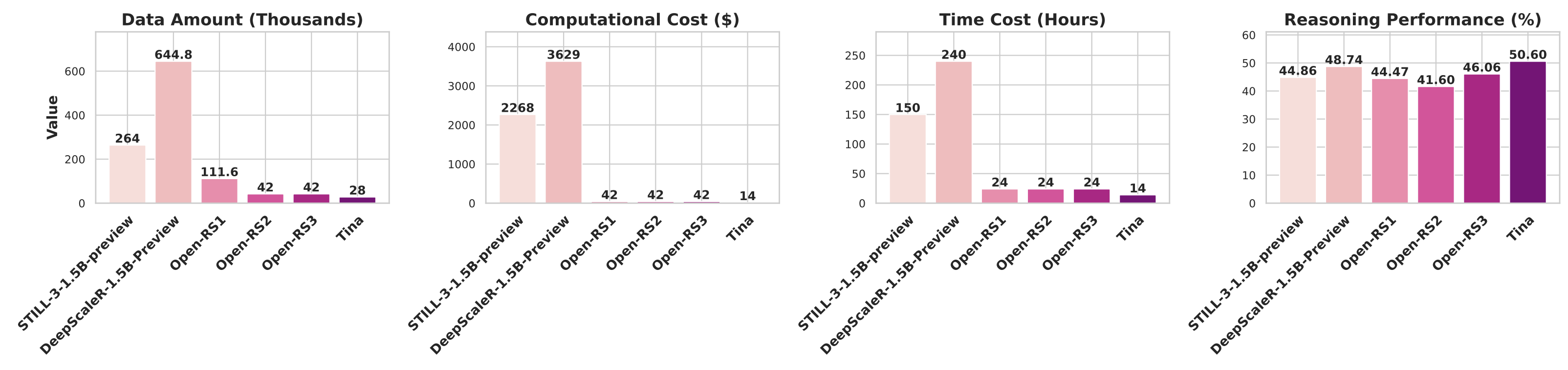
- Daten: Öffentliche Datensätze und replizierte Setups von Modellen wie STILL-3, DeepScaleR und Open-RS kamen zum Einsatz.
- Codebase: Das Training nutzte die OpenR1 Codebase.
- Hyperparameter: Es wurde nur minimale Optimierung der Hyperparameter betrieben.
- Kosten: Die Trainings- und Evaluierungskosten pro Experiment lagen im Durchschnitt deutlich unter 100 US-Dollar. Das leistungsstärkste Modell verursachte sogar nur 9 US-Dollar an Kosten nach dem eigentlichen Training!
Diese extrem niedrigen Kosten machen Tina zu einer hochinnovativen und zugänglichen Plattform für die weitere Forschung im Bereich KI-Reasoning.
Ergebnisse: Überraschende Leistung kleiner Modelle
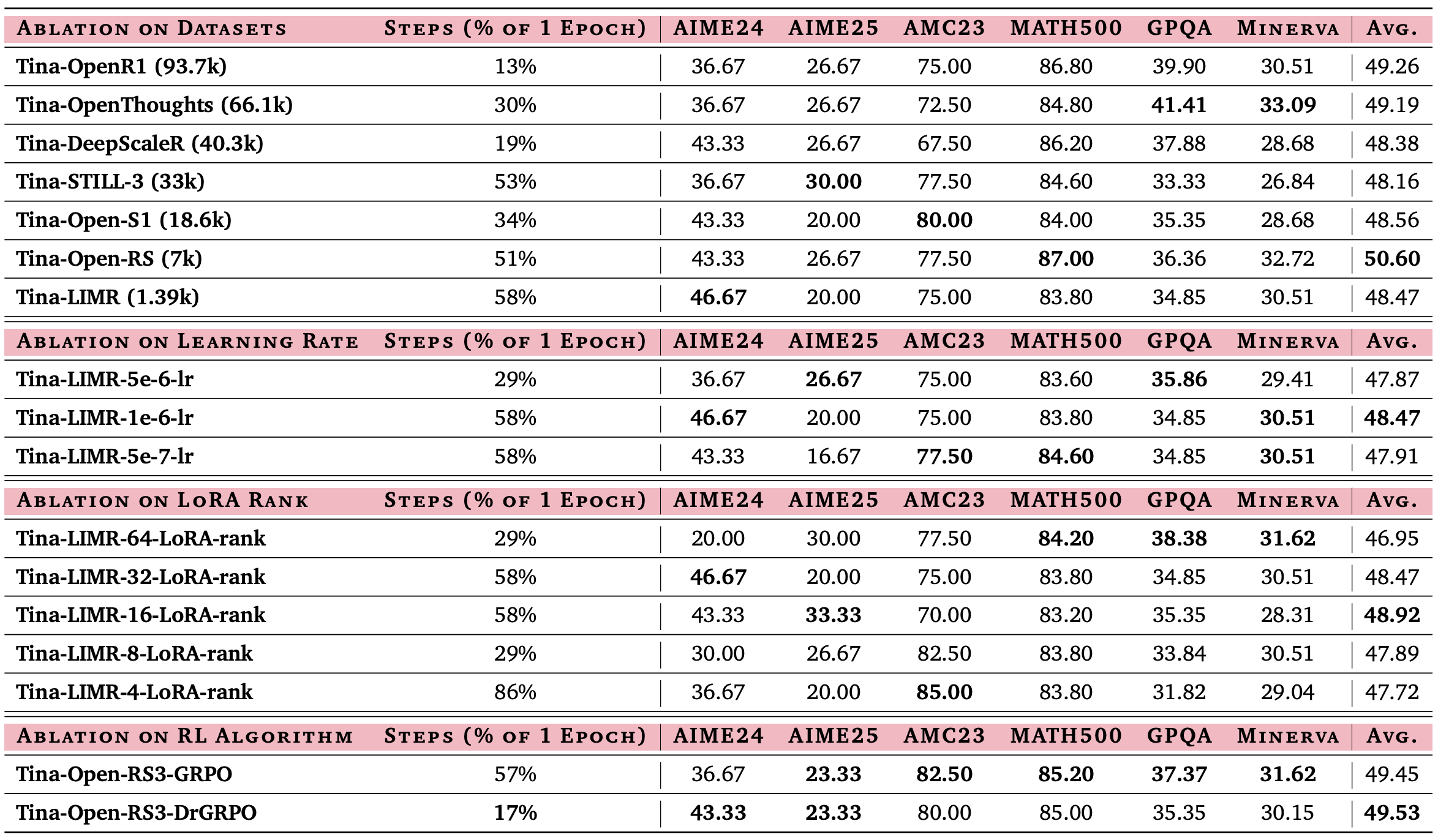
Um faire Vergleiche zu gewährleisten, evaluierten die Forscher zunächst bestehende Basis-Reasoning-Modelle unter konsistenten Bedingungen neu (mit LightEval Framework und vLLM Engine). Sie nutzten sechs anerkannte Reasoning-Benchmarks, darunter AIME 24/25 (Mathematik-Olympiade-Probleme), AMC 23, MATH 500, GPQA und Minerva.
Die anschließende Evaluation der Tina-Modelle (die LoRA-trainierten Varianten) brachte beeindruckende Ergebnisse:
- Überlegene Leistung: Tina-Modelle übertrafen oft ihre „vollständig trainierten“ Pendants (die ohne LoRA, aber mit vollem Parameter-Update auf derselben Basis trainiert wurden), obwohl sie nur einen Bruchteil des Trainingsaufwands benötigten (19–57 % einer Epoche).
- AIME24 Erfolg: Das beste Tina-Modell erreichte eine Pass@1-Genauigkeit von 43,33 % im AIME24-Benchmark – ein sehr starkes Ergebnis für ein 1.5B-Modell, besonders bei den geringen Trainingskosten.
- Performance-Steigerung: Insgesamt wurde eine Verbesserung der Reasoning-Fähigkeiten um über 20 % im Vergleich zu relevanten Baselines erzielt.
Weitere Analysen (Ablation Studies) bestätigten die Effektivität des Ansatzes. Sie zeigten, dass kleinere, aber qualitativ hochwertige Datensätze, passende Lernraten, moderate LoRA-Ränge (die Größe der LoRA-Matrizen) und die Wahl des richtigen RL-Algorithmus die Leistung signifikant beeinflussten. Dies unterstreicht die Robustheit und Effizienz des LoRA-basierten Reasoning-Ansatzes.
Fazit: Tina weist den Weg zu zugänglicherem KI-Reasoning
Die Arbeit der USC-Forscher an Tina ist ein bemerkenswerter Beitrag zur KI-Forschung. Sie demonstriert eindrucksvoll, dass starke Reasoning-Fähigkeiten nicht zwangsläufig riesige Modelle und immense Budgets erfordern. Durch die intelligente Kombination eines kompakten Basismodells (1.5B Parameter) mit Reinforcement Learning (RL) und der parameter-effizienten Low-Rank Adaptation (LoRA) gelingt es, Modelle zu schaffen, die es in puncto Schlussfolgerungsfähigkeit mit deutlich größeren und teurer trainierten State-of-the-Art-Modellen aufnehmen können – und das zu minimalen Kosten von nur 9 US-Dollar für das Post-Training.
Die Leistungssteigerung von über 20 % und die 43,33 % Pass@1-Rate bei AIME24 sind beeindruckende Belege für die Effektivität dieses minimalistischen Ansatzes. Tina zeigt, dass LoRA nicht nur für allgemeine Anpassungen nützlich ist, sondern gezielt eingesetzt werden kann, um die strukturellen Aspekte des Reasonings zu erlernen, die durch RL belohnt werden, während das Kernwissen des Basismodells erhalten bleibt. Dieser gezielte, ressourcenschonende Eingriff ist der Schlüssel zum Erfolg.
Natürlich gibt es noch Limitationen: Die Modelle sind im Vergleich zu Giganten wie GPT-4 immer noch klein, die Vielfalt der getesteten Reasoning-Aufgaben war begrenzt, und die Hyperparameter wurden nur minimal abgestimmt. Dennoch legt Tina den Grundstein für eine neue Richtung in der Entwicklung von KI-Reasoning-Modellen. Der vollständige Open-Source-Ansatz, bei dem Code, Logs und Modell-Checkpoints frei verfügbar gemacht werden, ist dabei besonders lobenswert. Er senkt die Einstiegshürden für Forscher und Entwickler weltweit und fördert eine schnellere Weiterentwicklung auf diesem spannenden Feld. Tina beweist: Auch mit kleinem Budget kann Großes im Bereich KI-Reasoning erreicht werden. Die Zukunft könnte in schlankeren, effizienteren Modellen liegen, die dennoch über erstaunliche Denkfähigkeiten verfügen.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
- Research Paper (arXiv): Wang, Shangshang, Asilis, Julian, Akgül, Ömer Faruk, Bilgin, Enes Burak, Liu, Ollie, & Neiswanger, Willie. „Tina: Tiny Reasoning Models via LoRA“. arXiv:2504.15777 [cs.CL]. (Link zum Abstract), (Link zum PDF), April 22, 2025.
- GitHub Repository: shangshang-wang/Tina (Code, Logs, Model Weights & Checkpoints)
#AI #ArtificialIntelligence #KuenstlicheIntelligenz #TinaModels #LoRA #ReinforcementLearning #Reasoning, Tina Modelle LoRA






