
Die Fähigkeiten von Großen Sprachmodellen (Large Language Models, LLMs) wie ChatGPT, Qwen oder DeepSeek sind beeindruckend und entwickeln sich rasant weiter. Doch um ihr volles Potenzial für spezifische Aufgaben auszuschöpfen und ihr Verhalten präzise auszurichten, ist ein nachträgliches Training, oft als Fine-Tuning bezeichnet, unerlässlich. Genau hier setzt eine vielversprechende neue Methode namens RLSC (Reinforcement Learning via Self-Confidence) an. Diese innovative Technik, vorgestellt von Forschern wie Pengyi Li und seinem Team, verspricht, das LLM Fine-Tuning durch den cleveren Einsatz von KI-Selbstvertrauen effizienter und zugänglicher zu machen, ohne auf kostspielige menschliche Bewertungen oder komplexe externe Belohnungsmodelle angewiesen zu sein. Du fragst dich, wie das funktioniert und welche Vorteile es bringt? Dann lies weiter!
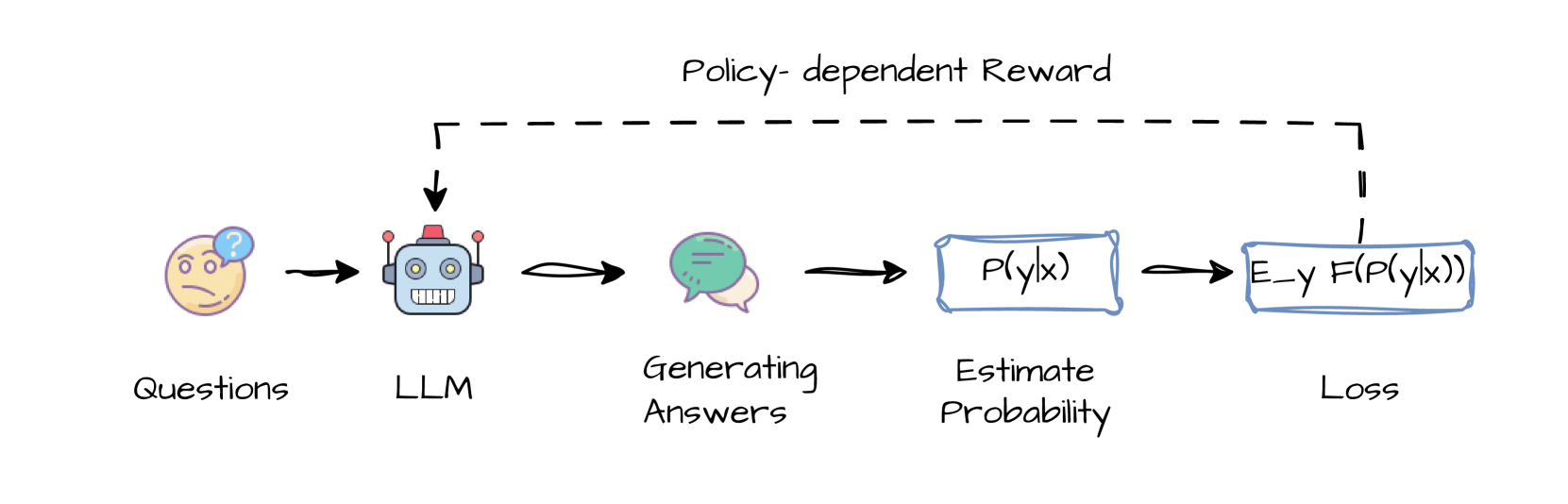
Klingt cool: Ein Sprachmodell könnte sich selbst beibringen, bessere und präzisere Antworten zu generieren, indem es einfach lernt, seinen eigenen Fähigkeiten mehr zu vertrauen. Das klingt fast zu schön, um wahr zu sein, ist aber der Kern von RLSC. Diese Methode nutzt das interne „Selbstvertrauen“ des Modells bezüglich seiner eigenen Antworten als direktes Signal für das Verstärkungslernen (Reinforcement Learning, RL). Anstatt aufwendig manuell gelabelte Daten oder extern definierte Belohnungsfunktionen zu benötigen, lernt das Modell quasi aus sich selbst heraus.
Die Forscher demonstrierten dies eindrucksvoll am Beispiel des Qwen2.5-Math-7B Modells, das speziell für mathematische Aufgaben entwickelt wurde. Mit erstaunlich wenigen Trainingsdaten – lediglich 16 Beispielen pro Frage und nur 10 bis 20 Trainingsschritten – erzielte RLSC beachtliche Verbesserungen auf verschiedenen anspruchsvollen Mathematik-Benchmarks. Diese Entwicklung könnte insbesondere für Szenarien mit begrenzten Ressourcen oder dem Wunsch nach schneller Anpassung von Modellen einen wichtigen Fortschritt für 2025 und darüber hinaus bedeuten.
Das Prinzip ist nicht nur elegant, sondern auch potenziell weitreichend. Es eröffnet Perspektiven für eine schlankere und skalierbarere Nachoptimierung von bereits trainierten Sprachmodellen, die für vielfältige Inferenzaufgaben eingesetzt werden. Wenn ein Modell lernen kann, die Verlässlichkeit seiner Antworten selbst einzuschätzen und zu optimieren, reduziert das die Abhängigkeit von externen Supervisionsquellen und könnte die Demokratisierung von Hochleistungs-KI weiter vorantreiben. Wir tauchen nun tiefer in die Funktionsweise und die beeindruckenden Ergebnisse dieser Methode ein.
Das musst Du wissen – RLSC auf den Punkt gebracht
- Innovatives Prinzip: RLSC nutzt das eigene Vertrauen (Self-Confidence) des Sprachmodells in seine generierten Antworten als primäres Belohnungssignal für das Reinforcement Learning.
- Keine externen Labels nötig: Die Methode eliminiert die Notwendigkeit für teure menschliche Annotationen, Präferenzmodelle oder aufwendig gestaltete externe Belohnungsfunktionen, was das LLM Fine-Tuning erheblich vereinfacht.
- Signifikante Leistungssteigerung: Selbst mit minimalem Trainingsaufwand (z.B. nur 16 Samples pro Frage) zeigt RLSC deutliche Verbesserungen der Genauigkeit auf anspruchsvollen Benchmarks, etwa +21,7% auf Minerva Math für das Qwen2.5-Math-7B Modell, basierend auf dem KI-Selbstvertrauen.
- Effizient und ressourcenschonend: RLSC ist als eine einfache, skalierbare Methode konzipiert, die nur wenige Trainingsbeispiele und -schritte erfordert (Few-Shot Learning) und ohne gelabelte Supervision auskommt.
- Breite Anwendbarkeit: Der Ansatz hat das Potenzial, die Nachtrainingsphase für diverse Inferenzmodelle zu optimieren und die Entwicklung präziserer KI-Systeme zu beschleunigen.
Das Problem: Warum traditionelles LLM-Training an Grenzen stößt
Große Sprachmodelle (LLMs) wie die der Qwen- oder DeepSeek-Familie haben bemerkenswerte Fähigkeiten im logischen Denken und der Bearbeitung komplexer Aufgaben bewiesen. Doch ihre „rohe“ Leistung nach dem Pre-Training ist oft noch nicht optimal auf spezifische Ziele oder die Präferenzen der Nutzer ausgerichtet. Daher ist eine Phase des Post-Trainings, meist durch Feinabstimmung (Fine-Tuning), entscheidend. Methoden wie Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO) und insbesondere Reinforcement Learning from Human Feedback (RLHF) sind hier gängige Verfahren. RLHF beispielsweise richtet Modelle stark an menschlichen Präferenzen aus, was jedoch einen enormen Aufwand für die Erstellung von Annotationen durch Menschen bedeutet und somit sehr kostspielig ist. Andere Ansätze, wie DeepSeeks GRPO-Algorithmus, setzen auf belohnungsgesteuertes Lernen zur Verbesserung des logischen Denkens.
Auch wenn diese Methoden Fortschritte gebracht haben, bleibt die Abhängigkeit von aufwendig gelabelten Datensätzen oder sorgfältig entwickelten, externen Belohnungsfunktionen eine große Hürde. Nehmen wir das Beispiel Test-Time Reinforcement Learning (TTRL): Hier werden für jede Frage typischerweise 64 Antworten generiert, um durch Mehrheitsentscheid sogenannte Pseudo-Labels zu erzeugen. Das ist zwar effektiv, führt aber zu einem sehr hohen Rechenaufwand. Es besteht also ein klarer Bedarf an effizienteren Wegen, um das LLM Fine-Tuning zu gestalten und die Modelle besser auf ihre Aufgaben vorzubereiten, ohne dabei in Kosten- oder Ressourcenfallen zu tappen.
RLSC im Detail: Wie funktioniert das Lernen durch KI-Selbstvertrauen?
Genau hier kommt Reinforcement Learning via Self-Confidence (RLSC) ins Spiel. Die Entwickler dieser Methode haben sich gefragt, was das grundlegende Prinzip hinter Ansätzen wie dem Majority Voting bei TTRL ist. Ihre Einsicht: Intuitiv wählt das Majority Voting den wahrscheinlichsten Output (den Modus) der Antwortverteilung des Modells aus. Optimiert man also auf die Übereinstimmung zwischen verschiedenen generierten Antworten, „schärft“ man implizit diese Verteilung. Das bedeutet, die Wahrscheinlichkeitsmasse konzentriert sich stärker auf die wahrscheinlichste Antwort. RLSC macht sich diese Erkenntnis zunutze und ersetzt die externe Pseudo-Label-Erstellung durch ein direktes, internes Optimierungsziel basierend auf diesem „Mode Sharpening“.
Das Ziel ist es, die Wahrscheinlichkeit zu maximieren, dass zwei unabhängige Antworten des Modells auf dieselbe Eingabe identisch sind. Mathematisch ausgedrückt (ohne hier tief in die Formeln einzusteigen) maximiert man eine Funktion, die am größten wird, wenn das Modell sehr „überzeugt“ von einer bestimmten Antwort ist. Das KI-Selbstvertrauen wird also direkt zum Lehrer. Der Kern der Methode ist eine Verlustfunktion (Loss Function), die höhere logarithmische Wahrscheinlichkeiten für Antworten fördert, denen das Modell (in einer früheren, „eingefrorenen“ Version, p_old genannt) bereits hohes Vertrauen zugewiesen hat. Bemerkenswert ist dabei:
- Es wird kein externes Belohnungsmodell benötigt.
- Es sind keine gelabelten Daten erforderlich.
- Es wird ausschließlich die „Glaubensverteilung“ des Modells selbst als Feedback genutzt.
Die Forscher haben auch eine leicht modifizierte Version dieser Verlustfunktion entwickelt, die durch Hinzufügen einer kleinen Konstante (alpha) die Optimierung stabilisiert, besonders wenn die ursprüngliche Vertrauensverteilung des Modells sehr spitz oder dünn besetzt ist. Diese kleine Anpassung verbessert empirisch sowohl die Konvergenz als auch die Generalisierungsfähigkeit des Modells.
Praktisches Trainings-Setup für RLSC
Um die Wirksamkeit von RLSC zu demonstrieren, wandten die Forscher die Methode auf das Qwen2.5-Math-7B Modell an. Der Trainingsprozess ist erstaunlich schlank:
- Generierung von Kandidatenantworten: Für jede Trainingsfrage generiert das Basismodell eine kleine Anzahl von Antwortkandidaten – konkret 16 Samples pro Frage bei einer festen Temperatur (ein Parameter, der die Zufälligkeit der Antworten steuert). Diese Samples werden als unabhängige Ziehungen aus der Verteilung des „alten“ Modells (p_old) behandelt.
- Berechnung der Log-Wahrscheinlichkeiten: Für jedes dieser Samples wird seine Log-Wahrscheinlichkeit unter dem aktuell zu trainierenden Modell (p_theta) berechnet.
- Anwendung der Verlustfunktion: Die gewichtete Verlustfunktion (entweder die Basisversion oder die geglättete Version) wird ausgewertet. Hierbei werden nur die Token (also Wörter oder Wortteile) der Antwort berücksichtigt, nicht die der Eingabefrage.
- Modellupdate: Die Modellparameter werden über Backpropagation basierend auf diesem Verlust aktualisiert.
Das Training erfolgte für lediglich 10 oder 20 Schritte auf dem AIME2024 Datensatz, unter Einsatz von 8 NVIDIA A100 GPUs (mit je 80GB Speicher). Als Optimierer diente AdamW mit einer Lernrate von 1×10⁻⁵ und standardmäßiger Gewichtungsreduktion (Weight Decay). Die maximale Länge der generierten Antworten war auf 3072 Token begrenzt. Dieses minimale Setup – ohne zusätzliche Datensätze, ohne Instruktions-Tuning, ohne Präferenzmodelle – ermöglicht ein effizientes, Zero-Label Reinforcement Learning und das selbst für große Modelle.
Beeindruckende Ergebnisse: RLSC in der Praxis
Die mit RLSC erzielten Verbesserungen sind überzeugend, insbesondere wenn man den geringen Trainingsaufwand berücksichtigt. Die Evaluation erfolgte auf einer Reihe anspruchsvoller Benchmark-Datensätze, darunter mathematische Denkaufgaben (AIME24, MATH500, AMC23, GSM8K), Minerva Math, Olympiadbench, MMLU Stem (ein Teilbereich des MMLU-Benchmarks, der sich auf Naturwissenschaften, Technologie, Ingenieurwesen und Mathematik konzentriert) und das Frage-Antwort-Benchmark GPQADiamond. Die Genauigkeit wurde als Verhältnis der korrekt beantworteten Samples zur Gesamtzahl der Samples definiert.
Für eine faire Vergleichbarkeit wurden sowohl die mit RLSC optimierten Modelle als auch die Basismodelle (Qwen2.5-Math-1.5B und Qwen2.5-Math-7B) mit demselben öffentlich verfügbaren Evaluationsskript unter identischen Bedingungen neu bewertet.
Ergebnisse für Qwen2.5-Math-7B (Auswahl):
| Benchmark | Basismodell (%) | Mit RLSC (%) | Verbesserung (Δ) |
| AIME24 | 13,3 | 26,7 | +13,4% |
| MATH500 | 51,4 | 72,6 | +21,2% |
| AMC23 | 45,0 | 54,7 | +9,7% |
| GSM8K | 84,3 | 86,3 | +2,0% |
| GPQA Diamond | 21,4 | 24,1 | +2,7% |
| Olympiadbench | 15,1 | 35,9 | +20,8% |
| Minerva Math | 10,7 | 32,4 | +21,7% |
| MMLU Stem | 52,3 | 57,6 | +5,3% |
(Die Tabelle zeigt Genauigkeitswerte in Prozent. Höhere Werte sind besser.)
Es wird deutlich, dass das originale Qwen-Modell bei direkter Evaluierung teilweise erhebliche Schwierigkeiten hatte. Die RLSC-Methode baut auf dieser Basis auf und erzielt durch die gezielte Stärkung des KI-Selbstvertrauens substanzielle Verbesserungen. Besonders hervorzuheben sind die Zuwächse auf den Kern-Benchmarks AIME24, MATH500, Olympiadbench, Minerva Math und AMC23, wobei der Vorteil beim größeren 7B-Parameter-Modell mit einer Verbesserung von 21,7% für Minerva Math besonders ausgeprägt ist. Interessanterweise zeigten sich auch beim kleineren Qwen2.5-Math-1.5B Modell signifikante Steigerungen, beispielsweise +26,8% auf MATH500 und +14,7% auf Minerva Math durch LLM Fine-Tuning mit RLSC.
Qualitative Beobachtungen: Mehr als nur Zahlen
Ein spannender Nebeneffekt des RLSC-Fine-Tunings war, dass die Modelle begannen, kürzere und präzisere Antworten zu produzieren. Im Gegensatz zu traditionellen Ansätzen, die oft textuelle Hinweise wie „Lass uns Schritt für Schritt denken“ (Let’s think step by step) verwenden, um ausführliche Lösungswege zu generieren, lernten die mit RLSC trainierten Modelle, Antworten früher zu identifizieren und redundante Denkprozesse zu vermeiden.
In einem Beispiel aus dem AIME-Benchmark (Case 1 im Paper) zeigte das Basismodell langwierige symbolische Ableitungen und scheiterte dennoch an der korrekten Lösung. Das mit RLSC angepasste Modell hingegen beantwortete die Frage direkt und korrekt, mit einem klareren logischen Fluss. Ähnliche Muster zeigten sich auch in anderen Mathematik-Benchmarks wie MATH und AMC23. Obwohl die Reduktion der Antwortlänge nicht formal quantifiziert wurde, ist dieser Trend konsistent. Dies deutet darauf hin, dass RLSC implizit die Glaubwürdigkeit und Effizienz von Zwischenschritten im Denkprozess des Modells verbessern kann.
Diese qualitativen Analysen, bei denen die Forscher die Denkprozesse des ursprünglichen und des feinabgestimmten Modells verglichen, untermauern die Ergebnisse. Das feinabgestimmte Modell zeigte ein verbessertes Aufgabenverständnis und bessere Schlussfolgerungsfähigkeiten im Zero-Shot-Setting (d.h. ohne spezifische Beispiele für die gestellte Aufgabe im Training gesehen zu haben). Während das Basismodell bei einigen Aufgaben nur fehlerhafte grundlegende Überlegungen anstellen konnte oder bei komplexeren Problemen komplett versagte, zeigte das mit RLSC optimierte Modell starke Denkfähigkeiten und gelangte über einfachere Denkpfade zu korrekten Schlussfolgerungen – ganz ohne die Notwendigkeit langatmiger „Schritt-für-Schritt“-Herleitungen.
RLSC im Kontext: Einordnung und Abgrenzung zu anderen Methoden
Um die Neuheit und den Beitrag von RLSC vollständig zu verstehen, lohnt ein Blick auf verwandte Arbeiten im Bereich Reinforcement Learning für Denkaufgaben und das Test-Time Training.
- Reinforcement Learning from Human Feedback (RLHF): Ein klassischer Ansatz, der Modellverhalten an menschliche Präferenzen anpasst. Wie bereits erwähnt, ist RLHF stark von arbeitsintensiven Annotationen abhängig und daher teuer.
- Reinforcement Learning with Verifiable Rewards (RLVR): Dieser Ansatz reduziert die Abhängigkeit von annotierten Denkschritten, indem er Belohnungen basierend auf Frage-Antwort-Paaren vergibt. Das Modell generiert eine Antwort, die mit einer Referenzantwort verglichen wird. RLVR benötigt aber immer noch von Menschen gelabelte Fragen und Antworten.
- Test-Time Training (TTT): Eine neuere Richtung, die darauf abzielt, das Modellverhalten während der Inferenzzeit weiter zu optimieren. Beispiele hierfür sind:
- SelfPlay Critic (SPC) und Absolute Zero Reasoner (AZR): Diese nutzen adversarielle Dual-Modell-Frameworks, inspiriert von spieltheoretischem Lernen. Ein Modell generiert herausfordernde Denkpfade, das andere kritisiert sie. Diese Methoden benötigen keine menschliche Supervision, sind aber oft auf externe Werkzeuge (z.B. Python-Interpreter oder Code-Verifizierer) für Feedback-Signale angewiesen.
- Test-Time Reinforcement Learning (TTRL): Wie zuvor skizziert, konstruiert TTRL Pseudo-Labels durch Sampling vieler Antworten und Mehrheitsentscheid. Obwohl es keine explizite menschliche Supervision benötigt, ist der Rechenaufwand durch die hohe Anzahl benötigter Samples (z.B. 64 pro Frage) beträchtlich.
Zusammenfassend lässt sich sagen, dass bestehende Methoden wie RLHF, RLVR, SPC, AZR und TTRL zwar unterschiedliche Strategien zur Generierung von Verstärkungssignalen vorschlagen, aber fast immer auf einer Kombination aus menschlichen Annotationen, externen (Belohnungs-)Modellen oder komplexem Belohnungs-Engineering beruhen. RLSC bricht mit dieser Abhängigkeit, indem es das KI-Selbstvertrauen als endogene Signalquelle nutzt und damit einen wesentlich schlankeren und potenziell effizienteren Weg für das LLM Fine-Tuning aufzeigt. Es formalisiert das implizite Ziel des „Mode Sharpening“, das dem Majority Voting bei TTRL zugrunde liegt, und macht es direkt für ein selbst-supervidiertes Training nutzbar.
Fazit: Das Potenzial von RLSC für die Zukunft der KI
Die Einführung von Reinforcement Learning via Self-Confidence (RLSC) markiert einen faszinierenden und potenziell sehr wichtigen Schritt in der Evolution des Trainings von Großen Sprachmodellen. Die Methode adressiert zentrale Herausforderungen im Bereich des LLM Fine-Tuning, insbesondere die oft hohen Kosten und den Aufwand, die mit der Generierung von menschlichen Labels oder der Entwicklung komplexer externer Belohnungsmodelle verbunden sind. Indem RLSC auf das KI-Selbstvertrauen setzt – also die Fähigkeit des Modells, die Zuverlässigkeit seiner eigenen Antworten intern zu bewerten und dieses Signal für die Optimierung zu nutzen – eröffnet es einen Pfad zu effizienterem, ressourcenschonenderem und skalierbarerem Post-Training.
Die von Pengyi Li und Kollegen präsentierten Ergebnisse sind beeindruckend: Signifikante Genauigkeitssteigerungen auf anspruchsvollen Benchmarks wie AIME2024, MATH500 und Minerva Math, erzielt mit dem Qwen2.5-Math-7B Modell bei minimalem Trainingsaufwand (lediglich 16 Samples pro Frage und 10-20 Trainingsschritte), sprechen eine klare Sprache. Dies unterstreicht das enorme Potenzial von RLSC, insbesondere in Szenarien, in denen Trainingsdaten rar oder teuer sind. Die Fähigkeit, mit „Few-Shot Learning“ und ohne explizit gelabelte Supervisionsdaten auszukommen, ist ein entscheidender Vorteil.
Was RLSC besonders elegant macht, ist die mathematische Formalisierung des Prinzips, das anderen Methoden wie TTRL (Test-Time Reinforcement Learning) implizit zugrunde liegt. Statt auf rechenintensive Mehrheitsabstimmungen über viele generierte Antworten zu setzen, transformiert RLSC das Konzept des „Mode Sharpening“ – also der Konzentration der Antwortwahrscheinlichkeit auf die plausibelste Ausgabe – in ein direkt optimierbares, selbst-supervidiertes Lernziel. Diese Herangehensweise, bei der das Modell lernt, seiner „besten Einschätzung“ stärker zu vertrauen, führt nicht nur zu quantitativen Verbesserungen, sondern auch zu qualitativ besseren Antworten: Sie werden präziser und vermeiden unnötige Umwege, wie die Beobachtungen zum „Concise Reasoning“ zeigen.
Für die Zukunft bedeutet dies, dass die Optimierung von Sprachmodellen weniger von externen, oft subjektiven oder schwer zu definierenden Belohnungsfunktionen abhängig sein könnte. Stattdessen könnte das interne „Wissen“ und die „Selbsteinschätzung“ vortrainierter Modelle stärker genutzt werden, um ihre Leistung auf nachgelagerten Aufgaben zu verbessern. RLSC bietet hierfür nicht nur ein praktisches Werkzeug, sondern auch eine konzeptionelle Brücke zwischen ensemble-basierten Pseudo-Labeling-Ansätzen und prinzipiengeleiteter Selbst-Supervision.
Während die Autoren andeuten, dass weitere Untersuchungen, beispielsweise zur genauen Charakterisierung bestimmter Hyperparameter oder der optimalen Anzahl von Samples, zukünftigen Arbeiten vorbehalten bleiben, sind die bisherigen Resultate ein starkes Indiz dafür, dass hochqualitatives Post-Training nicht zwingend aus externen Labels erwachsen muss. Es kann auch aus dem sorgfältig abgeleiteten internen Signal eines Modells entstehen. Für Anwender und Entwickler von KI-Systemen könnte RLSC somit im Jahr 2025 und darüber hinaus eine wertvolle, ressourceneffiziente Methode darstellen, um Sprachmodelle noch leistungsfähiger und zielgerichteter zu machen. Die Demokratisierung des Zugangs zu Spitzen-KI rückt damit wieder ein Stück näher.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
- Li, P., Skripkin, M., Zubrey, A., Kuznetsov, A., & Oseledets, I. (2024). Confidence Is All You Need: Few-Shot RL Fine-Tuning of Language Models. arXiv:2506.06395 [cs.CL]. Verfügbar unter: https://arxiv.org/abs/2506.06395
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #RLSC #LLMFineTuning #SelbstvertrauenKI #MaschinellesLernen, Reinforcement Learning via Self-Confidence







