
Die Einführung der Sonus-1-Modellreihe markiert einen bemerkenswerten Schritt in der Entwicklung von Large Language Models (LLMs). Mit einem Fokus auf Leistung und Vielseitigkeit beanspruchen die Modelle von Sonus AI eine neue Ebene der Möglichkeiten in Bereichen wie Mathematik, Logik und Programmierung. Die Sonus-1-Familie, bestehend aus Mini-, Air- und Pro-Modellen, bietet maßgeschneiderte Lösungen für unterschiedliche Anwendungsfälle und verspricht eine neue Ära der KI-gestützten Anwendungen.
Bemerkenswert ist jedoch, dass trotz umfangreicher Recherchen keine Informationen zum konkreten Firmensitz oder dem Herkunftsland des Entwicklers, Sonus AI, gefunden werden konnten.
Die Listung der Modelle auf Alibase deutet zwar auf einen möglichen Bezug zu China hin, doch eine offizielle Bestätigung oder eine genaue Firmenangabe fehlen. Diese Unklarheit ist ungewöhnlich und wirft Fragen hinsichtlich der Transparenz der Entwicklung und des Ursprungs dieser Technologie auf. Trotz dieser fehlenden Informationen liefert die Sonus-1-Modellreihe beeindruckende Benchmark-Ergebnisse und eröffnet neue Perspektiven im Bereich der künstlichen Intelligenz.
Das musst Du wissen: Highlights der Sonus-1-Reihe
Die Sonus-1-Reihe umfasst Mini-, Air- und Pro-Modelle, die auf unterschiedliche Hardware-Konfigurationen zugeschnitten sind und somit flexibel eingesetzt werden können. Die Modelle erzielen herausragende Ergebnisse in vielen Bereichen wie Mathematik, Logik und Programmierung, und decken eine breite Palette von Anwendungen ab, darunter Textgenerierung, Übersetzung und Chatbot-Entwicklung. Sonus AI legt großen Wert auf zuverlässige und datenschutzorientierte Lösungen und setzt auf Methoden wie Federated Learning und Differential Privacy. Mit kontinuierlicher Weiterentwicklung und Community-Feedback wird Sonus AI auch in Zukunft Spitzenleistungen bieten.
Was macht die Sonus-1-Modelle besonders?
Die Sonus-1-Modellfamilie zeichnet sich durch einen modularen Ansatz aus, der es ermöglicht, auf vielfältige Bedürfnisse und Herausforderungen einzugehen. Anstatt eine Einheitslösung anzubieten, hat Sonus AI eine Reihe von Modellen entwickelt, die jeweils auf spezifische Anwendungsfälle zugeschnitten sind. Dieser flexible Ansatz bedeutet, dass Nutzer genau das richtige Werkzeug für ihre jeweilige Aufgabe wählen können, ohne unnötige Ressourcen zu verschwenden.
Ein Blick auf die Modellvarianten:
- Sonus-1 Mini: Das kleinste Modell der Familie ist wie ein flinker Sprinter – schnell, effizient und ideal für Anwendungen, bei denen es auf Geschwindigkeit und Kosten ankommt. Denken Sie an einfache Chatbots, mobile Anwendungen oder automatisierte Textgenerierung für kurze Inhalte.
- Sonus-1 Air: Dieses Modell ist der Allrounder, vergleichbar mit einem gut ausbalancierten Mehrkämpfer. Es bietet eine solide Leistung in verschiedenen Bereichen und eignet sich hervorragend für eine breite Palette von Aufgaben, von der Übersetzung bis zur Datenanalyse. Es ist die richtige Wahl, wenn Sie Flexibilität und Zuverlässigkeit suchen.
- Sonus-1 Pro: Hier kommt das Schwergewicht ins Spiel. Das Pro-Modell ist optimiert für Aufgaben, die extreme Rechenleistung und Präzision erfordern. Es ist die erste Wahl für komplexe Simulationen, anspruchsvolle Programmierung oder umfangreiche Datenanalysen. Wenn Sie die Grenzen des Machbaren ausloten wollen, ist dies Ihr Modell.
- Sonus-1 Pro (mit Reasoning): Dieses Flaggschiffmodell ist wie ein erfahrener Stratege, der auch die kniffligsten Probleme mit seiner „Chain-of-Thought“-Logik lösen kann. Es zeichnet sich besonders bei komplexen Fragestellungen aus, die logisches Denken und tiefes Verständnis erfordern, etwa bei der wissenschaftlichen Forschung oder der Analyse großer Datenmengen.
Kernmerkmale und Versprechen von Sonus AI:
- Leistung: Alle Modelle der Sonus-1-Familie sind darauf ausgelegt, in ihren jeweiligen Anwendungsbereichen höchste Leistung zu erbringen. Egal ob es um schnelle Berechnungen, logische Schlussfolgerungen oder präzise Programmierung geht – die Sonus-1-Modelle bieten beeindruckende Resultate.
- Vielseitigkeit: Die Modelle sind nicht auf eine einzelne Aufgabe beschränkt. Sie decken ein breites Spektrum ab, von der natürlichen Sprachverarbeitung bis hin zur komplexen Datenanalyse. Dies macht sie zu einem wertvollen Werkzeug für viele verschiedene Branchen und Einsatzgebiete.
- Datenschutz: In einer Zeit, in der Datensicherheit von größter Bedeutung ist, legt Sonus AI großen Wert auf den Schutz der Privatsphäre. Die Modelle sind darauf ausgelegt, zuverlässige und datenschutzorientierte Lösungen zu bieten, ohne dabei Kompromisse bei der Leistung einzugehen.
- Kontinuierliche Weiterentwicklung: Sonus AI sieht seine Arbeit nicht als abgeschlossen an. Das Unternehmen ist bestrebt, seine Modelle kontinuierlich zu verbessern und an die sich verändernden Anforderungen anzupassen. Dies verspricht eine kontinuierliche Weiterentwicklung und neue Funktionen in der Zukunft.
- Benchmark-Ergebnisse: Die Sonus-1 Modelle, insbesondere das Pro (mit Reasoning) Modell, erzielen in diversen Benchmarks bemerkenswerte Ergebnisse und können oft mit der Konkurrenz mithalten. Dies unterstreicht die Effektivität des entwickelten Ansatzes, insbesondere bei Aufgaben, die ein hohes Maß an Logik und Schlussfolgerung erfordern.
- Entwicklungsfokus: Der Kern der Mission von Sonus AI ist die Entwicklung von hochleistungsfähigen, erschwinglichen, zuverlässigen und datenschutzorientierten Sprachmodellen. Dabei wird stets ein besonderes Augenmerk auf die Nutzerbedürfnisse und die ethischen Implikationen gelegt.
Zusammenfassend lässt sich sagen, dass die Sonus-1-Modelle nicht einfach nur eine weitere KI-Technologie darstellen, sondern eine durchdachte und flexible Lösung, die darauf abzielt, die Leistungsfähigkeit und Anwendbarkeit von KI in der Praxis zu maximieren.
Folgefragen (FAQs)
Wie schneiden die Sonus-1-Modelle in Benchmarks ab?
Die Modelle demonstrieren Spitzenleistung in verschiedenen Bereichen:
- MMLU: 90,15 % für allgemeines logisches Denken.
- MATH-500: 91,8 % für fortgeschrittene Mathematik.
- HumanEval (Coding): 90,0 % für Programmieraufgaben.
- DROP (Reasoning): 88,9 % für starkes logisches Denken.
- Aider-Edit: 72,6 % für die Codebearbeitung in realen Szenarien.
Detaillierte Analyse der Sonus-1-Benchmarks
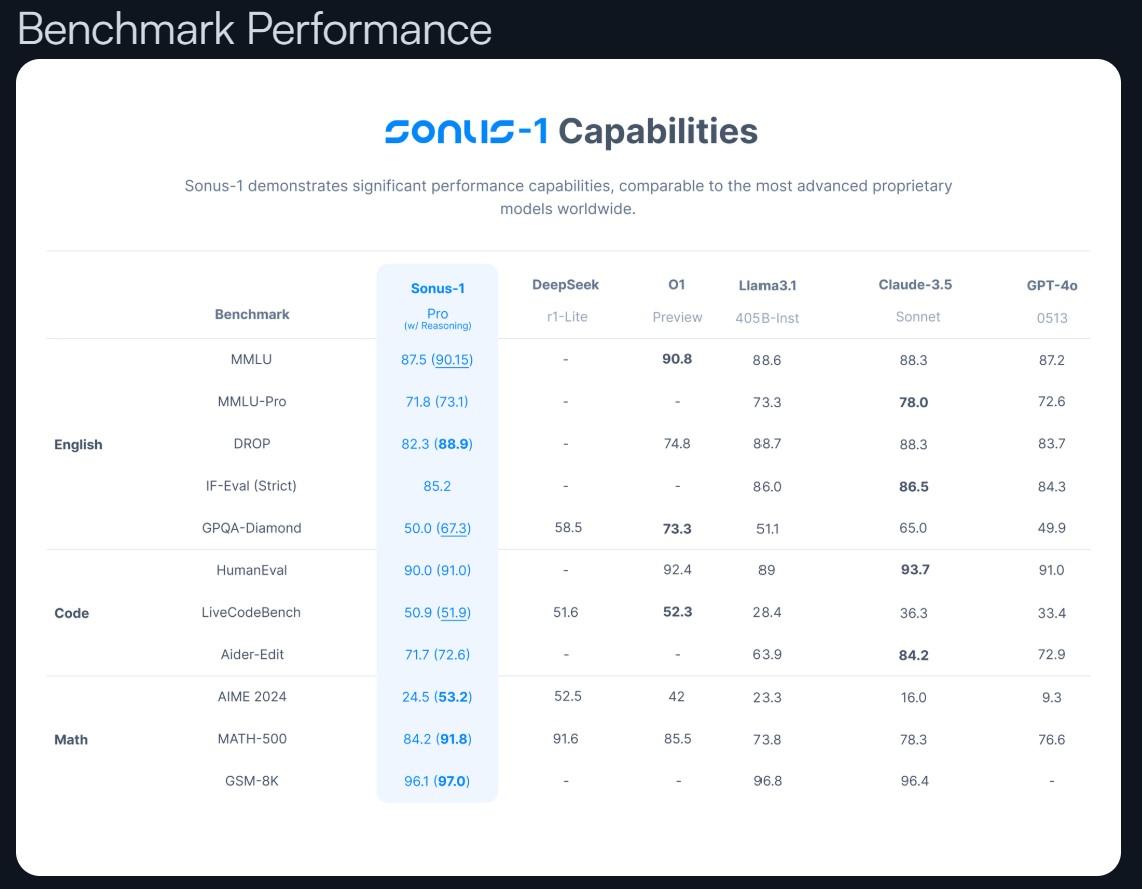
Die obige Grafik zeigt die Benchmark-Leistung der Sonus-1 Pro (mit Reasoning)-Modelle im Vergleich zu anderen führenden KI-Modellen wie GPT-4, Claude 3.5 und Llama 3.1. Sie gibt Einblicke in die Stärken und Schwächen der Sonus-1-Familie und demonstriert deren Wettbewerbsvorteile. Im Folgenden analysieren wir die Ergebnisse im Detail, um die Vorzüge und Optimierungsbereiche besser zu verstehen.
Die Sonus-1 Pro (mit Reasoning) Modelle erzielen in verschiedenen Benchmarks Spitzenleistungen. Während GPT-4 immer noch ein Top-Modell ist, kann Sonus-1 in bestimmten Aspekten mithalten oder es sogar übertreffen. Es ist wichtig anzumerken, dass Claude 3.5 und Llama 3.1 in einigen Bereichen besser abschneiden. Im MMLU Benchmark erreicht Sonus-1 Pro (mit Reasoning) 90,15% und übertrifft GPT-4 (87,2%) und Llama 3.1 (88,6%) in der Leistung. Im Bereich HumanEval für Programmierung erreicht Sonus-1 91,0% und ist somit auf Augenhöhe mit GPT-4 (91,0%). In Bezug auf mathematische Aufgaben mit dem MATH-500 Benchmark erreicht Sonus-1 91,8% und übertrifft GPT-4 (76,6%) deutlich. Diese Ergebnisse sind jedoch stark von der Art der jeweiligen Aufgabe abhängig.
1. Allgemeines logisches Denken (MMLU, MMLU-Pro)
- MMLU (Massive Multitask Language Understanding):
Sonus-1 Pro (mit Reasoning) erzielt hier 87,5 % (90,15 % bei der erweiterten Version) und liegt damit knapp hinter dem DeepSeek-Modell, das 90,8 % erreicht. Dennoch übertrifft Sonus-1 die Leistung von GPT-4 (87,2 %) und Llama 3.1 (88,6 %).
Vorteil: Robuste Fähigkeiten im Bereich logisches Denken und interdisziplinäre Problemstellungen.
Verbesserungspotenzial: Leichtes Aufholen gegenüber dem Spitzenreiter DeepSeek in diesem Bereich. - MMLU-Pro:
Hier erreicht Sonus-1 Pro 71,8 % (73,1 % bei der erweiterten Version) und liegt hinter Claude 3.5 (78,0 %). Es bleibt jedoch mit GPT-4 (72,6 %) auf Augenhöhe.
Vorteil: Solide Leistung in erweiterten, komplexen Aufgaben.
Verbesserungspotenzial: Optimierungen in schwierigeren MMLU-Szenarien könnten helfen, Claude 3.5 zu überholen.
2. Logisches Schließen und Verstehen (DROP, GPQA-Diamond)
- DROP (Discrete Reasoning Over Paragraphs):
Mit 82,3 % (88,9 % bei der erweiterten Version) zeigt Sonus-1 Pro hervorragende Fähigkeiten im Bereich des logischen Denkens. Es ist jedoch leicht unterlegen gegenüber Llama 3.1 (88,7 %) und Claude 3.5 (88,3 %).
Vorteil: Starke logische Fähigkeiten, insbesondere bei diskreten Aufgaben wie Zahlenverarbeitung und komplexen Textverständnis.
Verbesserungspotenzial: Feinabstimmungen im Bereich des präzisen Lesens und Schlussfolgerns könnten den Unterschied machen. - GPQA-Diamond:
Hier liegt Sonus-1 Pro bei 50,0 % (67,3 % bei der erweiterten Version) und bleibt deutlich hinter DeepSeek (58,5 %) sowie Claude 3.5 (65,0 %) zurück.
Vorteil: Solide Grundlagen im wissenschaftlichen Schließen.
Verbesserungspotenzial: Dieser Bereich ist ein klarer Schwachpunkt, der durch gezielte Verbesserungen in der wissenschaftlichen Logik gestärkt werden sollte.
3. Programmierung (HumanEval, LiveCodeBench, Aider-Edit)
- HumanEval (Coding):
Sonus-1 Pro überzeugt mit 90,0 % (91,0 % bei der erweiterten Version) und liegt fast gleichauf mit GPT-4 (91,0 %). Claude 3.5 ist mit 93,7 % der Spitzenreiter.
Vorteil: Starke Programmierfähigkeiten und präzise Codegenerierung.
Verbesserungspotenzial: Leichtes Feintuning, um die Top-Position zu erreichen. - LiveCodeBench:
Mit 50,9 % (51,9 % bei der erweiterten Version) zeigt Sonus-1 Pro eine solide Leistung, liegt jedoch hinter DeepSeek (52,3 %) und deutlich unter Claude 3.5 (36,3 %).
Vorteil: Zuverlässige Basisleistung in realen Programmierumgebungen.
Verbesserungspotenzial: Verbesserung der Leistung in dynamischen Codeumgebungen durch Training auf breiteren Datensätzen. - Aider-Edit (Codebearbeitung):
Beeindruckende 71,7 % (72,6 % bei der erweiterten Version) zeigen die Stärke von Sonus-1 in der Code-Optimierung. Dies übertrifft GPT-4 (72,9 %) nur knapp und bleibt hinter Claude 3.5 (84,2 %).
Vorteil: Robuste Fähigkeiten zur Codebearbeitung.
Verbesserungspotenzial: Höherer Fokus auf semantische Codeveränderungen und Testszenarien.
4. Mathematik (MATH-500, GSM-8k, AIME 2024)
- MATH-500:
Sonus-1 Pro erreicht 84,2 % (91,8 % bei der erweiterten Version) und zeigt starke Fähigkeiten im Bereich komplexer mathematischer Probleme. Es liegt knapp hinter DeepSeek (91,6 %) und übertrifft GPT-4 (76,6 %) deutlich.
Vorteil: Exzellente Leistung bei mathematischer Präzision und Problemlösung.
Verbesserungspotenzial: Weitere Feinabstimmung, um mit den Spitzenmodellen mitzuhalten. - GSM-8k:
Hier glänzt Sonus-1 Pro mit 96,1 % (97,0 % bei der erweiterten Version) und übertrifft fast alle Modelle, einschließlich Llama 3.1 (96,8 %) und Claude 3.5 (96,4 %).
Vorteil: Führend in hochkomplexen Mathematikaufgaben.
Verbesserungspotenzial: Fast keine – hier gehört Sonus-1 zu den besten Modellen. - AIME 2024:
Mit 24,5 % (53,2 % bei der erweiterten Version) zeigt Sonus-1 eine solide Leistung in diesem herausfordernden Bereich. DeepSeek (52,3 %) und GPT-4 (42 %) bleiben jedoch konkurrenzfähig.
Vorteil: Gute Grundlagen bei fortgeschrittenen mathematischen Szenarien.
Verbesserungspotenzial: Fokus auf noch komplexere mathematische Szenarien und abstrakte Problemstellungen.
Zusammenfassung der Analyse
Die Sonus-1 Pro (mit Reasoning)-Modelle zeigen beeindruckende Leistungen in Mathematik, Logik und Programmierung. Besonders bei Aufgaben wie GSM-8k, HumanEval und MATH-500 ist Sonus-1 ein Spitzenmodell, das selbst etablierte Konkurrenten wie GPT-4 übertrifft. Schwächen gibt es jedoch in einigen anspruchsvollen Bereichen wie GPQA-Diamond und LiveCodeBench, wo noch Optimierungsbedarf besteht.
Die Grafik macht deutlich, dass Sonus-1 eine starke Wahl für Entwickler, Datenwissenschaftler und Unternehmen ist, die leistungsstarke und vielseitige LLMs benötigen. Gleichzeitig zeigt sie auf, in welchen Bereichen Sonus AI noch nachbessern könnte, um sein Modell weiter zu verbessern. Mit dieser Analyse können Interessierte gezielt entscheiden, ob Sonus-1 ihre Anforderungen erfüllt und wie es im Vergleich zu anderen Modellen abschneidet.
Analyse der Sonus-1 Benchmark-Performance
Die Grafik oben zeigt die Benchmark-Leistungen der verschiedenen Sonus-1-Modelle – Pro, Pro (mit Reasoning), Air und Mini – und vergleicht deren Fähigkeiten in Kategorien wie Englisch, Code und Mathematik. Jede Modellvariante ist für spezifische Anwendungsfälle optimiert. Nachfolgend erläutern wir die Ergebnisse und was sie für den Einsatz der Modelle bedeuten.

1. Leistung in der Kategorie Englisch
MMLU (Massive Multitask Language Understanding)
- Sonus-1 Pro (mit Reasoning): Erreicht 90,15 %, was eine überragende Fähigkeit im allgemeinen logischen Denken zeigt.
- Sonus-1 Air: Mit 84,0 % eine solide Wahl für vielseitige Anwendungen.
- Sonus-1 Mini: Erreicht 76,0 %, ideal für einfache Aufgaben mit geringeren Anforderungen.
- Interpretation: Sonus-1 Pro (mit Reasoning) ist die klare Wahl für anspruchsvolle Aufgaben, die breites Wissen und schlüssiges Denken erfordern.
MMLU-Pro (erweiterte Version)
- Sonus-1 Pro (mit Reasoning): Mit 73,1 % bietet es starke Fähigkeiten, bleibt aber hinter dem allgemeinen MMLU-Ergebnis zurück.
- Sonus-1 Mini: Nur 57,4 %, was seine Limitierung bei komplexeren Aufgaben zeigt.
- Interpretation: Für schwierigere und spezialisierte Problemstellungen bietet die Pro-Version klare Vorteile.
DROP (Discrete Reasoning Over Paragraphs)
- Sonus-1 Pro (mit Reasoning): Führend mit 88,9 %, was starke Fähigkeiten beim logischen Schlussfolgern zeigt.
- Sonus-1 Air: Bietet 79,0 %, eine gute Leistung für allgemeine Aufgaben.
- Sonus-1 Mini: Erreicht 73,2 %, geeignet für Basisanwendungen.
- Interpretation: Das Reasoning-Modell glänzt hier besonders bei der Verarbeitung von Textdaten, die komplexes Schließen erfordern.
IF-Eval (Strict)
- Sonus-1 Pro: Mit 85,2 % überzeugt es bei strengen Evaluierungen von Sprachlogik.
- Sonus-1 Mini: Weist mit 72,3 % Einschränkungen auf.
- Interpretation: Dieses Ergebnis unterstreicht die Fähigkeit der Pro-Version, auch anspruchsvolle Sprachtests zu meistern.
GPQA-Diamond (wissenschaftliches Schließen)
- Sonus-1 Pro (mit Reasoning): Punktet mit 67,3 %, einem starken Ergebnis in wissenschaftlichen Problemstellungen.
- Sonus-1 Air: Erreicht nur 48,0 %, und Mini fällt mit 36,3 % deutlich ab.
- Interpretation: Dieses Benchmark zeigt, dass die Reasoning-Version die einzige Option für wissenschaftliche Anwendungen ist.
2. Leistung in der Kategorie Code
HumanEval (Programmierung)
- Sonus-1 Pro (mit Reasoning): Mit 91,0 % eine exzellente Leistung bei Codierungsaufgaben.
- Sonus-1 Air: Mit 88,9 % eine gute Wahl für vielseitige Codierungsprojekte.
- Sonus-1 Mini: Erreicht 85,1 %, eine respektable Leistung bei einfacheren Codieranforderungen.
- Interpretation: Für hochpräzise Codierungsaufgaben ist das Reasoning-Modell die erste Wahl.
LiveCodeBench (Real-World-Codierung)
- Sonus-1 Pro (mit Reasoning): Erreicht 51,9 %, was eine durchschnittliche Leistung in realen Programmierumgebungen widerspiegelt.
- Sonus-1 Mini: Mit 36,1 % hat es Schwierigkeiten bei realitätsnahen Szenarien.
- Interpretation: Der Pro-Bereich zeigt solide, aber nicht führende Fähigkeiten in dynamischen Code-Umgebungen.
Aider-Edit (Code-Bearbeitung)
- Sonus-1 Pro (mit Reasoning): Mit 72,6 % beweist es starke Fähigkeiten in der Bearbeitung und Optimierung von Code.
- Sonus-1 Air: Gute Leistung mit 67,8 %.
- Sonus-1 Mini: Mit 56,4 % für einfache Aufgaben geeignet.
- Interpretation: Das Pro-Modell bietet eine klare Verbesserung bei der Codeoptimierung.
3. Leistung in der Kategorie Mathematik
MATH-500
- Sonus-1 Pro (mit Reasoning): Führt mit 91,8 %, ideal für komplexe mathematische Probleme.
- Sonus-1 Air: Erreicht 80,9 %, eine solide Leistung für allgemeine Mathematikaufgaben.
- Sonus-1 Mini: Mit 75,8 % für grundlegende Berechnungen geeignet.
- Interpretation: Mathematik ist eine der größten Stärken von Sonus-1 Pro (mit Reasoning).
GSM-8k (Challenging Math)
- Sonus-1 Pro (mit Reasoning): Herausragende 97,0 %, eine Spitzenleistung.
- Sonus-1 Mini: Mit 91,8 % immer noch beeindruckend.
- Interpretation: Dies unterstreicht die Spitzenposition von Sonus-1 in mathematischen Aufgaben.
AIME 2024 (Advanced Math)
- Sonus-1 Pro (mit Reasoning): Mit 53,2 % ein starker Wert in fortgeschrittener Mathematik.
- Sonus-1 Mini: Mit nur 16,2 % ist es nicht für diesen Bereich geeignet.
- Interpretation: Für komplexe mathematische Probleme bleibt das Pro-Modell unschlagbar.
Zusammenfassung der Analyse
Die Sonus-1 Pro (mit Reasoning)-Version ist klar führend in den Benchmarks und bietet exzellente Ergebnisse in Mathematik, Codierung und Sprachverarbeitung. Die Air-Version liefert eine gute Balance zwischen Leistung und Ressourcennutzung, während die Mini-Version ideal für einfache und kosteneffiziente Anwendungen ist.
Stärken von Sonus-1
- Exzellente Mathematik-Fähigkeiten: Besonders bei GSM-8k und MATH-500.
- Starke Codegenerierung: HumanEval und Aider-Edit zeigen hohe Präzision.
- Führend bei Sprachlogik: DROP und IF-Eval (Strict).
Verbesserungspotenzial
- GPQA-Diamond: Wissenschaftliches Schließen ist ausbaufähig.
- LiveCodeBench: Verbesserungen in realen Codierungsumgebungen nötig.
Was bedeutet das für Anwender?
Die Ergebnisse zeigen, dass Sonus-1 Pro (mit Reasoning) die beste Wahl für anspruchsvolle Aufgaben in Mathematik, Codierung und Sprache ist. Nutzer mit weniger komplexen Anforderungen können von den Air- oder Mini-Versionen profitieren, die eine gute Balance zwischen Leistung und Kosten bieten.
Welche Zielgruppen profitieren von Sonus-1?
- Entwickler: Für den Aufbau von Chatbots und NLP-Anwendungen.
- Datenwissenschaftler: Für komplexe Analysen und Mustererkennung.
- Unternehmen: Zur Optimierung von Machine-Learning-Modellen und Vorhersagegenauigkeit.
Was ist der Unterschied zwischen Sonus-1 Mini, Air und Pro?
- Mini: Geschwindigkeit und Kosteneffizienz für einfache Aufgaben.
- Air: Vielseitigkeit mit ausgewogener Leistung.
- Pro: Höchstleistung für komplexe Herausforderungen.
Wo kann ich Sonus-1 ausprobieren?
Die Modelle sind auf der offiziellen Website verfügbar: chat.sonus.ai. Dort können Benutzer sich registrieren und die verschiedenen Versionen testen.
Tipps zur optimalen Nutzung der Sonus-1-Modelle
- Bedarfsanalyse: Wählen Sie das Modell basierend auf Ihrem Anwendungsfall (z. B. Sonus-1 Pro für komplexe Aufgaben).
- Parameter einstellen: Optimieren Sie die Modelleinstellungen, um die beste Leistung für Ihre spezifischen Anforderungen zu erzielen.
- Einsatzgebiete definieren: Nutzen Sie Sonus-1 für Aufgaben wie Chatbots, Datenanalysen oder automatisierte Programmierung.
- Kontinuierliches Lernen: Nutzen Sie Updates und neue Funktionen, um mit der Entwicklung Schritt zu halten.
- Integration: Implementieren Sie die Modelle in bestehende Systeme, um Workflows zu verbessern.
Fazit Sonus-1
Die Sonus-1-Modellreihe präsentiert sich als eine bemerkenswerte Innovation im Bereich der künstlichen Intelligenz, die in vielerlei Hinsicht neue Maßstäbe setzt. Ihre Vielseitigkeit und die beeindruckende Leistungsfähigkeit, besonders in Bereichen wie Mathematik, Logik und Programmierung, machen sie zu einem vielversprechenden Werkzeug für Entwickler, Datenwissenschaftler und Unternehmen. Die Sonus-1 Modelle zeigen, dass es möglich ist, in einzelnen Anwendungsbereichen mit etablierten Modellen, wie GPT-4 oder Claude 3.5, mitzuhalten oder diese zu übertreffen.
Trotz dieser offensichtlichen Potenziale und der fortschrittlichen Technologie, die in den Sonus-1-Modellen steckt, bleiben Fragen offen. Die fehlende Transparenz hinsichtlich des Unternehmens Sonus AI und dessen genauer Herkunft ist ungewöhnlich und sollte von potenziellen Nutzern berücksichtigt werden. Die Listung der Modelle in einem Alibaba-Cloud-Marktplatz lässt auf eine mögliche Verbindung zu China schließen, ist jedoch kein Beweis für den tatsächlichen Ursprung. Diese Unsicherheit unterstreicht, dass es wichtig ist, bei der Einführung neuer KI-Technologien nicht nur auf Leistung, sondern auch auf Vertrauenswürdigkeit und Herkunft zu achten.
Wir empfehlen Interessierten, die Sonus-1-Modelle selbst zu testen und sich ein eigenes Bild von deren Fähigkeiten zu machen. Nutzen Sie die kostenlosen Testmöglichkeiten auf der offiziellen Website, um die Modelle in Ihren jeweiligen Anwendungsfällen zu evaluieren und zu sehen, ob sie Ihre Anforderungen erfüllen können. Dabei sollten Sie jedoch immer im Hinterkopf behalten, dass die Herkunft dieser Technologie derzeit unklar bleibt.
Die Sonus-1-Familie bietet zweifellos aufregende Möglichkeiten, doch die fehlende Transparenz in Bezug auf den Entwickler und die Herkunft des Modells erfordert eine differenzierte Betrachtung. Es ist wichtig, dass wir als Gesellschaft nicht nur auf Fortschritt und Innovationen Wert legen, sondern auch auf ethische Aspekte und Transparenz. Insofern wird die Entwicklung der Sonus-1-Modelle, und wie sie sich in der KI-Welt positionieren wird, weiterhin aufmerksam zu beobachten sein.
Jetzt ausprobieren: Besuchen Sie chat.sonus.ai und entdecken Sie die Möglichkeiten der Sonus-1-Familie.
Quellen und Referenzen zu Sonus-1
- Offizieller Blog von Sonus AI: Sonus-1 Blog
- Aibase Toolbeschreibung: Aibase Tool






