
NVIDIA hat es schon wieder getan. Nur sechs Monate nach dem Debüt der bahnbrechenden Blackwell-Architektur legt das Unternehmen mit dem NVIDIA Blackwell Ultra Chip nach und pulverisiert im anspruchsvollen MLPerf-Benchmark auf einen Schlag alle bestehenden Rekorde für KI-Inferenz. Doch wie ist dieser massive Leistungssprung von bis zu 5-facher Geschwindigkeit im Vergleich zur Vorgängergeneration Hopper möglich? Die Antwort ist keine einzelne Komponente, sondern eine meisterhafte Symphonie aus revolutionärer Chip-Architektur, intelligenten Software-Optimierungen und einem unerbittlichen Fokus auf die Engpässe moderner KI.
In diesem Deep-Dive analysieren wir nicht nur die schwindelerregenden Benchmark-Zahlen, sondern entschlüsseln die exakten technologischen Innovationen, die Blackwell Ultra zur neuen unangefochtenen Königin der KI-Beschleuniger machen. Wir zeigen dir, wie das Zusammenspiel von Dual-Reticle-Design, dem neuen NVFP4-Datenformat und cleveren Serving-Techniken die „KI-Fabriken“ der Zukunft antreibt. Mach dich bereit für eine technische Tour de Force, die erklärt, warum dieser Chip die Spielregeln für KI-Entwickler und Unternehmen für die kommenden Jahre neu definiert.
Ebenfalls erschienen ist NVIDIA Rubin CPX – die neue GPU für 1-Millionen-Token-KI.
NVIDIA Blackwell Ultra – Das Wichtigste in Kürze
- Rekord-Debüt: Der NVIDIA Blackwell Ultra Chip (im GB300 NVL72 System) setzt in der neuesten MLPerf Inference v5.1 Runde neue Weltrekorde in allen neuen Benchmarks, darunter das riesige 671B-Parameter-Modell DeepSeek-R1.
- Architektur-Vorsprung: Blackwell Ultra bietet 1,5-mal mehr KI-Rechenleistung im neuen NVFP4-Format, 2-mal schnellere Attention-Layer-Berechnung und 1,5-mal mehr HBM3e-Speicher im Vergleich zur bereits extrem schnellen Blackwell-Basisversion.
- Bis zu 5,2x schneller: Im direkten Vergleich liefert Blackwell Ultra auf einer Pro-GPU-Basis eine bis zu 5,2-fach höhere Inferenzleistung für anspruchsvolle Reasoning-Modelle als die vorherige Hopper-Generation.
- NVFP4 als Game-Changer: Das neue 4-Bit-Gleitkommaformat (NVFP4) ermöglicht eine massive Reduzierung des Speicherbedarfs bei nahezu gleicher Genauigkeit wie FP8, was direkt zu höherem Durchsatz führt.
- Software ist der Schlüssel: Techniken wie „Disaggregated Serving“ und neue Parallelisierungsstrategien in der TensorRT-LLM-Bibliothek steigern die Effizienz und den Durchsatz um weitere 50% und mehr, indem sie Rechenlasten intelligent verteilen.
- Massiver Speicher: Mit 288 GB HBM3e-Speicher pro GPU kann Blackwell Ultra selbst Multi-Milliarden-Parameter-Modelle komplett im Speicher halten, was Latenzen drastisch reduziert.
- Zukunft der KI-Fabrik: Die Kombination aus Hardware-Power und Software-Intelligenz ermöglicht einen Paradigmenwechsel bei Effizienz und Kosten pro Token und ebnet den Weg für die nächste Generation von KI-Anwendungen.
NVIDIA Blackwell Ultra dominiert MLPerf v5.1: Die Zahlen hinter der Sensation
Der MLPerf-Benchmark ist der unbestrittene Industriestandard zur Messung von KI-Performance. In der neuesten Runde, v5.1, wurden neue, extrem anspruchsvolle Modelle eingeführt, die die heutigen Hardware-Plattformen an ihre Grenzen bringen sollen. Modelle wie DeepSeek-R1 mit 671 Milliarden Parametern oder Llama 3.1 405B simulieren die „Reasoning“-Aufgaben, bei denen eine KI viele Zwischenschritte generiert, bevor sie eine endgültige Antwort liefert – ein rechenintensiver Prozess, der die Latenz (Time-to-First-Token, TTFT) und den Durchsatz (Tokens-per-Second, TPS) auf die Probe stellt.
Genau hier demonstrierte das GB300 NVL72 Rack-System, angetrieben von Blackwell Ultra GPUs, seine überwältigende Überlegenheit. Es stellte nicht nur neue Rekorde bei allen neuen Modellen auf, sondern übertraf auch unbestätigte Ergebnisse eines Hopper-basierten Systems um Längen.
Leistungsvergleich: Blackwell Ultra vs. Hopper auf DeepSeek-R1 | Architektur | Server-Szenario (Tokens/Sekunde/GPU) | Vorteil | | :— | :— | :— | | Hopper (unverifiziert) | 556 | 1x | | Blackwell Ultra | 2.907 | 5,2x | Quelle: MLPerf Inference v5.1, Closed Division, Ergebnisse vom 9. September 2025.
Ein Fünffaches an Leistung pro GPU – dieser Sprung ist in der Halbleiterindustrie außergewöhnlich und kein Zufall. Er ist das Ergebnis gezielter architektonischer Meisterleistungen.
Der Maschinenraum: 3 Schlüssel-Innovationen der NVIDIA Blackwell Ultra Architektur
Um zu verstehen, warum Blackwell Ultra so schnell ist, müssen wir unter die Haube schauen. Der Chip ist mehr als nur eine Weiterentwicklung; er ist eine Neukonzeption, die auf drei Säulen ruht.
1. Dual-Reticle-Design & 15 PetaFLOPS mit NVFP4
Blackwell Ultra ist technisch gesehen ein einziger, riesiger Chip, der jedoch aus zwei physisch getrennten Silizium-Dies besteht, die über eine extrem schnelle 10 TB/s-Verbindung (NV-HBI) nahtlos miteinander verbunden sind. Dieses Design ermöglichte es NVIDIA, die Transistorzahl auf sagenhafte 208 Milliarden zu steigern (2,6x mehr als Hopper) und 160 Streaming Multiprocessors (SMs) zu integrieren.
Der wahre Clou liegt jedoch in den 640 Tensor Cores der fünften Generation. Diese sind für das neue NVIDIA NVFP4-Datenformat optimiert. NVFP4 ist ein 4-Bit-Gleitkommaformat, das den Speicherbedarf im Vergleich zu FP8 halbiert, aber durch einen cleveren Skalierungsmechanismus eine fast identische Genauigkeit erreicht.
- Direkter Impact: Für den DeepSeek-R1-Benchmark konnten die NVIDIA-Ingenieure die FP8-Gewichte des Modells mit dem TensorRT Model Optimizer auf NVFP4 quantisieren. Das Ergebnis: Das Modell wurde kleiner, passte besser in den Cache und konnte die 15 PetaFLOPS NVFP4-Rechenleistung der Ultra-Architektur voll ausnutzen. Dies ist der Hauptgrund für den enormen Leistungssprung.
2. Verdoppelte Attention-Compute-Leistung
Moderne Transformer-Modelle, das Herzstück von LLMs wie Llama oder DeepSeek, verbringen einen Großteil ihrer Rechenzeit in der sogenannten „Attention Layer“, insbesondere bei der Softmax-Berechnung. Diese erfordert komplexe mathematische Operationen.
NVIDIA hat genau diesen Flaschenhals adressiert: Blackwell Ultra verdoppelt den Durchsatz der Special Function Units (SFUs) für diese spezifischen Operationen im Vergleich zur normalen Blackwell-GPU.
- Direkter Impact: Schnellere Attention-Berechnungen bedeuten eine geringere „Time-to-First-Token“ (TTFT). Für interaktive Anwendungen, bei denen der Nutzer auf eine schnelle erste Reaktion wartet, ist dieser Vorteil entscheidend und direkt in den MLPerf-Ergebnissen für interaktive Szenarien sichtbar.
3. Massiver Speicher: 288 GB HBM3e für riesige Modelle
Die Größe von KI-Modellen explodiert. Ein 405-Milliarden-Parameter-Modell wie Llama 3.1 405B benötigt Unmengen an Speicher, insbesondere für den Key-Value (KV) Cache, der während des „Denkprozesses“ wächst. Muss dieser Cache auf langsameren Speicher ausgelagert werden, bricht die Performance ein.
Blackwell Ultra bietet mit 288 GB HBM3e-Speicher pro GPU eine um 50 % höhere Kapazität als die Basis-Blackwell-GPU und 3,6-mal mehr als der H100.
- Direkter Impact: Modelle wie Llama 3.1 405B können vollständig im ultraschnellen On-Chip-Speicher residieren. Dies eliminiert Latenz-Engpässe und ermöglicht einen konstant hohen Durchsatz, selbst bei langen Konversationen mit der KI.
Deep-Dive: Die Software, die das Silizium entfesselt
Die beste Hardware ist nutzlos ohne die passende Software. NVIDIAs wahrer Wettbewerbsvorteil liegt im Full-Stack-Ansatz, bei dem Software wie TensorRT-LLM und das Dynamo-Framework perfekt auf die Hardware-Fähigkeiten abgestimmt sind. Zwei Techniken waren für die Rekordergebnisse entscheidend.
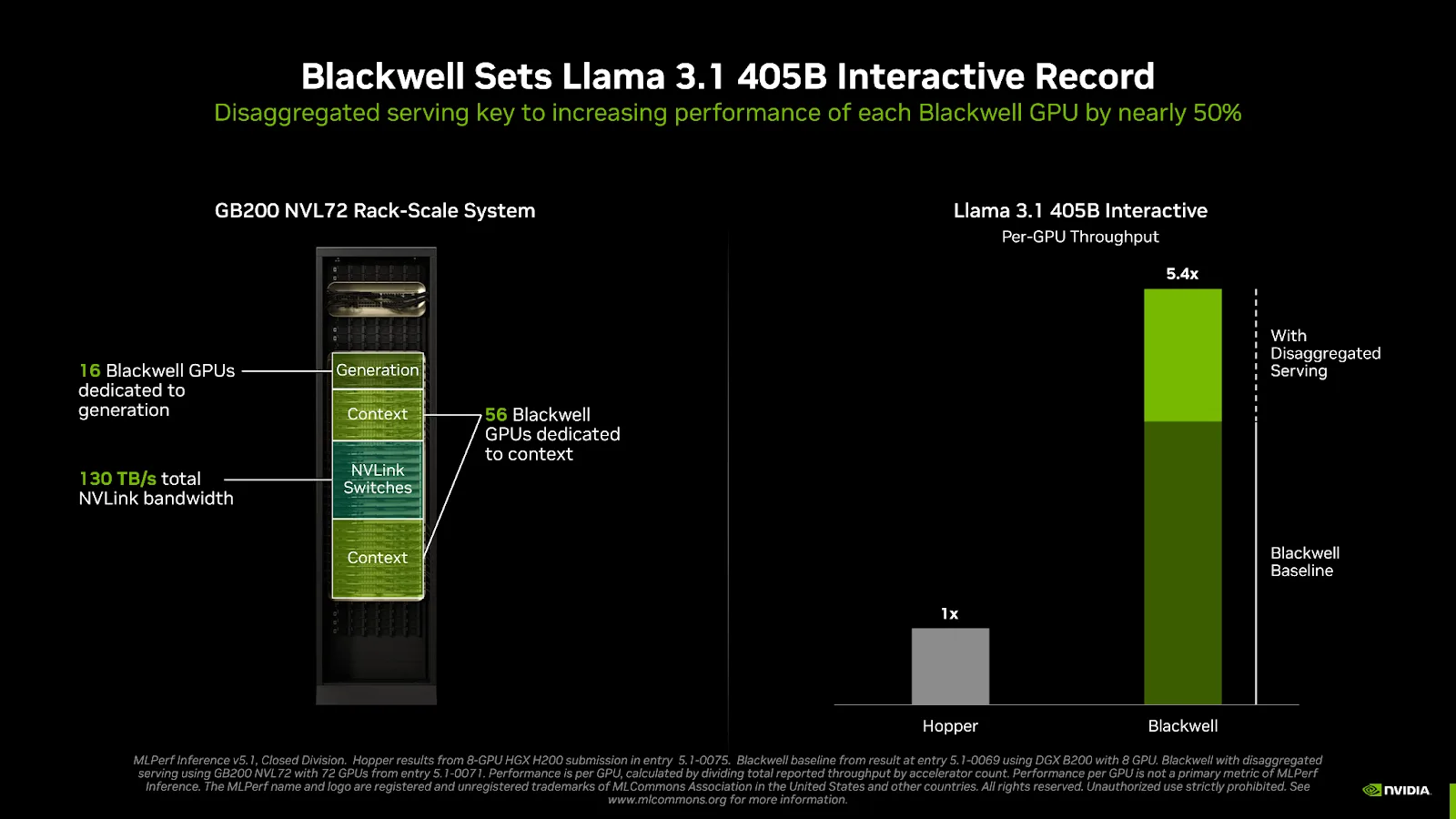
Disaggregated Serving erklärt
Traditionell laufen beide Phasen der KI-Inferenz – die Verarbeitung der Eingabe („Context“) und die Generierung der Antwort („Generation“) – auf derselben GPU. Diese Phasen haben jedoch völlig unterschiedliche Anforderungen: Der Context-Schritt ist rechenintensiv, während der Generation-Schritt latenzempfindlich ist.
Disaggregated Serving trennt diese beiden Phasen auf unterschiedliche GPU-Pools. Ein Pool von GPUs ist ausschließlich für die schnelle Verarbeitung der Eingaben zuständig, ein anderer, separat skalierbarer Pool kümmert sich um die tokenweise Generierung der Antwort.
- Der Beweis: Im anspruchsvollen interaktiven Benchmark für Llama 3.1 405B konnte NVIDIA durch den Einsatz von Disaggregated Serving auf einem GB200-System den Durchsatz pro GPU um fast 50 % im Vergleich zum traditionellen Ansatz steigern. Diese Technik maximiert die Auslastung und Effizienz jeder einzelnen GPU im System.
Fortschrittliche Parallelisierung für MoE-Modelle
Mixture-of-Experts (MoE)-Modelle wie DeepSeek-R1 haben eine komplexe Architektur, bei der je nach Eingabe nur bestimmte „Experten“-Teile des Netzwerks aktiviert werden. Standard-Parallelisierungstechniken stoßen hier an ihre Grenzen.
NVIDIA entwickelte für den MLPerf-Benchmark neue Techniken:
- Expert Parallelism: Verteilt die MoE-Layer auf verschiedene GPUs.
- Data Parallelism: Wendet eine andere Parallelisierungsstrategie für die Attention-Mechanismen an.
- ADP Balance: Ein intelligenter Algorithmus, der die Arbeitslast so verteilt, dass sowohl hoher Durchsatz als auch niedrige Latenz gewährleistet sind.
Diese in TensorRT-LLM implementierten Optimierungen sind entscheidend, um die theoretische Leistung der Hardware in der Praxis auf die Straße zu bringen.
Vergleichsmatrix: NVIDIA Blackwell Ultra vs. Blackwell vs. Hopper
Um die Fortschritte zu verdeutlichen, hier ein direkter Vergleich der wichtigsten Spezifikationen.
| Feature | Hopper H100 | Blackwell B200 | Blackwell Ultra B300 |
| Fertigungsprozess | TSMC 4N | TSMC 4NP | TSMC 4NP |
| Transistoren | 80 Mrd. | 208 Mrd. | 208 Mrd. |
| NVFP4 Dense Compute | – | 10 PetaFLOPS | 15 PetaFLOPS |
| FP8 Dense Compute | 2 PetaFLOPS | 5 PetaFLOPS | 5 PetaFLOPS |
| Attention Acceleration | 4.5 T-Exponentials/s | 5 T-Exponentials/s | 10.7 T-Exponentials/s |
| Max. HBM-Kapazität | 80 GB HBM3 | 192 GB HBM3e | 288 GB HBM3e |
| Max. HBM-Bandbreite | 3.35 TB/s | 8 TB/s | 8 TB/s |
| NVLink-Bandbreite | 900 GB/s | 1.800 GB/s | 1.800 GB/s |
| Max. Leistungsaufnahme | 700W | 1.200W | 1.400W |
Die Tabelle fasst die wichtigsten Spezifikationen der GPU-Chips zusammen und zeigt den signifikanten Sprung von Blackwell Ultra in den für KI-Inferenz kritischen Bereichen.
Expert Insights: Was die Rekorde für die KI-Industrie bedeuten
„Die MLPerf-Ergebnisse von Blackwell Ultra sind mehr als nur neue Rekordzahlen; sie sind ein Indikator für einen Tipping Point“, sagt ein Branchenanalyst. „Die Fähigkeit, riesige Reasoning-Modelle mit dieser Geschwindigkeit und Effizienz zu betreiben, senkt die Kosten pro Token dramatisch. Das macht komplexe KI-Assistenten, die wirklich ’nachdenken‘ können, für eine breite Masse von Unternehmensanwendungen wirtschaftlich rentabel. NVIDIA verkauft nicht nur Chips, sie verkaufen die Schlüssel zur nächsten Generation der KI-Ökonomie.“
5 häufige Fehler bei der Bewertung von GPU-Performance
- Nur auf PetaFLOPS schauen: Die reine Rechenleistung ist nur die halbe Miete. Ohne ausreichend Speicherbandbreite und Kapazität verhungert der Rechenkern.
- Die Software ignorieren: Wie die MLPerf-Ergebnisse zeigen, können Software-Optimierungen wie Disaggregated Serving die Leistung um 50% und mehr steigern.
- Latenz (TTFT) vernachlässigen: Für interaktive Anwendungen ist die gefühlte Geschwindigkeit entscheidend, und die hängt von einer niedrigen Latenz ab.
- Netzwerk-Interconnect unterschätzen: Bei Systemen mit Dutzenden von GPUs (wie dem NVL72) ist die Geschwindigkeit der GPU-zu-GPU-Kommunikation (NVLink) der entscheidende Faktor für die Skalierbarkeit.
- Per-GPU-Metriken überbewerten: Während nützlich für Vergleiche, ist die Gesamtleistung und Effizienz des Gesamtsystems (wie eines NVL72 Racks) das, was für Betreiber von Rechenzentren zählt.
Ausblick: Von Blackwell zu Rubin und die Zukunft der KI-Fabrik
Blackwell Ultra ist ein gewaltiger Schritt nach vorn, aber NVIDIA blickt bereits weiter. Mit der Ankündigung des Rubin CPX, eines speziell für die Verarbeitung langer Kontexte entwickelten Prozessors, deutet das Unternehmen bereits die nächste Spezialisierungswelle an. Die Zukunft liegt in hochgradig optimierten, heterogenen Systemen, die für spezifische KI-Workloads maßgeschneidert sind.
Die Blackwell-Ultra-Plattform legt das Fundament für diese „AI Factories“: hochgradig effiziente, skalierbare Infrastrukturen, die Intelligenz als Dienstleistung produzieren – mit höherem Durchsatz, geringerer Latenz und besserer Energieeffizienz als je zuvor.
Tools & Ressourcen für Entwickler
- MLPerf Inference v5.1 Repository: GitHub-Link zur Reproduktion der Ergebnisse
- TensorRT-LLM: NVIDIAs Inferenz-Bibliothek auf GitHub
- Blackwell Architektur Whitepaper: Technischer Deep-Dive von NVIDIA (Link konzeptionell)
- NVIDIA Dynamo Framework: Informationen zum verteilten Inferenz-Framework (Link konzeptionell)
Häufig gestellte Fragen zu NVIDIA Blackwell Ultra
Was ist der Hauptunterschied zwischen NVIDIA Blackwell und Blackwell Ultra? Blackwell Ultra ist eine erweiterte Version der Blackwell-Architektur. Sie bietet 1,5x mehr NVFP4-Rechenleistung, 2x schnellere Attention-Berechnung und 1,5x mehr HBM3e-Speicher (288 GB vs. 192 GB) pro GPU, was sie speziell für die anspruchsvollsten Inferenz-Workloads prädestiniert.
Warum ist NVFP4 so wichtig für die KI-Leistung? NVFP4 ist ein 4-Bit-Gleitkommaformat, das den Speicherbedarf von KI-Modellen drastisch reduziert, ohne die Genauigkeit signifikant zu beeinträchtigen. Weniger Speicherbedarf bedeutet, dass mehr Daten im schnellen On-Chip-Speicher Platz finden und die Rechenkerne besser ausgelastet werden können, was direkt zu höherem Durchsatz führt.
Ist Blackwell Ultra auch für das Training von KI-Modellen geeignet? Während die hier gezeigten Rekorde im Bereich Inferenz (Anwendung von KI-Modellen) erzielt wurden, ist die Blackwell-Architektur auch für das Training konzipiert. Die massive Rechenleistung, der große Speicher und die hohe Interconnect-Bandbreite machen sie auch zu einer extrem leistungsfähigen Trainingsplattform.
Was bedeutet „Disaggregated Serving“ für die Praxis? Es bedeutet eine effizientere Nutzung teurer GPU-Ressourcen. Indem man die Verarbeitung von User-Anfragen und die Generierung von KI-Antworten auf separate, spezialisierte GPU-Gruppen aufteilt, kann man die Systemauslastung maximieren und mehr Nutzer gleichzeitig bedienen, was die Betriebskosten senkt.
Wie viel kostet ein System mit Blackwell Ultra GPUs? NVIDIA verkauft einzelne GPUs selten direkt an Endkunden. Blackwell Ultra wird als Teil von Komplettsystemen wie dem GB300 NVL72 Rack oder in Servern von Partnern wie Dell, HP und Supermicro angeboten. Die Preise für solche Systeme liegen im Bereich von Hunderttausenden bis mehreren Millionen Dollar.
Wann werden Systeme mit Blackwell Ultra verfügbar sein? NVIDIA hat die ersten Systeme für Ende 2025 angekündigt, mit einer breiteren Verfügbarkeit über Partner im Laufe des Jahres 2026.
Kann ich die Leistung von Blackwell Ultra selbst testen? Direkter Hardware-Zugang ist zunächst auf große Cloud-Anbieter und Forschungseinrichtungen beschränkt. Entwickler können jedoch NVIDIAs Software-Bibliotheken wie TensorRT-LLM nutzen, um ihre Modelle für die Blackwell-Architektur vorzubereiten und zu optimieren.
Fazit NVIDIA Blackwell Ultra: Mehr als nur ein Chip – ein Paradigmenwechsel
Die atemberaubenden MLPerf-Ergebnisse des NVIDIA Blackwell Ultra sind keine Überraschung, sondern die logische Konsequenz einer langfristigen Strategie. NVIDIA hat erneut bewiesen, dass Spitzenleistung im KI-Zeitalter nicht allein durch rohes Silizium entsteht, sondern durch eine tiefgreifende Integration von Chip-Architektur, Software-Optimierung und einem präzisen Verständnis der Workloads. Der 5-fache Leistungssprung gegenüber Hopper ist das Resultat gezielter Innovationen wie NVFP4, beschleunigter Attention-Berechnung und einem massiven Speicherausbau.
Für Entwickler, Unternehmen und die gesamte KI-Branche bedeutet dies, dass die technologischen Barrieren für die nächste Generation intelligenter Anwendungen gefallen sind. Modelle, die komplexe Probleme durch „Reasoning“ lösen, werden schneller, zugänglicher und wirtschaftlicher. Blackwell Ultra ist nicht nur der Motor für die heutigen LLMs, sondern der Grundstein für die KI-Fabriken, die die Intelligenz von morgen in einem noch nie dagewesenen Maßstab produzieren werden.
Der nächste Schritt für dich als Entwickler oder IT-Entscheider ist, die Implikationen dieser neuen Leistungsklasse zu verstehen. Beginne damit, deine KI-Roadmap zu überprüfen und deine Modelle mit den neuesten NVIDIA-Bibliotheken zu optimieren. Die Ära der KI-Fabriken hat gerade erst begonnen, und Blackwell Ultra liefert den Takt.
Quellen und weiterführende Literatur
- NVIDIA Developer Blog (09. Sep. 2025): „NVIDIA Blackwell Ultra Sets New Inference Records in MLPerf Debut“
- NVIDIA Developer Blog (22. Aug. 2025): „Inside NVIDIA Blackwell Ultra: The Chip Powering the AI Factory Era“
- MLCommons Association: Offizielle MLPerf Inference Ergebnisse
- NVIDIA TensorRT-LLM GitHub Repository
- DeepSeek AI Offizielle Website
- Meta AI Llama 3.1 Ankündigung
- Hugging Face Whisper Model Card
#KI #AI #NVIDIA #BlackwellUltra #GPU #MLPerf #Tech2025 #AIinference #DeepLearning #Halbleiter






