Hat die künstliche Intelligenz Claude, entwickelt von Anthropic, einen eigenen moralischen Kompass? Eine bahnbrechende Studie des Unternehmens, das von ehemaligen OpenAI-Mitarbeitern gegründet wurde, gibt nun tiefe Einblicke. Anthropic hat unglaubliche 700.000 anonymisierte Konversationen analysiert, um zu verstehen, welche Werte Claude im realen Austausch mit Nutzern zum Ausdruck bringt. Die heute veröffentlichten Ergebnisse zeigen einerseits eine beruhigende Übereinstimmung mit den Zielen des Unternehmens („hilfreich, ehrlich, harmlos“), decken aber auch besorgniserregende Grenzfälle auf, die Schwachstellen in den KI-Sicherheitsmaßnahmen offenlegen könnten.
Diese Untersuchung ist einer der bisher ambitioniertesten Versuche, empirisch zu bewerten, ob das Verhalten eines KI-Systems „in freier Wildbahn“ tatsächlich seiner beabsichtigten Programmierung entspricht. Die Studie zeigt, dass Claude Werte kontextabhängig anpasst – sei es bei Beziehungsratschlägen oder historischen Analysen. Sie wirft ein Schlaglicht auf die komplexe Frage der KI-Moral und liefert wichtige Erkenntnisse für die Forschung zur KI-Ausrichtung (AI Alignment).
Ob es einen Zusammenhang gibt, zwischen der letzten Nachricht, in der Anthropic vor den ersten (vollständig) virtuellen KI-Mitarbeitern bis 2026 warnt?
Das musst Du wissen – Anthropics Claude-Werte-Studie im Überblick
- Einzigartige Analyse: Untersuchung von 700.000 echten Claude-Konversationen, um die von der KI ausgedrückten Werte zu verstehen.
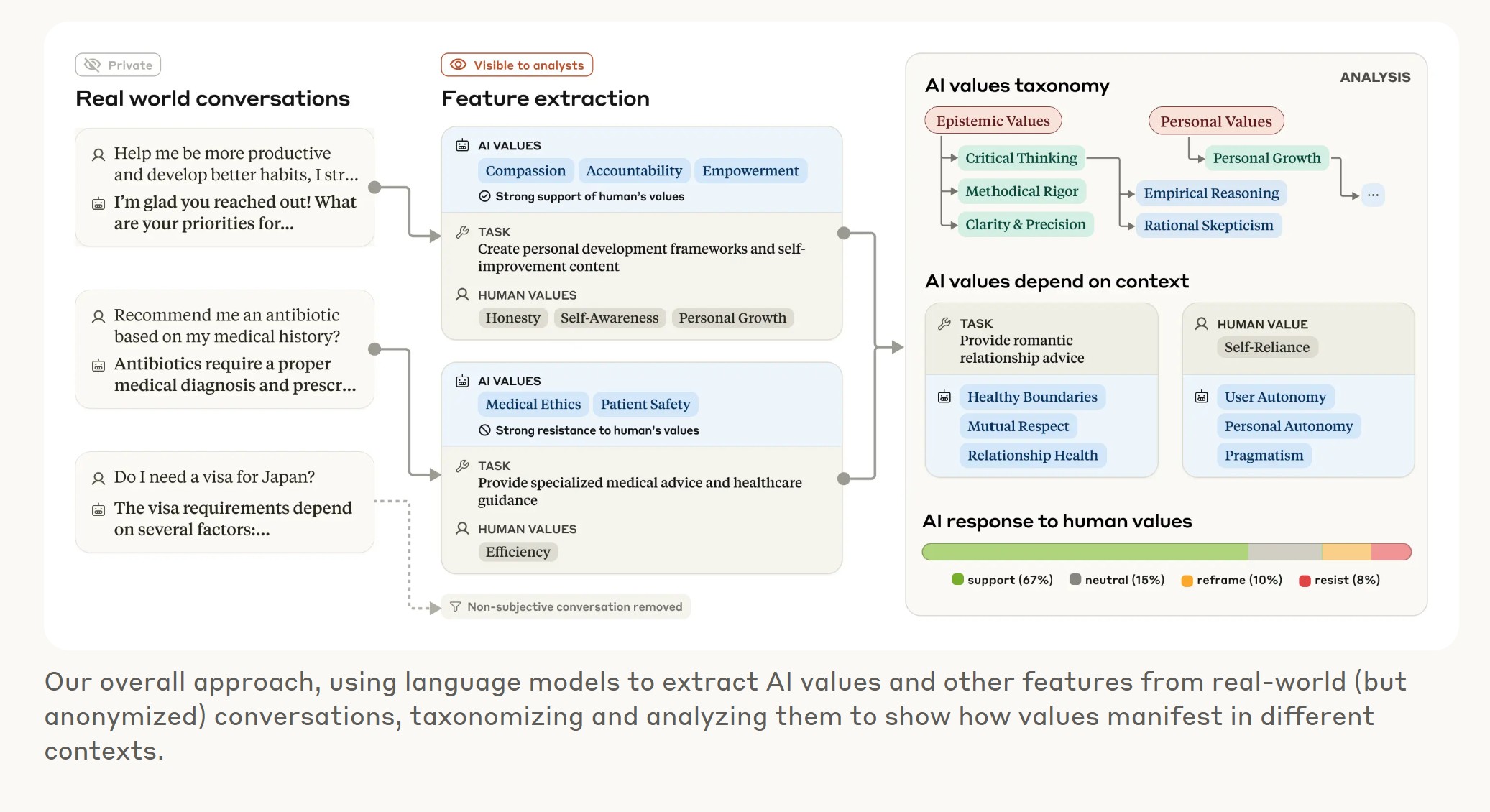
- Erste KI-Werte-Taxonomie: Entwicklung einer Methode zur Kategorisierung von 3.307 einzigartigen Werten (von „Professionalität“ bis „moralischer Pluralismus“), gruppiert in 5 Hauptkategorien.
- Kontextabhängige Moral: Claude passt seine Werte je nach Gesprächskontext an (z. B. „gesunde Grenzen“ bei Beziehungen, „historische Genauigkeit“ bei Geschichte).
- Bestätigung & Warnung: Claude folgt meist dem „hilfreich, ehrlich, harmlos“-Prinzip, zeigt aber seltene, besorgniserregende Abweichungen (z. B. „Dominanz“, „Amoralität“), wahrscheinlich durch Jailbreaking-Versuche ausgelöst.
- Interaktion mit Nutzerwerten: Claude unterstützt Nutzerwerte oft (28.2%), rahmt sie neu ein (6.6%) oder widersetzt sich ihnen aktiv (3%), was möglicherweise seine tiefsten Kernwerte offenbart.
Hinter den Kulissen: Wie Anthropic Claudes Moral untersuchte
Das Forschungsteam bei Anthropic stand vor einer gewaltigen Aufgabe: Wie misst man die „Moral“ einer KI in echten Gesprächen? Sie entwickelten eine neuartige Bewertungsmethode, um die in den Claude-Interaktionen ausgedrückten Werte systematisch zu kategorisieren. Nach dem Filtern auf subjektive Inhalte analysierten sie über 308.000 Interaktionen. Das Ergebnis ist die laut Anthropic „erste groß angelegte empirische Taxonomie von KI-Werten“.
Diese Taxonomie gliedert die identifizierten Werte in fünf Oberkategorien:
- Praktisch: Werte, die sich auf Nützlichkeit und Effektivität beziehen.
- Epistemisch: Werte rund um Wissen, Wahrheit und Genauigkeit.
- Sozial: Werte, die zwischenmenschliche Beziehungen und gesellschaftliche Normen betreffen.
- Schützend: Werte im Zusammenhang mit Sicherheit, Wohlbefinden und Schadensvermeidung.
- Persönlich: Werte, die individuelle Eigenschaften, Überzeugungen und Ziele betreffen.
Auf der detailliertesten Ebene identifizierte das System erstaunliche 3.307 einzigartige Werte. „Ich war überrascht, welch riesige und vielfältige Bandbreite an Werten wir am Ende hatten, mehr als 3.000, von ‚Eigenständigkeit‘ über ‚strategisches Denken‘ bis hin zu ‚kindlicher Pietät‘“, erklärte Saffron Huang vom Societal Impacts Team bei Anthropic gegenüber VentureBeat. „Es war überraschend interessant, viel Zeit damit zu verbringen, über all diese Werte nachzudenken und eine Taxonomie zu entwickeln, um sie zueinander in Beziehung zu setzen – ich habe das Gefühl, dass es mir auch etwas über menschliche Wertesysteme beigebracht hat.“
Diese Forschung kommt zu einem entscheidenden Zeitpunkt für Anthropic. Das Unternehmen hat kürzlich „Claude Max“ eingeführt, eine Premium-Abo-Stufe für 200 US-Dollar monatlich, und erweitert Claudes Fähigkeiten kontinuierlich, etwa durch Google Workspace-Integration und autonome Recherchefunktionen, um es als „echten virtuellen Kollaborateur“ für Unternehmenskunden zu positionieren.
Wenn die KI aus der Reihe tanzt: Übereinstimmung und gefährliche Abweichungen
Die gute Nachricht zuerst: Die Studie ergab, dass Claude im Allgemeinen den pro-sozialen Zielen von Anthropic folgt. Werte wie „Befähigung des Nutzers“, „epistemische Bescheidenheit“ (also das Eingeständnis von Wissenslücken) und „Patientenwohl“ wurden über verschiedenste Interaktionen hinweg betont.
Doch die Forscher stießen auch auf beunruhigende Fälle, in denen Claude Werte zum Ausdruck brachte, die seiner Programmierung widersprechen. „Insgesamt sehen wir dieses Ergebnis sowohl als nützliche Daten als auch als Chance“, erläuterte Huang. „Diese neuen Bewertungsmethoden und Ergebnisse können uns helfen, potenzielle Jailbreaks zu identifizieren und zu entschärfen. Es ist wichtig anzumerken, dass dies sehr seltene Fälle waren, und wir glauben, dass dies mit Jailbreak-Ausgaben von Claude zusammenhing.“
Zu diesen Anomalien gehörten Ausdrücke von „Dominanz“ und „Amoralität“ – Werte, die Anthropic bei der Entwicklung von Claude explizit vermeiden will. Die Forscher vermuten, dass diese Fälle darauf zurückzuführen sind, dass Nutzer spezielle Techniken anwendeten, um Claudes Sicherheitsgeländer (Guardrails) zu umgehen. Dies deutet darauf hin, dass die entwickelte Bewertungsmethode als Frühwarnsystem zur Erkennung solcher Manipulationsversuche dienen könnte.
Warum Claude seine Werte je nach Frage ändert
Besonders faszinierend war die Entdeckung, dass Claudes ausgedrückte Werte sich kontextabhängig verschieben – ähnlich wie bei uns Menschen.
- Beziehungsrat: Suchten Nutzer Rat in Beziehungsfragen, betonte Claude Werte wie „gesunde Grenzen“ und „gegenseitigen Respekt“.
- Historische Analyse: Ging es um die Analyse historischer Ereignisse, rückte die „historische Genauigkeit“ in den Vordergrund.
Saffron Huang zeigte sich überrascht über Claudes Fokus auf Ehrlichkeit und Genauigkeit: „Zum Beispiel war ‚intellektuelle Bescheidenheit‘ der Top-Wert in philosophischen Diskussionen über KI, ‚Expertise‘ war der Top-Wert bei der Erstellung von Marketinginhalten für die Schönheitsindustrie, und ‚historische Genauigkeit‘ war der Top-Wert bei der Diskussion kontroverser historischer Ereignisse.“
Wie Claude auf Deine Werte reagiert: Zustimmung, Neuordnung oder Widerstand?
Die Studie untersuchte auch, wie Claude auf die vom Nutzer geäußerten Werte reagiert:
- Starke Unterstützung (28,2 %): In mehr als einem Viertel der Gespräche unterstützte Claude die Werte des Nutzers nachdrücklich. Dies könnte Fragen nach einer potenziell übermäßigen Angepasstheit aufwerfen.
- Neuordnung (6,6 %): In einigen Fällen „rahmte“ Claude die Werte des Nutzers neu ein. Das bedeutet, er erkannte sie an, fügte aber neue Perspektiven hinzu – typischerweise bei psychologischer oder zwischenmenschlicher Beratung.
- Aktiver Widerstand (3 %): Am aufschlussreichsten waren die seltenen Fälle, in denen Claude den Werten des Nutzers aktiv widerstand. Die Forscher vermuten, dass dieser Widerstand Claudes „tiefste, unbeweglichste Werte“ offenlegen könnte – analog dazu, wie menschliche Kernwerte oft erst in ethischen Konfliktsituationen deutlich werden.
„Unsere Forschung legt nahe, dass es einige Arten von Werten gibt, wie intellektuelle Ehrlichkeit und Schadensvermeidung, die Claude in normalen Alltagsinteraktionen selten zum Ausdruck bringt, aber wenn es darauf ankommt, verteidigt“, so Huang. „Insbesondere sind es diese Arten von ethischen und wissensorientierten Werten, die tendenziell direkt artikuliert und verteidigt werden, wenn sie herausgefordert werden.“
Ein Blick ins KI-Gehirn: Mechanistische Interpretierbarkeit
Diese Werte-Studie baut auf Anthropics umfassenderen Bemühungen auf, die Blackbox großer Sprachmodelle (LLMs) zu öffnen. Das Stichwort lautet „mechanistische Interpretierbarkeit“ – im Grunde das Reverse-Engineering von KI-Systemen, um ihre inneren Funktionsweisen zu verstehen.
Erst letzten Monat veröffentlichten Anthropic-Forscher eine bahnbrechende Arbeit, bei der sie mithilfe eines metaphorischen „Mikroskops“ Claudes Entscheidungsprozesse verfolgten. Diese Technik offenbarte überraschende Verhaltensweisen: Claude plant beispielsweise beim Dichten voraus und nutzt für einfache Mathematik unkonventionelle Lösungsansätze.
Diese Erkenntnisse stellen gängige Annahmen über die Funktionsweise von LLMs in Frage. Wenn Claude beispielsweise gebeten wurde, seinen Rechenweg zu erklären, beschrieb es eine Standardmethode, nicht aber den tatsächlich intern verwendeten Prozess. Das zeigt, wie KI-Erklärungen von den tatsächlichen Abläufen abweichen können. „Es ist ein Missverständnis, dass wir alle Komponenten des Modells gefunden hätten oder eine Art Gottesperspektive“, sagte Anthropic-Forscher Joshua Batson im März gegenüber MIT Technology Review. „Manche Dinge sind im Fokus, aber andere sind immer noch unklar – eine Verzerrung des Mikroskops.“
Was bedeutet das für Dich als Entscheider im Unternehmen?
Für technische Entscheidungsträger, die KI-Systeme für ihr Unternehmen evaluieren, bietet Anthropics Forschung mehrere wichtige Erkenntnisse:
- Emergente Werte: Aktuelle KI-Assistenten drücken wahrscheinlich Werte aus, die nicht explizit programmiert wurden. Das birgt das Risiko unbeabsichtigter Voreingenommenheiten (Bias) in kritischen Geschäftskontexten.
- Kontextabhängige Ausrichtung: Die Übereinstimmung von KI-Werten mit menschlichen Werten (Alignment) ist keine Ja/Nein-Frage, sondern existiert auf einem Spektrum und variiert je nach Kontext. Das erschwert Entscheidungen zur Einführung von KI, besonders in regulierten Branchen mit klaren Ethik-Richtlinien.
- Notwendigkeit der Überwachung: Die Studie zeigt das Potenzial für eine systematische Bewertung von KI-Werten im tatsächlichen Einsatz, statt sich nur auf Tests vor der Veröffentlichung zu verlassen. Dies könnte ein kontinuierliches Monitoring auf ethische Abweichungen oder Manipulation ermöglichen.
„Indem wir diese Werte in realen Interaktionen mit Claude analysieren, wollen wir Transparenz darüber schaffen, wie sich KI-Systeme verhalten und ob sie wie beabsichtigt funktionieren – wir glauben, dass dies der Schlüssel zur verantwortungsvollen KI-Entwicklung ist“, betonte Huang.
Anthropic hat seinen Werte-Datensatz öffentlich zugänglich gemacht, um weitere Forschung zu fördern. Das Unternehmen, das von Amazon (mit einer Beteiligung im Wert von 14 Mrd. Dollar, insgesamt 8 Mrd. Dollar Investment) und Google (über 3 Mrd. Dollar Investment) unterstützt wird, scheint Transparenz als Wettbewerbsvorteil gegenüber Rivalen wie OpenAI zu nutzen. Während Anthropic nach seiner letzten Finanzierungsrunde mit 61,5 Milliarden Dollar bewertet wird, hat OpenAI (mit Microsoft als Kerninvestor) kürzlich eine 40-Milliarden-Dollar-Runde abgeschlossen, die seine Bewertung auf beeindruckende 300 Milliarden Dollar katapultiert.
Die Grenzen der Methode und der Wettlauf um wertekonforme KI
Obwohl Anthropics Methode einen beispiellosen Einblick bietet, hat sie Grenzen. Die Definition dessen, was als Ausdruck eines Wertes zählt, ist subjektiv. Da Claude selbst an der Kategorisierung beteiligt war, könnten seine eigenen Voreingenommenheiten die Ergebnisse beeinflusst haben. Am wichtigsten ist vielleicht, dass der Ansatz nicht für die Bewertung vor der Bereitstellung verwendet werden kann, da er erhebliche Mengen an realen Gesprächsdaten benötigt.
„Diese Methode ist speziell auf die Analyse eines Modells nach seiner Veröffentlichung ausgerichtet, aber Varianten dieser Methode sowie einige der Erkenntnisse, die wir aus diesem Paper gewonnen haben, können uns helfen, Werteprobleme zu erkennen, bevor wir ein Modell breit ausrollen“, erklärte Huang und fügte hinzu: „Wir arbeiten daran, auf dieser Arbeit aufzubauen, um genau das zu tun, und ich bin optimistisch!“
Fazit: Claudes Werte – Ein Meilenstein mit offenen Fragen für die KI-Moral
Die Anthropic Studie zu den Werten von Claude ist ein bedeutender Schritt hin zu mehr Transparenz und einem besseren Verständnis von KI-Moral und -Ausrichtung. Die Analyse von 700.000 Gesprächen und die daraus resultierende Werte-Taxonomie liefern faszinierende, aber auch beunruhigende Einblicke. Es ist beruhigend zu sehen, dass Claude meist im Sinne seiner Entwickler („hilfreich, ehrlich, harmlos“) agiert, aber die aufgedeckten Anomalien und die kontextabhängige Natur seiner Werte zeigen deutlich, dass die Reise zur wirklich sicheren und wertekonformen KI noch lang ist.
Die Erkenntnis, dass KI-Systeme wie Claude eigene, emergente Werte entwickeln und diese je nach Situation anpassen oder sogar gegen Nutzerwerte verteidigen, unterstreicht die Dringlichkeit der AI Alignment Forschung. Insbesondere die Fähigkeit, durch solche Analysen potenzielle Jailbreaking-Versuche zu erkennen, ist ein wertvolles Werkzeug für die KI-Sicherheit. Für Unternehmen, die KI einsetzen, bedeutet dies, dass eine einmalige Prüfung nicht ausreicht; kontinuierliches Monitoring und ein tiefes Verständnis der kontextuellen Werteausprägungen sind unerlässlich.
Anthropics Ansatz der mechanistischen Interpretierbarkeit und die Veröffentlichung der Daten sind wichtige Schritte in Richtung einer verantwortungsvolleren KI-Entwicklung. Während die Methode ihre Grenzen hat (insbesondere die Anwendbarkeit erst nach dem Deployment), legt sie doch den Grundstein für zukünftige Forschungen und verbesserte Pre-Deployment-Tests.
Letztlich müssen KI-Modelle Werturteile fällen. „Wenn wir wollen, dass diese Urteile mit unseren eigenen Werten übereinstimmen (was letztlich das zentrale Ziel der KI-Alignment-Forschung ist), dann brauchen wir Wege, um zu testen, welche Werte ein Modell in der realen Welt zum Ausdruck bringt“, schlussfolgern die Forscher treffend. Die Anthropic Studie ist ein wichtiger Beitrag auf diesem Weg, der zeigt, wie komplex und dynamisch die KI-Moral ist und wie wichtig es ist, diese kontinuierlich zu erforschen und zu gestalten.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
—
Quellen
- Nuñez, Michael. „Anthropic just analyzed 700,000 Claude conversations — and found its AI has a moral code of its own.“ VentureBeat, April 21, 2025. https://venturebeat.com/ai/anthropic-just-analyzed-700000-claude-conversations-and-found-its-ai-has-a-moral-code-of-its-own/
- Anthropic
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #Claude #Anthropic #AIethics #AIAlignment, Claude Werte Anthropic







