
Stell dir vor, du könntest jedes Video, egal ob Film, Spiel oder Smartphone-Clip, mit unglaublicher Präzision bearbeiten und den Hintergrund perfekt vom Vordergrund trennen. Genau das ermöglicht MatAnyone, ein innovatives Framework für Video Matting. Bisherige Methoden hatten oft Schwierigkeiten mit komplexen Hintergründen oder uneindeutigen Situationen. MatAnyone hingegen setzt auf eine neue Technik namens „Consistent Memory Propagation“, die es erlaubt, stabile und detailreiche Ergebnisse zu erzielen.
Dieses System merkt sich Informationen aus vorherigen Frames und integriert sie intelligent, um sowohl die Kernbereiche als auch feine Details an den Rändern präzise zu erfassen. Das Ergebnis ist ein sauberes, professionelles Video Matting, das selbst anspruchsvollste Aufgaben meistert. Aber wie funktioniert das genau und was macht MatAnyone so besonders?
In diesem Artikel tauchen wir tief in die Welt von MatAnyone ein, erklären die zugrunde liegenden Technologien und zeigen, warum es die Zukunft des Video Matting sein könnte. Wir werden uns die innovative Architektur, die Trainingsmethoden und die beeindruckenden Ergebnisse ansehen, die mit diesem Framework erzielt wurden. Mach dich bereit für eine spannende Reise in die Welt der künstlichen Intelligenz und Videobearbeitung!
Das musst Du wissen – MatAnyone: Revolutionäres Video Matting
- MatAnyone ist ein neues Framework für Video Matting, das sich auf Target Assignment konzentriert und stabile Ergebnisse liefert.
- Die Consistent Memory Propagation sorgt für semantische Stabilität in Kernbereichen und feine Details an Objekträndern.
- Ein neuer, hochwertiger Datensatz und eine innovative Trainingsstrategie verbessern die Stabilität des Mattings erheblich.
- MatAnyone übertrifft bestehende Methoden in diversen realen Szenarien.
- Das System ermöglicht interaktives Video Matting durch einfache Zuweisung des Zielobjekts im ersten Frame.
Hauptfrage: Was macht MatAnyone zu einer bahnbrechenden Lösung für Video Matting und wie überwindet es die Limitierungen bisheriger Methoden, um in komplexen realen Szenarien herausragende Ergebnisse zu erzielen?
Folgefragen (FAQs)
- Wie funktioniert die Consistent Memory Propagation (CMP) in MatAnyone im Detail?
- Welche Vorteile bietet der neue VM800-Datensatz gegenüber bestehenden Datensätzen wie VideoMatte240K?
- Wie trägt die neuartige Trainingsstrategie von MatAnyone zur Stabilität und Genauigkeit des Mattings bei?
- In welchen realen Anwendungsszenarien kann MatAnyone besonders gut eingesetzt werden?
- Wie schneidet MatAnyone im Vergleich zu anderen State-of-the-Art-Methoden wie RVM, AdaM und MaGGIe ab?
- Kann MatAnyone auch für interaktives Video Matting verwendet werden und wenn ja, wie?
- Wie trägt die Region-Adaptive Memory Fusion zur Stabilität in Kernregionen und zur Detailgenauigkeit an den Grenzen bei?
- Welche Rolle spielt die Scaled DDC Loss in der Trainingsstrategie und wie verbessert sie die Ergebnisse?
Antworten auf jede Frage
Wie funktioniert die Consistent Memory Propagation (CMP) in MatAnyone? (Einfach erklärt!)
Stell dir vor, MatAnyone hat ein super Gedächtnis für jedes einzelne Bild (Frame) in deinem Video. Anstatt sich nur zu merken, wo genau ein Objekt ist, speichert es, wie durchsichtig oder undurchsichtig jedes einzelne Pixel in diesem Bild ist – das nennt man die Alpha Matte.
Jetzt kommt der Clou: MatAnyone weiß, dass sich manche Dinge im Video stark verändern (z.B. ein wehendes Haar) und andere kaum (z.B. der Körper einer Person).
- Wenn sich etwas stark verändert: Schaut MatAnyone in seinem aktuellen „Gedächtnis“, was dort gerade passiert.
- Wenn sich etwas kaum verändert: Vertraut MatAnyone auf sein vorheriges „Gedächtnis“ und behält die alten Informationen bei.
Diese clevere Kombination aus aktuellem und altem „Gedächtnis“ sorgt dafür, dass das Video-Matting super stabil und detailreich wird. Stell es dir wie eine Mischung aus kurzfristigem und langfristigem Gedächtnis vor, die perfekt zusammenarbeiten!
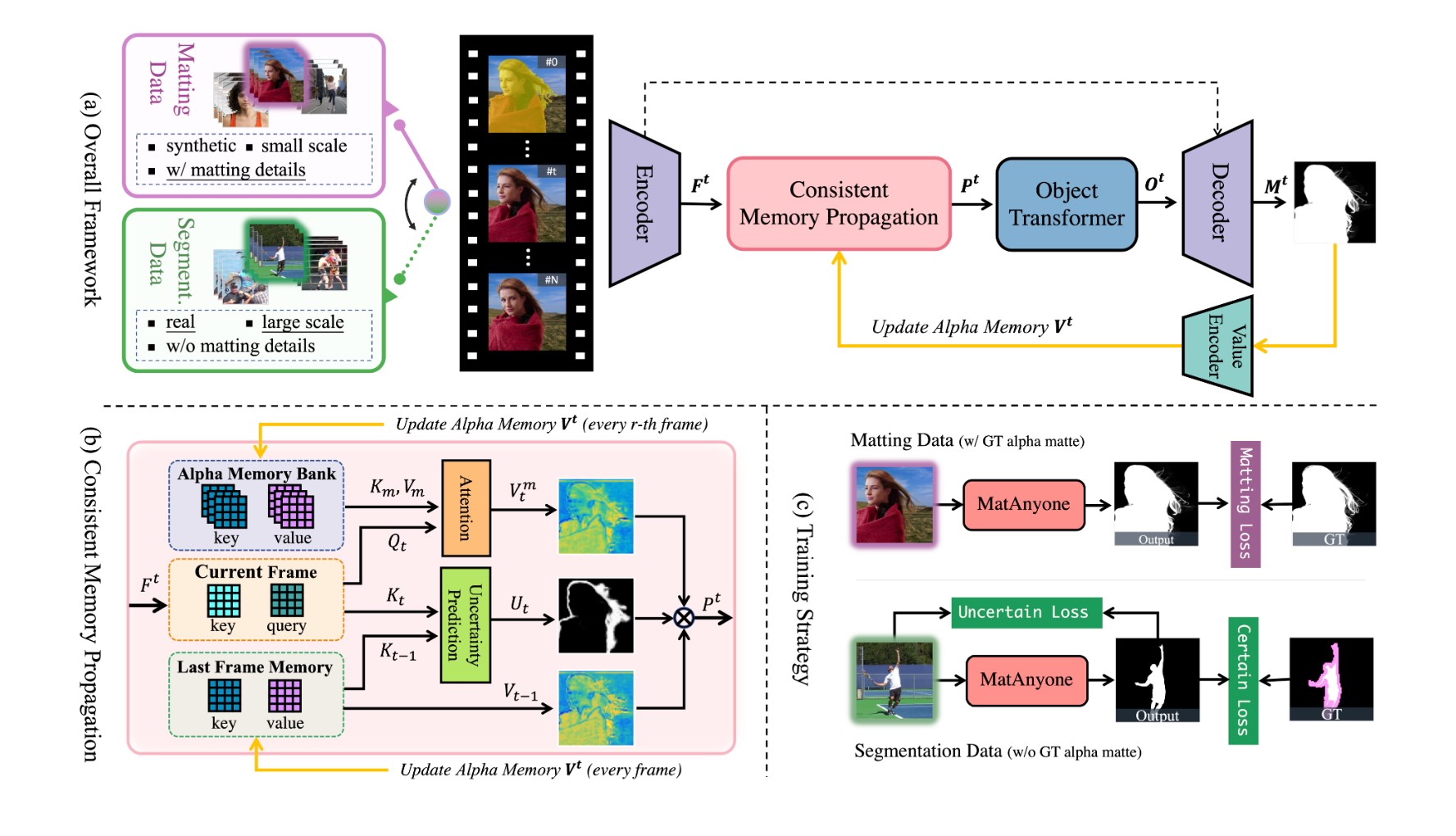
Wie funktioniert die Consistent Memory Propagation (CMP) in MatAnyone im Detail?
Die Consistent Memory Propagation (CMP) ist das Herzstück von MatAnyone. Sie basiert auf einem Memory-Bank-System, das Informationen aus vorherigen Frames speichert. Anstatt nur Segmentation Masks oder Trimaps zu speichern, speichert MatAnyone die Alpha Matte im Alpha Memory Bank. Das Ziel ist, die Stabilität, die das Memory-Paradigma bietet, besser zu nutzen.
Das System unterscheidet zwischen Kernbereichen (Background und sicherer Vordergrund) und Randbereichen. Die Region-Adaptive Memory Fusion schätzt für jedes Token (einzelne Informationseinheit) die Wahrscheinlichkeit, dass sich der Alpha-Wert im Vergleich zum vorherigen Frame geändert hat. Regionen mit grossen Änderungen verlassen sich stärker auf die Informationen des aktuellen Frames aus dem Memory Bank, während Regionen mit geringen Änderungen das Gedächtnis des vorherigen Frames beibehalten. Dies geschieht durch die Boundary-Area Prediction, welche mit Convolution Layern durchgeführt wird.
Diese adaptive Fusion stabilisiert die Memory Propagation und verbessert die Qualität des Mattings. Die Formel für die Pixel Memory Readout lautet:
Pt = Vtm * Ut + Vt-1 * (1 – Ut)
Dabei ist Ut die Wahrscheinlichkeit für Änderungen, Vtm die aktuellen Werte aus dem Memory Bank und Vt-1 die Werte aus dem vorherigen Frame.
Welche Vorteile bietet der neue VM800-Datensatz gegenüber bestehenden Datensätzen wie VideoMatte240K?
Der VM800-Datensatz wurde entwickelt, um die Einschränkungen des VideoMatte240K-Datensatzes zu überwinden. Er ist doppelt so groß, diverser in Bezug auf Frisuren, Outfits und Bewegungen und bietet eine höhere Qualität. Insbesondere wurden gängige Artefakte, die in VideoMatte240K vorhanden sind, manuell entfernt.
Die Vorteile lassen sich wie folgt zusammenfassen:
- Größere Datenmenge: Mehr Daten führen in der Regel zu besseren und robusteren Modellen.
- Höhere Diversität: Eine größere Vielfalt an Szenarien und Objekten ermöglicht es dem Modell, besser zu generalisieren.
- Bessere Qualität: Die manuellen Korrekturen und die Auswahl hochwertigerer Videos tragen zu einer höheren Genauigkeit bei.
Wie trägt die neuartige Trainingsstrategie von MatAnyone zur Stabilität und Genauigkeit des Mattings bei?
Die Trainingsstrategie von MatAnyone zielt darauf ab, die Stärken von Video Matting-Daten und realen Segmentierungsdaten zu kombinieren. Anstatt separate Köpfe für Matting und Segmentierung zu verwenden (wie bei RVM), wird das Matting direkt mit Segmentierungsdaten überwacht.
Die Herausforderung besteht darin, dass für Segmentierungsdaten keine Ground Truth Alpha Mattes vorhanden sind. Daher wird die Scaled DDC Loss verwendet. Für Kernbereiche wird eine einfache L1-Loss (Lcore) verwendet. Für Randbereiche kommt die Scaled DDC Loss (Lboundary) zum Einsatz. Diese Loss-Funktion berücksichtigt die Unterschiede zwischen Vordergrund- und Hintergrundwerten und erzeugt natürlichere Matting-Ergebnisse als die ursprüngliche DDC Loss.
In welchen realen Anwendungsszenarien kann MatAnyone besonders gut eingesetzt werden?
MatAnyone eignet sich hervorragend für alle Anwendungen, in denen eine präzise Trennung von Vordergrund und Hintergrund in Videos erforderlich ist. Dazu gehören:
- Virtuelle Hintergründe: Nahtlose Integration von Personen in virtuelle Umgebungen.
- Videokonferenzen: Entfernen oder Ersetzen von Hintergründen in Echtzeit.
- Filme und Spezialeffekte: Erstellung realistischer Spezialeffekte.
- Gaming: Integration von Spielern in Spielumgebungen.
- Interaktive Anwendungen: Anwendungen, bei denen Benutzer den Hintergrund interaktiv verändern können.
- Portrait videography and photography.
Wie schneidet MatAnyone im Vergleich zu anderen State-of-the-Art-Methoden wie RVM, AdaM und MaGGIe ab?
MatAnyone übertrifft in verschiedenen Benchmarks (VideoMatte, YouTubeMatte) sowohl Auxiliary-Free-Methoden (MODNet, RVM) als auch Mask-Guided-Methoden (AdaM, FTP-VM, MaGGIe). Es erzielt bessere Ergebnisse in Bezug auf MAD (Mean Absolute Difference), MSE (Mean Squared Error), Grad (Spatial Gradient), Conn (Connectivity) und dtSSD (Temporal Coherence). Besonders hervorzuheben ist die überlegene Generalisierbarkeit in realen Szenarien.
Kann MatAnyone auch für interaktives Video Matting verwendet werden und wenn ja, wie?
Ja, MatAnyone ist ideal für interaktives Video Matting geeignet. Durch die Zuweisung des Zielobjekts im ersten Frame (Target Assignment) kann das System das Objekt im gesamten Video stabil verfolgen. Dies ermöglicht es Benutzern, den Vordergrund zu isolieren und den Hintergrund nach Belieben zu bearbeiten. Die ersten Zuweisungen lassen sich mithilfe von Promptable Segmentation Methoden mit wenigen Klicks erledigen.
Wie trägt die Region-Adaptive Memory Fusion zur Stabilität in Kernregionen und zur Detailgenauigkeit an den Grenzen bei?
Die Region-Adaptive Memory Fusion ist entscheidend für die Leistung von MatAnyone. Durch die Unterscheidung zwischen Kern- und Randbereichen kann das System die Stabilität in den Kernbereichen aufrechterhalten und gleichzeitig feine Details an den Grenzen erfassen. Die adaptive Gewichtung der Informationen aus dem aktuellen und vorherigen Frame sorgt für ein ausgewogenes Ergebnis.
Welche Rolle spielt die Scaled DDC Loss in der Trainingsstrategie und wie verbessert sie die Ergebnisse?
Die Scaled DDC Loss ermöglicht es, das Matting-Modell direkt mit Segmentierungsdaten zu trainieren, auch wenn keine Ground Truth Alpha Mattes vorhanden sind. Im Vergleich zur ursprünglichen DDC Loss berücksichtigt die Scaled Version die Unterschiede zwischen Vordergrund- und Hintergrundwerten, was zu natürlicheren Matting-Ergebnissen führt. Dies vermeidet segmentierungsartige Zacken und Treppeneffekte an den Rändern.
Konkrete Tipps und Anleitungen
Obwohl MatAnyone primär für die Forschung und Entwicklung gedacht ist, gibt es doch einige Tipps und Anleitungen, wie man das Konzept und die Technologie in der Praxis nutzen kann.
Tipps für die Nutzung von MatAnyone-ähnlichen Prinzipien:
- Nutze Memory-basierte Systeme: Auch wenn du MatAnyone nicht direkt verwenden kannst, solltest du in Betracht ziehen, Memory-basierte Systeme für deine Videobearbeitungsprojekte zu nutzen. Das Speichern und Wiederverwenden von Informationen aus vorherigen Frames kann die Stabilität und Konsistenz verbessern.
- Achte auf hochwertige Daten: Die Qualität deiner Trainingsdaten ist entscheidend. Wenn du eigene Matting-Modelle trainierst, investiere Zeit in die Erstellung eines diversen und qualitativ hochwertigen Datensatzes.
- Kombiniere verschiedene Datenquellen: Nutze die Stärken verschiedener Datenquellen. Kombiniere Video Matting-Daten mit realen Segmentierungsdaten, um die Stabilität und Genauigkeit deiner Modelle zu verbessern.
- Experimentiere mit Loss-Funktionen: Die Wahl der richtigen Loss-Funktion kann einen großen Einfluss auf die Ergebnisse haben. Experimentiere mit verschiedenen Loss-Funktionen, wie der Scaled DDC Loss, um die Leistung deiner Modelle zu optimieren.
- Berücksichtige Kern- und Randbereiche: Bei der Entwicklung von Matting-Algorithmen solltest du die unterschiedlichen Anforderungen von Kern- und Randbereichen berücksichtigen. Eine adaptive Behandlung dieser Bereiche kann die Stabilität und Detailgenauigkeit verbessern.
Anleitung zur Erstellung eines eigenen Matting-Datensatzes (VM800-ähnlich):
- Sammle Green Screen Videos: Sammle eine große Anzahl von Green Screen Videos mit unterschiedlichen Personen, Frisuren, Outfits und Bewegungen.
- Verwende Adobe After Effects: Nutze Adobe After Effects oder eine ähnliche Software, um die Videos zu bearbeiten und die Hintergründe zu entfernen.
- Führe eine manuelle Auswahl durch: Überprüfe die Ergebnisse sorgfältig und entferne alle Videos mit Artefakten oder Mängeln.
- Erstelle Segmentierungsmasken: Generiere Frame-weise Segmentierungsmasken als Ground Truth für Kernbereiche.
- Stelle sicher, dass deine Matting-Daten qualitativ sind.
Regelmäßige Aktualisierung
Dieser Artikel wird regelmäßig aktualisiert, um sicherzustellen, dass die Informationen über MatAnyone und verwandte Technologien auf dem neuesten Stand sind. Schau regelmäßig vorbei, um über die neuesten Fortschritte und Entwicklungen informiert zu bleiben.
Wer steckt hinter MatAnyone?
MatAnyone wurde von einem Team aus Forschern des S-Lab der Nanyang Technological University und von SenseTime Research entwickelt.
- Nanyang Technological University (NTU): Eine renommierte Universität in Singapur, die für ihre Forschung in den Bereichen Ingenieurwissenschaften und Technologie bekannt ist. Das S-Lab an der NTU konzentriert sich auf Forschung im Bereich Computer Vision und Bildverarbeitung.
- SenseTime Research: SenseTime ist eines der weltweit führenden Unternehmen im Bereich künstliche Intelligenz, insbesondere in den Bereichen Gesichtserkennung, Bildanalyse und Deep Learning. SenseTime Research betreibt Forschungs- und Entwicklungszentren auf der ganzen Welt und arbeitet an innovativen KI-Lösungen für verschiedene Branchen. Mehr über Sense Time und deren KI-Modelle findest Du hier.
Die Köpfe hinter MatAnyone:
- Peiqing Yang, Shangchen Zhou, Jixin Zhao, Chen Change Loy (Nanyang Technological University)
- Qingyi Tao (SenseTime Research)
Dieses Team aus Experten hat seine Expertise in den Bereichen Computer Vision, Deep Learning und Videobearbeitung gebündelt, um MatAnyone zu entwickeln – ein Framework, das die Grenzen des Video Mattings neu definiert.
Fazit: MatAnyone – Der nächste Schritt im Video Matting für KI-gestützte Inhalte
MatAnyone stellt einen bedeutenden Fortschritt im Bereich des Video Mattings dar. Durch die innovative Consistent Memory Propagation, den hochwertigen VM800-Datensatz und die neuartige Trainingsstrategie überwindet es die Einschränkungen bisheriger Methoden und liefert stabile, detailreiche Ergebnisse in komplexen realen Szenarien. Das Framework bietet nicht nur eine verbesserte Leistung im Vergleich zu State-of-the-Art-Methoden wie RVM, AdaM und MaGGIe, sondern eröffnet auch neue Möglichkeiten für interaktives Video Matting.
Die Region-Adaptive Memory Fusion und die Scaled DDC Loss tragen entscheidend zur Stabilität in Kernregionen und zur Detailgenauigkeit an den Grenzen bei. Dies ermöglicht eine präzisere Trennung von Vordergrund und Hintergrund, was in einer Vielzahl von Anwendungen von Vorteil ist, darunter virtuelle Hintergründe, Videokonferenzen, Filme, Spiele und interaktive Anwendungen.
MatAnyone ist ein vielversprechendes Framework, das das Potenzial hat, die Art und Weise, wie wir Videos bearbeiten und erstellen, grundlegend zu verändern. Es ebnet den Weg für KI-gestützte Inhalte, die realistischer, immersiver und interaktiver sind als je zuvor. Die hier dargestellten Prinzipien der Memory-basierten Systeme, hochwertigen Trainingsdaten und adaptiven Algorithmen können auch in anderen Bereichen der Bild- und Videobearbeitung angewendet werden, um ähnliche Fortschritte zu erzielen. Insgesamt bietet MatAnyone eine solide Grundlage für zukünftige Forschung und Entwicklung im Bereich des Video Mattings und darüber hinaus.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar. Hier kannst Du Dich in einer aktiven Community austauschen und KI lernen.
Quellen
- MatAnyone Paper: https://arxiv.org/html/2501.14677v1
- Projektseite
Über den Autor
Ich bin Oliver Welling, 57, und beschäftige mich mit Chatbots, seit ich ELIZA 1987 zum ersten Mal erlebt habe. Seit knapp zwei Jahren arbeite ich an den KINEWS24.de – jeden Tag gibt es die neuesten News und die besten KI-Tools – und eben auch: Jede Menge AI-Science. KI erlebe ich als Erweiterung meiner Fähigkeiten und versuche, mein Wissen zu teilen.
Prinzipiell glaube ich, dass wir etwas zu viel in die USA schauen, wenn es um KI geht. Alibaba, ByteDance, Sensetime, DeepSeek vieles, sehr vieles kommt inzwischen aus China. Ich bin Demokrat aus Leidenschaft – Autokratien lehne ich persönlich ab. Die Leistungen, die hier immer wieder gezeigt werden, nötigen mir aber sehr viel Respekt ab. China: Ein globlaer KI-Player wird noch immer viel zu oft unterschätzt.









