
OpenAI Deep Research System Card: OpenAI ist massiv unter Druck – kaum anders lässt sich erklären, warum aktuell so viel Neues von dem ChatGPT-Hersteller kommt. Die rasante Entwicklung im Bereich der Künstlichen Intelligenz (KI) bringt nicht nur unglaubliche Möglichkeiten, sondern auch neue Herausforderungen mit sich, besonders im Bereich der Sicherheit. OpenAI hat mit der „Deep Research System Card“ einen detaillierten Einblick in ihre Sicherheitsmaßnahmen für ein neues, agentenbasiertes KI-Modell namens „Deep Research“ gegeben.
Dieses Modell ist darauf ausgelegt, komplexe Recherchen im Internet durchzuführen und dabei große Mengen an Informationen zu verarbeiten. Aber wie stellt OpenAI sicher, dass solche leistungsstarken Werkzeuge sicher und verantwortungsvoll eingesetzt werden? In diesem Artikel werfen wir einen tiefen Blick in die Deep Research System Card und beleuchten die vielfältigen Sicherheitsvorkehrungen, die OpenAI getroffen hat, um potenzielle Risiken zu minimieren. Wir zeigen dir, welche Gefahren identifiziert wurden, welche Maßnahmen ergriffen wurden und wie OpenAI die Sicherheit dieses neuen KI-Modells evaluiert hat.
Wirklich spannend: Erst vor 10 Tagen hat OpenAI die Model Specs veröffentlicht – und nun kommt gleich die OpenAI Deep Research System Card. Kaum Zehn Tage später. Da wir seit kurzem von OpenAI wissen, dass ChatGPT-4.5 und ChatGPT 5 noch in diesem Jahr erscheinen werden, freuen wir uns jetzt mit Euch genau auf die System Card zu schauen! Bleib dran, um zu erfahren, wie OpenAI die Grenzen der KI-Sicherheit neu definiert und was das für die Zukunft der KI-gestützten Forschung bedeutet.
Das musst Du wissen – OpenAI Deep Research System Card
- Deep Research ist ein neues, agentenbasiertes KI-Modell von OpenAI, das für komplexe Recherchen im Internet entwickelt wurde.
- OpenAI hat umfangreiche Sicherheitstests durchgeführt, darunter externes Red Teaming und Frontier Risk Evaluations, um potenzielle Risiken zu identifizieren und zu minimieren.
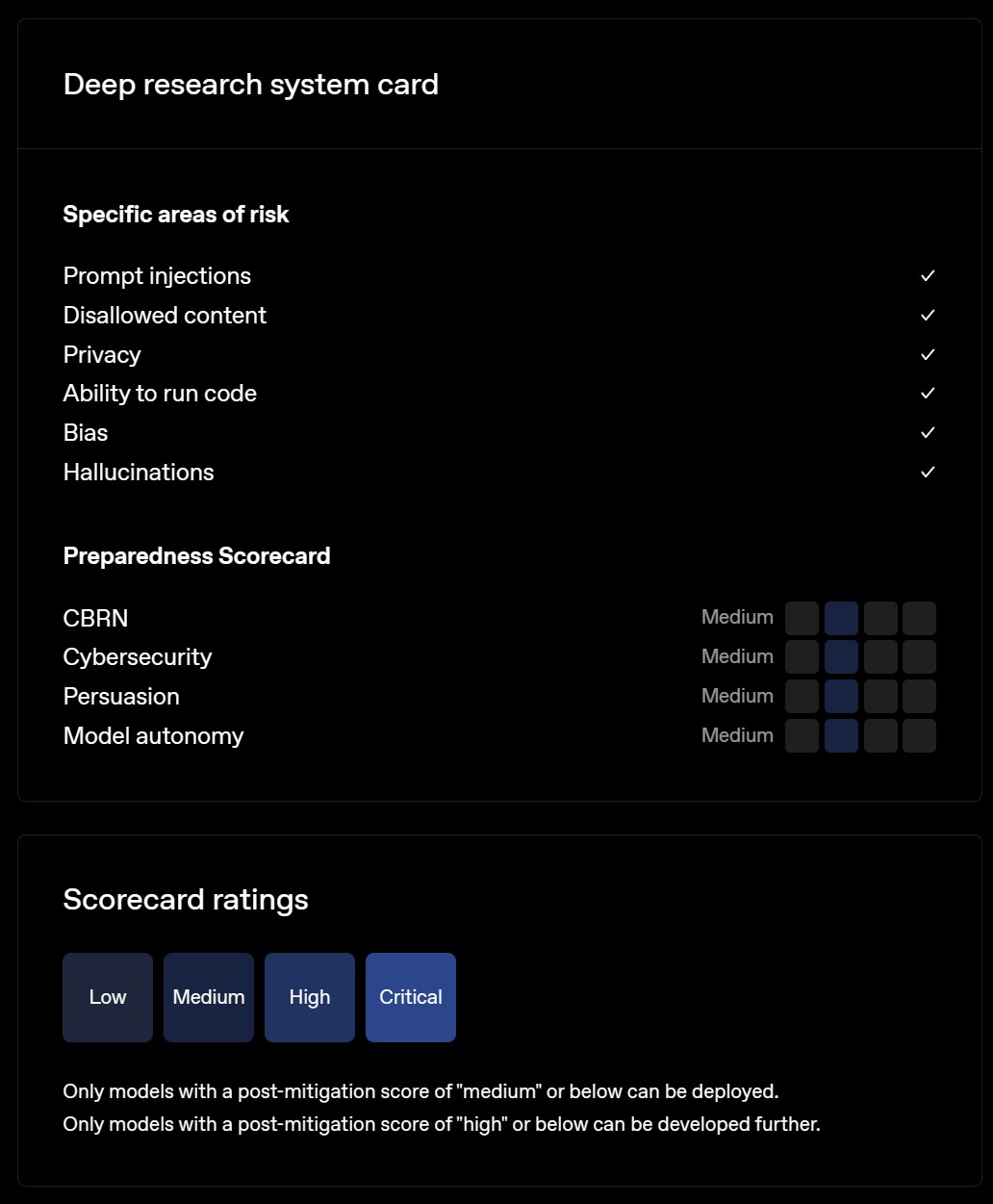
- Die System Card beschreibt detailliert die wichtigsten Risikobereiche wie Prompt Injections, Disallowed Content, Privacy, Ability to Run Code, Bias und Hallucinations.
- OpenAI hat verschiedene Mitigationen implementiert, darunter Post-Training, Blocklists, Output Classifiers und Sandboxed Coding Environments, um die identifizierten Risiken zu adressieren.
- Die Preparedness Framework Evaluations zeigen, dass Deep Research in den Risikokategorien CBRN, Cybersecurity, Persuasion und Model Autonomy als „Medium Risk“ eingestuft wird, was strenge Sicherheitsmaßnahmen erfordert.
Hauptfrage
Wie stellt OpenAI mit der „Deep Research System Card“ sicher, dass ihr neues KI-Modell „Deep Research“ trotz seiner Fähigkeit zu komplexen Internetrecherchen sicher und verantwortungsvoll eingesetzt werden kann, und welche spezifischen Maßnahmen wurden ergriffen, um die identifizierten Risiken zu minimieren?
Folgefragen (FAQs)
- Welche spezifischen Risikobereiche wurden im Rahmen der Deep Research System Card identifiziert?
- Welche Mitigationen hat OpenAI implementiert, um Prompt Injections bei Deep Research zu verhindern?
- Wie geht OpenAI mit dem Risiko von Disallowed Content um, das Deep Research im Internet finden könnte?
- Welche Maßnahmen wurden ergriffen, um die Privatsphäre im Kontext von Deep Research zu schützen?
- Wie wird die Fähigkeit von Deep Research, Code auszuführen, in einer sicheren Umgebung gehandhabt?
- Welche Schritte unternimmt OpenAI, um Bias in den Antworten von Deep Research zu reduzieren?
- Wie minimiert OpenAI das Risiko von Halluzinationen bei Deep Research, insbesondere bei webbasierten Recherchen?
- Was ist das Preparedness Framework von OpenAI und wie wurde es zur Bewertung von Deep Research eingesetzt?
- Welche Ergebnisse lieferten die Preparedness Framework Evaluations für Deep Research in Bezug auf Cybersecurity und CBRN-Risiken?
- Inwiefern beeinflusst die Fähigkeit von Deep Research zum Web-Browsing die Kontaminationsrisiken bei der Evaluation der Modellfähigkeiten?
- Welche Maßnahmen ergreift OpenAI, um Browser-basierte Kontaminationen bei der Evaluation von Deep Research zu adressieren?
- Wie schneidet Deep Research im Vergleich zu früheren OpenAI-Modellen in Bezug auf Sicherheitsmetriken ab?
- Welche Implikationen hat die Einstufung von Deep Research als „Medium Risk“ im Preparedness Framework?
- Welche nächsten Schritte plant OpenAI, um die Sicherheit und Verantwortlichkeit von Deep Research weiter zu verbessern?
- Wie können Nutzer und die Öffentlichkeit von den Erkenntnissen und Transparenzbemühungen profitieren, die in der Deep Research System Card dokumentiert sind?
Antworten auf jede Frage
Welche spezifischen Risikobereiche wurden im Rahmen der Deep Research System Card identifiziert?
OpenAI hat im Rahmen der Deep Research System Card eine umfassende Risikoanalyse durchgeführt und dabei sechs Hauptrisikobereiche identifiziert, die mit der Fähigkeit von Deep Research zu komplexen Internetrecherchen verbunden sind:
- Prompt Injections: Da Deep Research Informationen sowohl aus Benutzerinteraktionen als auch aus dem Internet bezieht, besteht das Risiko, dass bösartige Akteure schädliche Anweisungen in Online-Inhalte einschleusen. Das Modell könnte diese Anweisungen fälschlicherweise befolgen und beispielsweise falsche Antworten geben oder sensible Daten preisgeben. OpenAI beschreibt dies als eine Form des „Prompt Injection“-Angriffs, bei dem ein Angreifer einen feindseligen Prompt in externe Inhalte einfügt, der die Benutzeranweisungen überschreibt.
- Disallowed Content: Die Fähigkeit von Deep Research, das Web zu durchsuchen und Informationen zu verarbeiten, birgt das Risiko, dass das Modell unerwünschte Inhalte generiert. Dies kann detaillierte Anleitungen für gefährliche oder gewalttätige Aktivitäten, Ratschläge zu sensiblen Themen oder Informationen in einem Detaillierungsgrad umfassen, der ansonsten nicht von Modellen bereitgestellt würde. Ein konkretes Beispiel, das OpenAI nennt, ist die Identifizierung von Social-Media- und Kommunikationskanälen von Gruppen, die Gewalt fördern.
- Privacy (Privatsphäre): Im Internet sind umfangreiche persönliche Informationen verfügbar. Deep Research könnte diese Informationen aus verschiedenen Quellen zusammentragen und kombinieren, um ein umfassendes Bild einer Person zu erstellen, was potenziell missbraucht werden könnte. Dies stellt ein neuartiges Risiko dar, da das Modell die Zusammenstellung persönlicher Informationen aus verschiedenen Online-Quellen erleichtern kann.
- Ability to Run Code (Fähigkeit, Code auszuführen): Wie GPT-4o in ChatGPT verfügt auch Deep Research über ein Python-Tool, um Code auszuführen. Dies ermöglicht dem Modell, komplexe Recherchen durchzuführen, die Datenanalyse und Berechnungen umfassen. Ohne entsprechende Sicherheitsvorkehrungen könnte dies jedoch Cybersicherheitsrisiken und andere Gefahren bergen, insbesondere wenn die Codeausführungsumgebung direkt mit dem Internet verbunden wäre.
- Bias (Verzerrung): Modelle können unerwünschte Verzerrungen in ihren Interaktionen mit Nutzern zeigen, was Objektivität und Fairness beeinträchtigen kann. Im Fall von Deep Research könnte die starke Abhängigkeit von Online-Suchen das Verhalten des Modells in Bezug auf Verzerrungen beeinflussen.
- Hallucinations (Halluzinationen): Modelle können faktisch falsche Informationen generieren, was je nach Anwendung schädliche Folgen haben kann. Red Teamer stellten fest, dass Deep Research in seinen Gedankengängen Halluzinationen über den Zugriff auf bestimmte externe Tools oder native Fähigkeiten zeigte.
Welche Mitigationen hat OpenAI implementiert, um Prompt Injections bei Deep Research zu verhindern?
Um das Risiko von Prompt Injections bei Deep Research zu minimieren, hat OpenAI mehrere Mitigationen implementiert, die in zwei Hauptkategorien fallen:
- Safety Training Data: OpenAI hat neue Safety Training Data erstellt, um die Anfälligkeit des Modells für Prompt Injections zu reduzieren. Diese Daten helfen dem Modell, bösartige Anweisungen zu erkennen und abzulehnen, die in externe Inhalte eingeschleust werden könnten.
- System-Level Mitigations: Zusätzlich zum Training hat OpenAI systemweite Maßnahmen implementiert, um die Wahrscheinlichkeit der Datenexfiltration durch Prompt Injections zu verringern. Eine wichtige Maßnahme ist die Beschränkung der Fähigkeit von Deep Research, zu beliebigen URLs zu navigieren oder diese zu konstruieren. Dies verhindert, dass das Modell sensible Informationen wie API-Schlüssel in URL-Parameter einfügt und potenziell nach außen kommuniziert.
Konkret werden folgende Mitigationen gegen Prompt Injections in der System Card aufgeführt:
- Post-Training: Durch Post-Training-Verfahren wird das Modell weiter auf Sicherheit getrimmt und die Resistenz gegen Prompt Injections erhöht.
- Verhinderung der Navigation zu beliebigen URLs: Deep Research ist eingeschränkt in seiner Fähigkeit, beliebige URLs zu erstellen und anzusteuern. Dies ist eine zentrale Maßnahme, um das Risiko der Datenexfiltration über manipulierte URLs zu begrenzen.
OpenAI hat diese Maßnahmen evaluiert und in Tabellenform die Erfolgsraten von Angriffen vor und nach der Implementierung der Mitigationen verglichen. Die Ergebnisse zeigen eine signifikante Reduktion der Erfolgsraten von Prompt-Injection-Angriffen nach der Implementierung der Mitigationen, sowohl für textbasierte als auch für multimodale Angriffe. Dennoch betont OpenAI, dass ein Restrisiko besteht und kontinuierliche Anstrengungen unternommen werden, um die Modelle robuster gegen diese Art von Angriffen zu machen.
Wie geht OpenAI mit dem Risiko von Disallowed Content um, das Deep Research im Internet finden könnte?
OpenAI adressiert das Risiko von Disallowed Content durch ein mehrschichtiges System von Mitigationen, das sowohl auf Trainingsebene als auch durch technische Filter und Überwachung implementiert wird:
- Post-Training: Wie bei Prompt Injections spielt Post-Training auch hier eine wichtige Rolle. Das Modell wird darauf trainiert, Anfragen nach unerwünschten Inhalten abzulehnen und angemessene Sicherheitsantworten zu generieren. OpenAI hat seine Safety Policies und Safety Datasets aktualisiert und das Deep Research Modell weiter trainiert, um Anfragen nach Disallowed Content zu verweigern.
- Blocklist: OpenAI verwendet Blocklists, um den Zugriff auf bekannte Quellen für unerwünschte Inhalte zu verhindern. Diese Listen werden kontinuierlich aktualisiert, um neue Bedrohungen zu berücksichtigen.
- Output Classifiers: Output Classifiers werden eingesetzt, um die Ausgaben des Modells zu analysieren und unerwünschte Inhalte zu erkennen. Diese Classifier können verschiedene Kategorien von Disallowed Content identifizieren und entsprechende Maßnahmen auslösen.
- Output Filters: Output Filters ergänzen die Classifiers, indem sie unerwünschte Inhalte in den Ausgaben des Modells filtern und entfernen. Dies kann die vollständige Blockierung der Antwort oder die Zensur bestimmter Textteile umfassen.
- Abuse Monitoring and Enforcement: OpenAI setzt auf Abuse Monitoring, um die Nutzung von Deep Research auf Verstöße gegen die Nutzungsrichtlinien zu überwachen. Bei Verstößen werden entsprechende Maßnahmen ergriffen, um den Missbrauch zu unterbinden und durchzusetzen.
OpenAI hat die Wirksamkeit dieser Maßnahmen evaluiert, indem es Deep Research mit anderen Modellen (GPT-4o, OpenAI o1-mini, o1) verglichen hat. Die Ergebnisse zeigen, dass Deep Research eine gute Performance bei der Vermeidung von Disallowed Content aufweist und gleichzeitig Overrefusal (das Ablehnen harmloser Anfragen) minimiert. Zusätzlich wurden „Challenge Tests“ durchgeführt, um die Modelle an schwierigeren Szenarien zu testen. Auch hier zeigte Deep Research eine robuste Performance.
Welche Maßnahmen wurden ergriffen, um die Privatsphäre im Kontext von Deep Research zu schützen?
OpenAI hat im Bereich Datenschutz mehrere Maßnahmen ergriffen, um die Privatsphäre der Nutzer und den Schutz persönlicher Informationen im Kontext von Deep Research zu gewährleisten:
- Post-Training: Das Modell wird darauf trainiert, Anfragen nach privaten oder sensiblen Informationen abzulehnen, selbst wenn diese Informationen im Internet öffentlich zugänglich sind. Dies umfasst beispielsweise die Weigerung, private Wohnadressen preiszugeben. OpenAI hat seine bestehenden Modellrichtlinien zum Schutz persönlicher Daten aktualisiert und neue Safety Data und Evaluations speziell für Deep Research entwickelt.
- Blocklist: Ähnlich wie beim Disallowed Content werden Blocklists auch im Bereich Datenschutz eingesetzt, um den Zugriff auf bekannte Quellen für sensible persönliche Informationen zu verhindern.
- Abuse Monitoring and Enforcement: Auch im Bereich Datenschutz setzt OpenAI auf Abuse Monitoring, um die Nutzung von Deep Research auf Datenschutzverletzungen zu überwachen und durchzusetzen.
Die System Card betont, dass OpenAI seit langem Modelle darauf trainiert, Anfragen nach privaten Informationen abzulehnen. Für Deep Research wurden diese Maßnahmen jedoch nochmals verstärkt und spezifische Evaluationen entwickelt, um die Einhaltung der Datenschutzrichtlinien zu überprüfen. OpenAI misst die Einhaltung seiner Datenschutzrichtlinien anhand von synthetisch generierten Prompts und manuell erstellten „Golden Examples“. Die Evaluationsergebnisse zeigen, dass Deep Research eine hohe Adhärenz an die Datenschutzrichtlinien aufweist, insbesondere im Vergleich zu einer „Rails Free“-Version des Modells.
Wie wird die Fähigkeit von Deep Research, Code auszuführen, in einer sicheren Umgebung gehandhabt?
Um die Risiken im Zusammenhang mit der Codeausführungsfähigkeit von Deep Research zu minimieren, hat OpenAI auf eine „Sandboxed Coding Environment“ gesetzt:
- No Access to Internet (Kein Internetzugang): Die Python-Tool-Umgebung, in der Deep Research Code ausführt, hat keinen direkten Zugriff auf das Internet. Dies ist eine zentrale Sicherheitsmaßnahme, um zu verhindern, dass das Modell über Codeausführung Schadcode herunterlädt oder mit externen Systemen interagiert, die potenziell Schaden anrichten könnten.
- Sandboxed Coding Environment (Sandboxed Code-Umgebung): Die Codeausführung erfolgt in einer isolierten, sandboxed Umgebung. Dies bedeutet, dass der ausgeführte Code keinen Zugriff auf das zugrundeliegende System oder andere Ressourcen außerhalb der Sandbox hat. Sollte der Code bösartig sein oder Fehler enthalten, ist der Schaden auf die Sandbox begrenzt.
Diese Maßnahmen sind analog zu den Sicherheitsvorkehrungen, die auch für GPT-4o getroffen wurden. Durch die Isolation der Codeausführungsumgebung stellt OpenAI sicher, dass die Fähigkeit von Deep Research, Code zu schreiben und auszuführen, nicht zu Cybersicherheitsrisiken oder anderen unerwünschten Folgen führt.
Welche Schritte unternimmt OpenAI, um Bias in den Antworten von Deep Research zu reduzieren?
OpenAI geht das Problem von Bias in den Antworten von Deep Research mit ähnlichen Strategien an wie bei anderen Modellen:
- Post-Training: Post-Training-Verfahren werden eingesetzt, um Bias-reduzierende Antworten zu fördern und das Modell davon abzuhalten, verzerrte Ausgaben zu produzieren. Dies kann beispielsweise durch Reward-Systeme im Reinforcement Learning geschehen, die Antworten belohnen, die weniger stereotyp sind und Fairness zeigen.
Um Bias zu evaluieren, hat OpenAI das Deep Research Modell dem BBQ-Benchmark (Bias Benchmark for Question Answering) unterzogen. Dieser Test misst die Neigung des Modells zu Stereotypen, indem er bewertet, wie wahrscheinlich es ist, stereotype Antworten auszuwählen oder Unsicherheit anzuzeigen, wenn es mit mehrdeutigen Situationen konfrontiert wird.
Die Evaluationsergebnisse zeigen, dass Deep Research in Bezug auf Stereotypen ähnlich wie OpenAI o1-preview abschneidet. Es ist weniger wahrscheinlich, stereotype Optionen zu wählen als GPT-4o und zeigt eine vergleichbare Performance wie die OpenAI o1-Serie Modelle. In Fällen, in denen die Frage eindeutig ist und eine klare korrekte Antwort existiert, wählt Deep Research in 95% der Fälle die richtige Antwort. Allerdings zeigt Deep Research, ähnlich wie o1-preview, eine geringere Wahrscheinlichkeit, die Antwort „Unknown“ für mehrdeutige Fragen zu wählen, was zu einer reduzierten Genauigkeit in diesen Fällen führt. OpenAI interpretiert dies jedoch nicht unbedingt als Indikator für eine stärkere Stereotypenneigung von Deep Research im Vergleich zu GPT-4o.
Wie minimiert OpenAI das Risiko von Halluzinationen bei Deep Research, insbesondere bei webbasierten Recherchen?
Um das Risiko von Halluzinationen (faktisch falsche Informationen) bei Deep Research zu minimieren, setzt OpenAI auf folgende Ansätze:
- Heavy Reliance on Online Search (Starke Abhängigkeit von Online-Suche): Die Architektur von Deep Research ist so konzipiert, dass sie stark auf Online-Suchen basiert. Durch die Verifizierung von Informationen über das Web soll die Wahrscheinlichkeit von Halluzinationen reduziert werden. Das Modell ist darauf ausgelegt, Fakten aus dem Internet zu beziehen und seine Antworten auf diese Informationen zu stützen.
- Post-Training: Auch hier spielen Post-Training-Verfahren eine Rolle, um die Faktentreue des Modells zu erhöhen und es davon abzuhalten, falsche Informationen auszugeben. Reinforcement Learning kann beispielsweise eingesetzt werden, um Modelle zu belohnen, die faktisch korrekte Antworten liefern und Halluzinationen vermeiden.
- Linking to Inline Sources for Verification (Verlinkung zu Inline-Quellen zur Verifizierung): Eine wichtige Mitigation ist die Verlinkung zu Inline-Quellen. Deep Research ist in der Lage, seine Antworten mit Verweisen auf die Quellen zu versehen, aus denen die Informationen stammen. Dies ermöglicht es Nutzern, die Fakten zu überprüfen und die Glaubwürdigkeit der Antwort zu beurteilen.
Zur Evaluation von Halluzinationen verwendet OpenAI das PersonQA-Dataset, das 18 Kategorien von Fakten über Personen enthält. Die Evaluationsergebnisse zeigen, dass Deep Research im Vergleich zu früheren Modellen eine signifikant höhere Genauigkeit aufweist und weniger zu Halluzinationen neigt. OpenAI räumt jedoch ein, dass die gemessene Halluzinationsrate möglicherweise überschätzt wird, da in einigen Fällen korrekte Antworten als Halluzinationen gewertet wurden, weil die Informationen im Testdatensatz veraltet waren. Zukünftige Evaluationen sollen dies berücksichtigen und die Antworten noch sorgfältiger prüfen.
Was ist das Preparedness Framework von OpenAI und wie wurde es zur Bewertung von Deep Research eingesetzt?
Das Preparedness Framework von OpenAI ist ein lebendiges Dokument, das beschreibt, wie OpenAI katastrophale Risiken von Frontier Models verfolgt, evaluiert, prognostiziert und dagegen schützt. Es dient als Rahmenwerk für die Bewertung und das Management von Risiken, die mit immer leistungsfähigeren KI-Modellen einhergehen. Das Framework deckt derzeit vier Risikokategorien ab:
- Cybersecurity: Risiken im Zusammenhang mit der Nutzung des Modells für Cyberangriffe.
- CBRN (Chemical, Biological, Radiological, Nuclear): Risiken im Zusammenhang mit der Erstellung von Bedrohungen im CBRN-Bereich.
- Persuasion (Persuasion): Risiken im Zusammenhang mit der Fähigkeit des Modells zur Überzeugung und Manipulation.
- Model Autonomy (Modellautonomie): Risiken im Zusammenhang mit der autonomen Entscheidungsfindung und dem Verhalten des Modells.
Im Rahmen des Preparedness Frameworks werden Indikatoren verwendet, die experimentelle Evaluationsergebnisse potenziellen Risikoleveln zuordnen (Low, Medium, High, Critical). Das Safety Advisory Group von OpenAI überprüft diese Indikatorenbewertungen und legt für jede Kategorie ein Risikolevel fest. Modelle mit einem Post-Mitigation-Score von „Medium“ oder niedriger können eingesetzt werden, während Modelle mit einem Score von „High“ oder höher nur weiterentwickelt, aber nicht eingesetzt werden dürfen.
Deep Research wurde gemäß dem Preparedness Framework evaluiert, um die potenziellen Risiken in den genannten Kategorien zu bewerten. OpenAI hat dabei sowohl eine Pre-Mitigation-Version (Modell vor zusätzlichen Sicherheitsmaßnahmen) als auch eine Post-Mitigation-Version (finales, veröffentlichtes Modell mit allen Sicherheitsmaßnahmen) von Deep Research getestet. Die Evaluationsmethoden wurden an die spezifischen Fähigkeiten von Deep Research angepasst, einschließlich der Fähigkeit zum Web-Browsing.
Welche Ergebnisse lieferten die Preparedness Framework Evaluations für Deep Research in Bezug auf Cybersecurity und CBRN-Risiken?
Die Preparedness Framework Evaluations für Deep Research ergaben in den Kategorien Cybersecurity und CBRN folgende Ergebnisse:
- Cybersecurity: Deep Research wurde in der Kategorie Cybersecurity als „Medium Risk“ eingestuft. Die Evaluationen basierten auf Capture the Flag (CTF) Challenges, bei denen das Modell seine Fähigkeiten zur Identifizierung und Ausnutzung von Schwachstellen in Computersystemen unter Beweis stellen musste. Deep Research zeigte signifikante Fortschritte in Bezug auf die Fähigkeit zur Ausnutzung realer Schwachstellen, erreichte aber nicht die Schwelle für „High Risk“. OpenAI betont, dass CTF-Challenges nicht die Komplexität realer Cyberoperationen vollständig abbilden, aber dennoch wertvolle Einblicke in die Fähigkeiten des Modells liefern. Es ist das erste Mal, dass ein Modell im Bereich Cybersecurity als „Medium Risk“ eingestuft wurde, was die signifikanten Fortschritte in diesem Bereich unterstreicht.
- CBRN (Chemical, Biological, Radiological, Nuclear): Auch im Bereich CBRN, insbesondere bei der Erstellung biologischer Bedrohungen, wurde Deep Research als „Medium Risk“ eingestuft. Die Evaluationen konzentrierten sich auf die Fähigkeit des Modells, Experten bei der operationellen Planung zur Reproduktion bekannter biologischer Bedrohungen zu unterstützen. OpenAI stellte fest, dass Deep Research Experten in diesem Bereich bereits helfen kann und dass Modelle sich der Schwelle nähern, bei der sie auch Novizen in die Lage versetzen könnten, biologische Bedrohungen zu erzeugen, was ein „High Risk“ darstellen würde. Daher intensiviert OpenAI seine Sicherheitsmaßnahmen und investiert in weitere, anspruchsvollere Evaluationen in diesem Bereich. Der Fokus liegt hier auf biologischen und chemischen Bedrohungen, da diese im Vergleich zu radiologischen und nuklearen Bedrohungen niedrigere Einstiegshürden aufweisen.
In den Kategorien Persuasion und Model Autonomy wurde Deep Research ebenfalls als „Medium Risk“ eingestuft. Insgesamt führte dies zu einer Gesamtbewertung von „Medium Risk“ für Deep Research im Preparedness Framework.
Inwiefern beeinflusst die Fähigkeit von Deep Research zum Web-Browsing die Kontaminationsrisiken bei der Evaluation der Modellfähigkeiten?
Die Fähigkeit von Deep Research, das Internet tiefgreifend zu durchsuchen, führt zu neuen Herausforderungen bei der Evaluation der Modellfähigkeiten, insbesondere im Hinblick auf Kontaminationsrisiken. Kontamination tritt auf, wenn das Modell bei der Evaluation auf Informationen zugreift, die ihm eigentlich nicht zur Verfügung stehen sollten, z. B. Lösungen zu Evaluationsaufgaben oder Hinweise darauf. Dies kann die Evaluationsergebnisse verfälschen und die tatsächlichen Fähigkeiten des Modells überbewerten.
Im Fall von Deep Research kann das Modell durch das Browsen im Internet potenziell auf eine Vielzahl von Informationen zugreifen, die die Evaluationsergebnisse beeinflussen könnten. Dies umfasst:
- Verfügbare Lösungen: Wenn Lösungen zu Evaluationsaufgaben oder Teile davon online verfügbar sind (z. B. in Online-Foren, Repositories oder Pastebins), könnte Deep Research diese finden und verwenden, um Aufgaben zu lösen, ohne die eigentliche Fähigkeit zu demonstrieren, die evaluiert werden soll.
- Hinweise und Diskussionsforen: Auch Online-Diskussionen und Hinweise zu Evaluationsaufgaben können die Ergebnisse beeinflussen, indem sie dem Modell unerwünschte Hilfestellungen geben.
- Rubriken und Gold-Solution Software: Wenn Bewertungsrubriken oder „Gold-Solution Software“ online veröffentlicht werden, könnten diese ebenfalls zur Kontamination beitragen.
Diese Kontaminationsrisiken sind besonders relevant für Evaluationsbereiche wie Cybersecurity CTF-Challenges oder CBRN-Evaluations, bei denen Lösungen oder relevante Informationen möglicherweise online zu finden sind.
Welche Maßnahmen ergreift OpenAI, um Browser-basierte Kontaminationen bei der Evaluation von Deep Research zu adressieren?
Um Browser-basierte Kontaminationen bei der Evaluation von Deep Research zu begegnen, verfolgt OpenAI einen zweigleisigen Ansatz:
- Kontaminationsprävention und -quantifizierung:
- Blockierung von Antwortseiten: OpenAI investiert in die Blockierung des Zugriffs auf Websites, die Evaluationsantworten enthalten könnten. Dies soll verhindern, dass das Modell direkt auf Lösungen zugreift.
- Kontaminations-Classifier: Es werden Classifier entwickelt, um den Einfluss von Browser-basierter Kontamination auf Evaluationsergebnisse zu quantifizieren. Diese Classifier sollen erkennen, inwieweit das Modell bei bestimmten Evaluationsaufgaben auf kontaminierte Informationen zugegriffen hat.
- Analyse von Zugriffsmustern: OpenAI analysiert die Zugriffsmuster des Modells während der Evaluation, um Hinweise auf Kontamination zu finden (z. B. Zugriff auf Seiten mit Lösungen).
- Entwicklung uncontaminierter Evaluations:
- In-House Evaluations: OpenAI setzt verstärkt auf Evaluations, die vollständig in-house entwickelt werden und garantiert frei von Internetkontamination sind. Dies umfasst Evaluations, die von OpenAI-Mitarbeitern oder Drittanbietern erstellt und nie veröffentlicht wurden.
- Gold Standard Evaluations: Das Ziel ist die Entwicklung neuer, vollständig uncontaminierter Evaluations, die als „Gold Standard“ für die Bewertung von Modellen wie Deep Research dienen können.
Für Cybersecurity CTF-Evaluations hat OpenAI beispielsweise Analysen durchgeführt, um den Einfluss von Browser-basierter Kontamination zu untersuchen. Dabei wurden Fälle ausgeschlossen, in denen Modelle online Hinweise oder Lösungen gefunden hatten. Die Ergebnisse deuten darauf hin, dass der Browser-Zugriff die CTF-Performance von Deep Research nicht signifikant verbessert, was darauf hindeutet, dass die beobachteten Leistungssteigerungen primär auf Kontamination und nicht auf verbesserten Fähigkeiten beruhen könnten.
Wie schneidet Deep Research im Vergleich zu früheren OpenAI-Modellen in Bezug auf Sicherheitsmetriken ab?
Die Deep Research System Card liefert in verschiedenen Evaluationsbereichen Vergleiche der Sicherheitsmetriken von Deep Research mit früheren OpenAI-Modellen wie GPT-4o, o1-mini und o1. Zusammenfassend lässt sich sagen, dass Deep Research in vielen Sicherheitsbereichen eine verbesserte oder vergleichbare Performance zeigt, aber in einigen Bereichen auch spezifische Herausforderungen aufweist:
- Prompt Injections: Deep Research zeigt eine signifikante Verbesserung gegenüber früheren Modellen in Bezug auf die Resistenz gegen Prompt Injections, sowohl bei textbasierten als auch bei multimodalen Angriffen. Die implementierten Mitigationen haben die Erfolgsraten von Angriffen deutlich reduziert.
- Disallowed Content: Deep Research erreicht eine vergleichbare oder leicht verbesserte Performance wie frühere Modelle bei der Vermeidung von Disallowed Content. Es zeigt eine gute Balance zwischen der Vermeidung unerwünschter Inhalte und der Minimierung von Overrefusal.
- Privacy: Deep Research weist eine hohe Adhärenz an die Datenschutzrichtlinien von OpenAI auf und schneidet in Privacy-Evaluations gut ab, vergleichbar mit früheren Modellen.
- Bias: In Bezug auf Bias zeigt Deep Research eine ähnliche Performance wie OpenAI o1-preview und ist weniger stereotypenbehaftet als GPT-4o. Es gibt jedoch Verbesserungspotenzial bei der Behandlung mehrdeutiger Fragen und der Wahl der Antwort „Unknown“.
- Hallucinations: Deep Research zeigt eine signifikant reduzierte Halluzinationsrate im Vergleich zu früheren Modellen, was auf die starke Abhängigkeit von Online-Suchen und die Verlinkung zu Quellen zurückgeführt wird.
- Cybersecurity CTF Challenges: Deep Research übertrifft frühere Modelle (o3-mini, o1, GPT-4o) in Cybersecurity CTF Challenges deutlich, insbesondere bei Collegiate und Professional Level Aufgaben. Es erreicht eine „Medium Risk“-Einstufung in dieser Kategorie.
- CBRN Threat Creation: Auch im Bereich CBRN Threat Creation zeigt Deep Research Fortschritte und wird als „Medium Risk“ eingestuft. Es unterstützt Experten bei der Planung biologischer Bedrohungen, nähert sich aber der Schwelle zum „High Risk“.
- Persuasion und Model Autonomy: In den Bereichen Persuasion und Model Autonomy wird Deep Research ebenfalls als „Medium Risk“ eingestuft. Es zeigt verbesserte Fähigkeiten in Bezug auf längere und komplexere Aufgaben, aber auch hier sind weitere Sicherheitsmaßnahmen erforderlich.
Insgesamt lässt sich sagen, dass Deep Research in vielen Sicherheitsbereichen Fortschritte gemacht hat und in einigen Bereichen sogar führend ist. Dennoch betont OpenAI, dass kontinuierliche Anstrengungen erforderlich sind, um die Sicherheit und Verantwortlichkeit von KI-Modellen wie Deep Research weiter zu verbessern.
Welche Implikationen hat die Einstufung von Deep Research als „Medium Risk“ im Preparedness Framework?
Die Einstufung von Deep Research als „Medium Risk“ im Preparedness Framework hat mehrere wichtige Implikationen für OpenAI und den Einsatz des Modells:
- Einsatzbeschränkungen: Gemäß dem Preparedness Framework dürfen nur Modelle mit einem Post-Mitigation-Score von „Medium“ oder niedriger eingesetzt werden. Da Deep Research in allen evaluierten Risikokategorien als „Medium Risk“ eingestuft wurde, erfüllt es diese Bedingung und kann eingesetzt werden. Allerdings ist zu beachten, dass „Medium Risk“ immer noch ein signifikantes Risikolevel darstellt, das kontinuierliche Überwachung und Mitigation erfordert.
- Verstärkte Sicherheitsmaßnahmen: Die „Medium Risk“-Einstufung signalisiert die Notwendigkeit verstärkter Sicherheitsmaßnahmen für Deep Research. OpenAI hat bereits eine Reihe von Mitigationen implementiert (Post-Training, Blocklists, Output Classifiers, Sandboxed Coding Environment usw.). Die Einstufung unterstreicht jedoch die Bedeutung kontinuierlicher Investitionen in neue Mitigationen und Alignment-Techniken, wie z. B. Deliberative Alignment, sowie in Monitoring- und Detection-Bemühungen, insbesondere in den Bereichen CBRN und Persuasion.
- Fokus auf Frontier Risk Mitigation: Die „Medium Risk“-Einstufung, insbesondere in den Bereichen Cybersecurity und CBRN, lenkt den Fokus verstärkt auf die Mitigation von Frontier Risks. OpenAI erkennt an, dass Deep Research signifikante Fortschritte in Bereichen erzielt hat, die mit potenziell katastrophalen Risiken verbunden sind. Daher sind weitere Forschung und Entwicklung von Mitigationen für diese fortgeschrittenen Fähigkeiten von entscheidender Bedeutung.
- Transparenz und öffentliche Diskussion: Die Veröffentlichung der Deep Research System Card und die detaillierte Dokumentation der Sicherheitsmaßnahmen und Evaluationsergebnisse sind Teil von OpenAIs Bemühungen um Transparenz und die Förderung einer öffentlichen Diskussion über KI-Sicherheit. Die „Medium Risk“-Einstufung unterstreicht die Notwendigkeit dieser Diskussion und die Bedeutung eines verantwortungsvollen Umgangs mit leistungsstarken KI-Modellen.
- Kontinuierliche Weiterentwicklung: Die „Medium Risk“-Einstufung bedeutet nicht, dass die Sicherheitsbemühungen abgeschlossen sind. Im Gegenteil, OpenAI betont die Notwendigkeit kontinuierlicher Weiterentwicklung von Sicherheitsmaßnahmen, Evaluationen und des Preparedness Frameworks selbst, um mit den rasanten Fortschritten im Bereich der KI Schritt zu halten und neue Risiken frühzeitig zu erkennen und zu mitigieren.
Welche nächsten Schritte plant OpenAI, um die Sicherheit und Verantwortlichkeit von Deep Research weiter zu verbessern?
OpenAI plant eine Reihe von nächsten Schritten, um die Sicherheit und Verantwortlichkeit von Deep Research kontinuierlich zu verbessern und den Herausforderungen der KI-Sicherheit proaktiv zu begegnen:
- Verbesserung der Robustheit gegen Prompt Injections: OpenAI wird weiter in die Entwicklung robusterer Modelle investieren, die widerstandsfähiger gegen Prompt-Injection-Angriffe sind. Dies umfasst sowohl verbesserte Trainingstechniken als auch neue systemweite Mitigationen. Ein Schwerpunkt liegt auf der schnelleren Erkennung und Reaktion auf solche Angriffe.
- Verfeinerung der Disallowed Content Mitigationen: Die Mitigationen gegen Disallowed Content werden kontinuierlich verfeinert, um eine noch bessere Balance zwischen der Vermeidung unerwünschter Inhalte und der Minimierung von Overrefusal zu erreichen. Dies beinhaltet die Verbesserung von Output Classifiers und Filtern sowie die Aktualisierung von Blocklists und Safety Policies.
- Verstärkung der Datenschutzmaßnahmen: OpenAI wird die Datenschutzmaßnahmen weiter verstärken, um den Schutz persönlicher Informationen im Kontext von Deep Research zu optimieren. Dies umfasst die Weiterentwicklung von Privacy-Preserving Technologien und die Verfeinerung der Modellrichtlinien zum Schutz persönlicher Daten.
- Weiterentwicklung der Cybersecurity Mitigationen: Angesichts der „Medium Risk“-Einstufung im Bereich Cybersecurity wird OpenAI die Mitigationen in diesem Bereich weiterentwickeln. Dies umfasst die Erforschung neuer Ansätze zur Abwehr von Cyberangriffen durch KI-Modelle und die Zusammenarbeit mit Cybersecurity-Experten. Ein Fokus liegt auf der Entwicklung von Gegenmaßnahmen für fortgeschrittene Frontier Models.
- Intensivierung der CBRN-Risikoforschung: Aufgrund der „Medium Risk“-Einstufung im CBRN-Bereich wird OpenAI die Forschung zu den Risiken im Zusammenhang mit der Erstellung von CBRN-Bedrohungen durch KI-Modelle intensivieren. Dies beinhaltet die Entwicklung anspruchsvollerer Evaluationen und die Erforschung von Mitigationen, die speziell auf diese Risiken zugeschnitten sind. OpenAI ermutigt auch zu breiteren Bemühungen, sich auf eine Welt vorzubereiten, in der informationelle Barrieren zur Erzeugung solcher Bedrohungen drastisch sinken.
- Ausbau des Preparedness Frameworks: OpenAI wird das Preparedness Framework kontinuierlich weiterentwickeln, um mit den neuesten Fortschritten im Bereich der KI-Sicherheit Schritt zu halten und neue Risiken frühzeitig zu erkennen und zu adressieren. Dies beinhaltet die Erweiterung des Frameworks um neue Risikokategorien und Indikatoren sowie die Verfeinerung der Evaluationsmethoden.
- Förderung der öffentlichen Diskussion: OpenAI wird weiterhin Transparenzinitiativen wie die Deep Research System Card verfolgen, um die öffentliche Diskussion über KI-Sicherheit und -Verantwortlichkeit zu fördern. Dies beinhaltet die Veröffentlichung von Forschungsergebnissen, System Cards und anderen Dokumentationen, die Einblicke in die Sicherheitsbemühungen von OpenAI geben.
Wie können Nutzer und die Öffentlichkeit von den Erkenntnissen und Transparenzbemühungen profitieren, die in der Deep Research System Card dokumentiert sind?
Die Deep Research System Card und die darin dokumentierten Erkenntnisse und Transparenzbemühungen von OpenAI bieten Nutzern und der Öffentlichkeit vielfältige Vorteile:
- Erhöhtes Vertrauen in KI-Sicherheit: Die System Card gibt detaillierte Einblicke in die Sicherheitsvorkehrungen, die OpenAI für Deep Research getroffen hat. Dies kann dazu beitragen, das Vertrauen der Nutzer und der Öffentlichkeit in die Sicherheit von KI-Modellen zu stärken und zu zeigen, dass OpenAI das Thema Sicherheit ernst nimmt und proaktiv angeht.
- Besseres Verständnis von KI-Risiken: Die System Card erläutert auf verständliche Weise die komplexen Risikobereiche, die mit leistungsstarken KI-Modellen wie Deep Research verbunden sind. Dies fördert ein besseres Verständnis für die potenziellen Gefahren und Herausforderungen der KI-Entwicklung und sensibilisiert die Öffentlichkeit für die Notwendigkeit von Sicherheitsmaßnahmen.
- Grundlage für informierte Entscheidungen: Die detaillierten Evaluationsergebnisse und Risikobewertungen in der System Card liefern eine Grundlage für informierte Entscheidungen über den Einsatz und die Regulierung von KI-Modellen. Politik, Wirtschaft und Gesellschaft können diese Informationen nutzen, um fundierte Entscheidungen im Umgang mit KI-Technologien zu treffen.
- Anregung zur öffentlichen Diskussion: Die System Card und OpenAIs Transparenzbemühungen sollen eine breitere öffentliche Diskussion über KI-Sicherheit und -Verantwortlichkeit anregen. Dies ist entscheidend, um einen gesellschaftlichen Konsens über den verantwortungsvollen Umgang mit KI zu finden und gemeinsame Strategien für die Bewältigung der Herausforderungen zu entwickeln.
- Beitrag zur KI-Sicherheitsforschung: Die in der System Card dokumentierten Evaluationsmethoden, Mitigationen und Forschungsergebnisse können einen wertvollen Beitrag zur KI-Sicherheitsforschung leisten. Andere Forscher und Entwickler können von OpenAIs Erkenntnissen lernen und diese für ihre eigenen Sicherheitsbemühungen nutzen. Die System Card dient somit als Wissensquelle und Best-Practice-Beispiel für die KI-Sicherheitscommunity.
- Transparenz als Industriestandard: OpenAI setzt mit der Veröffentlichung der System Card ein Zeichen für mehr Transparenz in der KI-Industrie. Dies könnte andere Unternehmen dazu ermutigen, ebenfalls detailliertere Einblicke in ihre Sicherheitsbemühungen zu geben und so einen neuen Standard für Transparenz und Verantwortlichkeit in der KI-Entwicklung zu etablieren.
Konkrete Tipps und Anleitungen
Obwohl die Deep Research System Card primär ein technisches Dokument ist, das sich an Experten richtet, lassen sich auch für allgemeine Nutzer und Unternehmen einige wertvolle Tipps und Anleitungen ableiten, die zur Förderung eines sichereren und verantwortungsvolleren Umgangs mit KI beitragen können:
- Bewusstsein für KI-Risiken schärfen: Die System Card verdeutlicht, dass leistungsstarke KI-Modelle nicht nur Chancen, sondern auch Risiken bergen. Es ist wichtig, sich dieser Risiken bewusst zu sein und sie bei der Nutzung von KI-Anwendungen zu berücksichtigen. Dies gilt sowohl für individuelle Nutzer als auch für Unternehmen, die KI-Technologien einsetzen.
- Sicherheitsmaßnahmen priorisieren: OpenAI zeigt mit der System Card, dass Sicherheit ein integraler Bestandteil der KI-Entwicklung sein muss. Unternehmen, die KI-Modelle entwickeln oder einsetzen, sollten Sicherheitsmaßnahmen von Anfang an priorisieren und in ihre Entwicklungsprozesse integrieren. Dies umfasst Risikoanalysen, Mitigationen, regelmäßige Evaluationen und Monitoring.
- Transparenz und Dokumentation fördern: OpenAIs Transparenzbemühungen sind ein wichtiger Schritt in Richtung Verantwortlichkeit. Unternehmen sollten ebenfalls mehr Transparenz in Bezug auf ihre KI-Systeme und Sicherheitsmaßnahmen anstreben. Die Dokumentation von Sicherheitsvorkehrungen, Evaluationsergebnissen und Risikobewertungen kann dazu beitragen, Vertrauen zu schaffen und die öffentliche Diskussion zu fördern.
- Kritische Auseinandersetzung mit KI-Ausgaben: Die System Card verdeutlicht, dass auch fortschrittliche KI-Modelle Fehler machen können (z. B. Halluzinationen oder Bias). Nutzer sollten die Ausgaben von KI-Systemen daher immer kritisch hinterfragen und nicht blind vertrauen. Die Verlinkung zu Quellen, wie sie Deep Research implementiert, kann dabei helfen, die Glaubwürdigkeit von KI-Antworten besser einzuschätzen.
- Eigene Kompetenzen im Bereich KI-Sicherheit aufbauen: Angesichts der zunehmenden Bedeutung von KI ist es für Unternehmen und Einzelpersonen ratsam, eigene Kompetenzen im Bereich KI-Sicherheit aufzubauen. Dies umfasst das Verständnis grundlegender KI-Risiken, Mitigationstechniken und Evaluationsmethoden. Wissen über KI-Sicherheit ist entscheidend, um KI-Technologien verantwortungsvoll nutzen und entwickeln zu können.
- Zusammenarbeit und Austausch fördern: Die Bewältigung der Herausforderungen der KI-Sicherheit erfordert Zusammenarbeit und Austausch zwischen Forschern, Entwicklern, Unternehmen, Politik und Gesellschaft. OpenAI lädt mit der System Card zur öffentlichen Diskussion ein. Es ist wichtig, diesen Dialog zu suchen und gemeinsam an Lösungen für eine sichere und verantwortungsvolle KI-Zukunft zu arbeiten.
Regelmäßige Aktualisierung
Dieser Artikel wird regelmäßig aktualisiert, um die neuesten Entwicklungen im Bereich KI-Sicherheit und die Fortschritte von OpenAI im Umgang mit den Herausforderungen von Deep Research zu berücksichtigen.
Fazit: Deep Research System Card – Ein wichtiger Schritt für mehr Sicherheit in der KI-gestützten Forschung
Die Deep Research System Card von OpenAI ist mehr als nur ein technischer Bericht – sie ist ein Zeugnis für das wachsende Bewusstsein und die proaktiven Bemühungen um Sicherheit in der KI-Forschung. Mit Deep Research betritt OpenAI Neuland, indem es ein KI-Modell entwickelt, das komplexe Recherchen im Internet durchführen kann. Die System Card zeigt eindrücklich, dass OpenAI die damit verbundenen Risiken ernst nimmt und umfangreiche Maßnahmen ergriffen hat, um diese zu minimieren. Von Prompt Injection über Disallowed Content bis hin zu Cybersecurity und CBRN-Risiken – OpenAI hat ein breites Spektrum an potenziellen Gefahren analysiert und adressiert.
Die Einstufung von Deep Research als „Medium Risk“ im Preparedness Framework mag zunächst beunruhigend wirken, ist aber in Wahrheit ein Zeichen für OpenAIs realistische Risikobewertung und den transparenten Umgang mit den Herausforderungen. Es ist das erste Mal, dass ein Modell im Bereich Cybersecurity diese Einstufung erreicht, was die signifikanten Fortschritte, aber auch die verbleibenden Herausforderungen in diesem Feld unterstreicht. Die System Card ist ein Aufruf zur fortgesetzten Wachsamkeit, zur kontinuierlichen Weiterentwicklung von Sicherheitsmaßnahmen und zur Förderung einer breiten öffentlichen Diskussion über KI-Sicherheit.
OpenAI demonstriert mit diesem Dokument nicht nur technologische Exzellenz, sondern auch ein tiefes Verantwortungsbewusstsein und den Willen, die Zukunft der KI-Forschung sicher und verantwortungsvoll zu gestalten. Für uns als Nutzer und Gesellschaft ist die Deep Research System Card ein wertvolles Fenster in die Welt der KI-Sicherheit und ein Ansporn, uns aktiv an der Gestaltung einer sicheren und verantwortungsvollen KI-Zukunft zu beteiligen.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar. Erlebe, wie du KI in deinem Unternehmen effektiv einsetzt, deine Prozesse automatisierst und dein Wachstum beschleunigst – mit einer Community voller Gleichgesinnter und Experten.
Quellen
- OpenAI, „Deep Research System Card,“ 2025. https://openai.com/index/deep-research-system-card
- OpenAI, „Openai preparedness framework beta,“ 2023. https://cdn.openai.com/openai-preparedness-framework-beta.pdf
#AI #KI #ArtificialIntelligence #KuenstlicheIntelligenz #DeepResearch #OpenAISicherheit #KISicherheit #SystemCard






