

Stell dir eine künstliche Intelligenz vor, die nicht mehr aufwendig von Menschen trainiert werden muss. Eine KI, die sich ihre eigenen Aufgaben stellt, aus ihren eigenen Lösungen lernt und sich in einem ständigen Kreislauf selbst verbessert – ganz ohne einen einzigen von Menschen gelabelten Datensatz. Was wie Science-Fiction klingt, ist jetzt Realität. Forscher des Tencent AI Lab haben mit R-Zero einen bahnbrechenden Rahmen geschaffen, der das Fundament der KI-Entwicklung erschüttert und die Tür zu autonom lernender Superintelligenz einen Spalt weiter aufstößt.
Das größte Nadelöhr bei der Entwicklung großer Sprachmodelle (LLMs) war bisher die immense Abhängigkeit von menschlich kuratierten Daten. Dieser Prozess ist nicht nur extrem teuer und zeitaufwendig, sondern auch anfällig für menschliche Voreingenommenheit. R-Zero eliminiert diesen Flaschenhals vollständig. Es ist ein System, das aus sich selbst heraus lernt, angetrieben durch einen genialen Mechanismus der Co-Evolution. In diesem Artikel tauchen wir tief in die Technologie hinter R-Zero ein, analysieren die beeindruckenden Ergebnisse und beleuchten, warum dieser Ansatz die Spielregeln für die gesamte KI-Branche für immer verändern könnte.
Tencent ist einer DER Player in China, die die KI Entwicklung vorantreiben. Vor zehn Tagen wurde von Tencent Hunyuan-GameCraft veröffentlicht. Eine KI für interaktive Spielvideos in ECHTZEIT!
Tencent R-Zero: Das Wichtigste in Kürze
- Vollständige Autonomie: R-Zero ist das erste Framework, mit dem große Sprachmodelle (LLMs) ihre Denk- und Problemlösefähigkeiten völlig autonom verbessern können, ohne auf menschlich gelabelte Daten oder bestehende Datensätze angewiesen zu sein.
- Co-Evolutionäres Lernen: Das System nutzt zwei KI-Modelle – einen „Challenger“, der immer schwierigere Aufgaben erfindet, und einen „Solver“, der lernt, diese zu lösen. Beide entwickeln sich gemeinsam weiter.
- Kein Daten-Labeling mehr: Der teuerste und langsamste Schritt in der KI-Entwicklung wird eliminiert. Das senkt die Kosten drastisch und demokratisiert den Zugang zu fortschrittlicher KI.
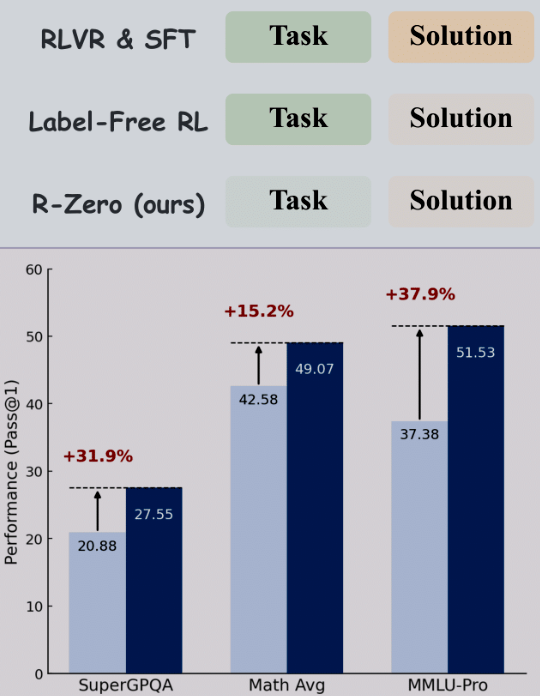
- Messbare Leistungssteigerung: In Tests steigerte R-Zero die Leistung von Modellen wie Qwen3-4B bei mathematischen Aufgaben um beeindruckende +6,49 Punkte und bei allgemeinen Denkaufgaben sogar um +7,54 Punkte.
- Theoretisch fundiert: Das System erzeugt Aufgaben, die sich an der „Grenze der Fähigkeit“ des Solvers bewegen (ca. 50% Lösungsrate), was theoretisch die effizienteste Lernmethode darstellt.
- Generalisierbare Fähigkeiten: Obwohl auf Mathematik trainiert, zeigten die Modelle signifikante Verbesserungen in allgemeinen Denk-Benchmarks wie MMLU-Pro und SuperGPQA.
- Offene Herausforderungen: Der Ansatz funktioniert am besten in Domänen mit objektiv richtigen Antworten (z.B. Mathematik). Die Anwendung auf kreative oder subjektive Aufgaben ist eine zukünftige Hürde.

Wie R-Zero funktioniert: Ein technischer Deep-Dive in die Co-Evolution
Das Herzstück von R-Zero ist ein eleganter, sich selbst verstärkender Kreislauf, der an die Evolution in der Natur erinnert. Statt eines einzelnen Modells, das passiv Daten konsumiert, erschafft R-Zero ein dynamisches Ökosystem aus zwei Instanzen desselben Basis-LLMs, die unterschiedliche, aber komplementäre Rollen einnehmen.

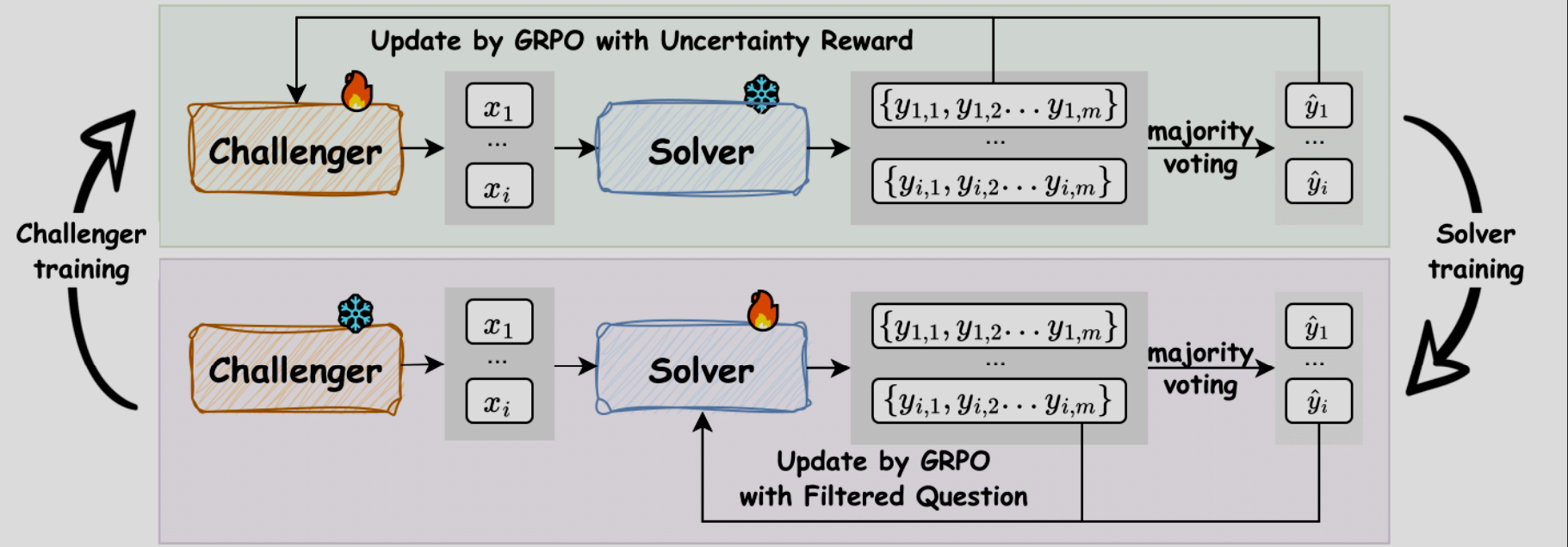
- Der Challenger (Q_theta): Seine einzige Aufgabe ist es, neue, herausfordernde Probleme zu generieren. Er wird dafür belohnt, Fragen zu stellen, die für den Solver schwer, aber nicht unlösbar sind – also genau an der Grenze seiner aktuellen Fähigkeiten liegen.
- Der Solver (S_phi): Seine Aufgabe ist es, die vom Challenger gestellten Probleme zu lösen. Er wird für korrekte Lösungen belohnt und verbessert so kontinuierlich seine Fähigkeiten.
Dieser Prozess wird durch einen fortschrittlichen Algorithmus aus dem Reinforcement Learning gesteuert, dem Group Relative Policy Optimization (GRPO). Anstatt auf einen externen „Kritiker“ zu warten, vergleicht GRPO mehrere Antworten des Modells auf dieselbe Frage und normalisiert die Belohnungen innerhalb dieser Gruppe. Das macht das Training stabiler und effizienter.
Der geniale Trick: Die Unsicherheits-Belohnung
Woher weiß der Challenger, was eine „gute“ Frage ist, ohne menschliches Feedback? Hier kommt die Unsicherheits-Belohnung (Uncertainty Reward) ins Spiel. Für jede vom Challenger generierte Frage lässt man den aktuellen Solver mehrmals (z.B. 10 Mal) antworten.
- Wenn der Solver fast immer dieselbe (richtige) Antwort gibt, ist die Frage zu einfach.
- Wenn der Solver viele verschiedene, inkonsistente Antworten gibt, ist die Frage wahrscheinlich zu schwer oder missverständlich.
Die maximale Belohnung erhält der Challenger, wenn die Erfolgsquote des Solvers bei etwa 50% liegt. An diesem Punkt ist die Unsicherheit am größten und das Lernpotenzial maximal. Die Formel dafür lautet:
runcertainty(x;ϕ)=1−2∣p^(x;Sϕ)−1/2∣
Hierbei ist hatp(x;S_phi) die empirische Erfolgsquote des Solvers für die Frage x. Dieser Wert wird 1 (maximale Belohnung), wenn die Erfolgsquote genau 0.5 (also 50%) beträgt.

Der R-Zero-Zyklus in 5 Schritten: Vom leeren Blatt zum besseren Denken
Der gesamte Trainingsprozess läuft in iterativen Zyklen ab, die ohne menschliches Eingreifen stattfinden.
- Schritt 1: Challenger generiert Fragen: Der Challenger (Q_theta) erzeugt einen großen Pool an neuen Aufgaben (z.B. 8.000 mathematische Probleme).
- Schritt 2: Solver erzeugt Pseudo-Label: Für jede Frage generiert der aktuelle, „eingefrorene“ Solver (S_phi) mehrere Antworten. Die am häufigsten vorkommende Antwort wird als „Pseudo-Label“ (die vorläufig richtige Antwort) festgelegt.
- Schritt 3: Qualitätskontrolle & Filterung: Nur die Fragen, bei denen die Konsistenz der Solver-Antworten in einem optimalen Bereich liegt (z.B. zwischen 30% und 70%), werden für das Training behalten. Dies filtert zu leichte und zu schwere Aufgaben heraus und dient gleichzeitig als Qualitätskontrolle. Zusätzlich verhindert eine „Repetition Penalty“, dass der Challenger immer wieder dieselben Wissenslücken ausnutzt.
- Schritt 4: Solver wird trainiert: Der Solver wird nun mit dem gefilterten Datensatz aus anspruchsvollen Fragen und den selbst erzeugten Pseudo-Labels trainiert. Er wird dafür belohnt, das Pseudo-Label zu reproduzieren.
- Schritt 5: Challenger wird trainiert: Anschließend wird der Challenger aktualisiert. Er wird dafür belohnt, Fragen zu generieren, die den neuen, verbesserten Solver an die 50%-Erfolgsgrenze bringen.
Dieser Zyklus wiederholt sich, wodurch beide Modelle schrittweise ihre Fähigkeiten steigern – ein autonomes Wettrüsten der Intelligenz.
R-Zero vs. Traditionelles Training: Ein Paradigmenwechsel in der KI-Entwicklung
| Dimension | Traditionelles Training (Supervised) | R-Zero Framework (Autonom) |
| Datenquelle | Menschlich erstellte/gelabelte Datensätze | Vollständig selbstgeneriert, aus dem Nichts |
| Kosten | Extrem hoch (Millionen für Annotation) | Minimal (nur Rechenzeit) |
| Skalierbarkeit | Begrenzt durch menschliche Arbeitskraft | Nahezu unbegrenzt skalierbar |
| Bias-Risiko | Hoch (erbt menschliche Vorurteile) | Geringer, da von menschlichen Daten entkoppelt |
| Curriculum | Statisch, vordefiniert | Dynamisch, adaptiv, perfekt zugeschnitten |
| Leistungsgrenze | Limitiert durch die Qualität der menschlichen Daten | Potenziell übermenschlich |
Einblick vom Experten: Die Vision hinter R-Zero
„Self-evolving Large Language Models (LLMs) offer a scalable path toward superintelligence by autonomously generating, refining, and learning from their own experiences. […] R-Zero is a fully autonomous framework that generates its own training data from scratch.“ – Chengsong Huang, Wenhao Yu et al. [R-Zero Paper, 2025]
Diese Aussage aus dem Originalpaper verdeutlicht die Ambition: Es geht nicht nur um eine inkrementelle Verbesserung, sondern darum, einen skalierbaren Pfad in Richtung Superintelligenz zu schaffen, indem die Fesseln der menschlichen Datenabhängigkeit gesprengt werden.
Beeindruckende Ergebnisse: R-Zero in der Praxis
Die Theorie ist beeindruckend, aber die praktischen Ergebnisse bestätigen das enorme Potenzial. Das Tencent-Team testete R-Zero an verschiedenen Basismodellen, darunter Qwen3 und OctoThinker in Größen von 3 bis 8 Milliarden Parametern.
Leistungssteigerung bei mathematischen Benchmarks:
| Modell | Basis-Performance (AVG) | R-Zero Performance (AVG) | Verbesserung |
| Qwen3-4B-Base | 42.58 | 49.07 | +6.49 Punkte |
| Qwen3-8B-Base | 49.18 | 54.69 | +5.51 Punkte |
Generalisierung auf allgemeine Denkaufgaben (obwohl nur mit Mathe trainiert):
| Modell | Basis-Performance (AVG) | R-Zero Performance (AVG) | Verbesserung |
| Qwen3-4B-Base | 27.10 | 34.64 | +7.54 Punkte |
| Qwen3-8B-Base | 34.49 | 38.73 | +4.24 Punkte |
Diese Zahlen belegen zwei entscheidende Punkte: Erstens funktioniert R-Zero über verschiedene Modellgrößen und Architekturen hinweg. Zweitens – und das ist vielleicht noch erstaunlicher – führt das spezialisierte Training auf mathematische Probleme zu einer generellen Verbesserung der logischen Denkfähigkeit, die sich auf völlig andere Domänen überträgt.
Die Grenzen von R-Zero: Wo die autonome KI an ihre Grenzen stößt
Trotz des revolutionären Potenzials ist R-Zero kein Allheilmittel. Es gibt klare Einschränkungen und Herausforderungen, die für die zukünftige Forschung entscheidend sein werden.
- Domänen-Abhängigkeit: Derzeit funktioniert der Mechanismus am besten in Domänen mit objektiv verifizierbaren, richtigen oder falschen Antworten, wie Mathematik oder Programmierung. Die Erweiterung auf offene, subjektive Aufgaben wie kreatives Schreiben oder Dialogführung ist eine massive Hürde.
- Qualitätsverlust der Pseudo-Label: Die Analyse im Paper zeigt einen beunruhigenden Trend: Während der Challenger immer schwierigere Fragen stellt, sinkt die Genauigkeit der durch Mehrheitsentscheid erzeugten Pseudo-Labels (von 79% auf 63% in drei Iterationen). Das System könnte sich also an einem Punkt selbst vergiften, wenn die selbst erzeugten „Wahrheiten“ zu unzuverlässig werden.
- Hoher Rechenaufwand: Der co-evolutionäre Prozess, bei dem für jede Frage mehrfach Antworten generiert und Modelle iterativ trainiert werden, ist rechenintensiv.
- Vermeidung von Exploits: Es muss sichergestellt werden, dass der Challenger nicht lernt, „Fehler“ im Solver auszunutzen, anstatt wirklich sinnvolle, schwierige Probleme zu generieren. Die eingebaute Repetitionsstrafe ist ein erster Schritt, aber dies bleibt eine Herausforderung.
Die Zukunft ist autonom: Was R-Zero für die Jagd nach AGI bedeutet
R-Zero ist mehr als nur eine clevere neue Trainingsmethode. Es ist ein fundamentaler Paradigmenwechsel, der weitreichende Konsequenzen hat.
- Demokratisierung der KI: Kleinere Forschungsteams und Unternehmen, die sich keine riesigen Daten-Annotationsteams leisten können, erhalten Zugang zu einer Methode, um hochleistungsfähige LLMs zu entwickeln.
- Beschleunigung der Forschung: Indem der langsamste Teil des Entwicklungszyklus wegfällt, können neue Architekturen und Ideen viel schneller getestet und iteriert werden.
- Ein Schritt Richtung Superintelligenz: Die Fähigkeit einer KI, ihre eigene Wissensgrenze zu erkennen und gezielt daran zu lernen, ist eine Grundvoraussetzung für Systeme, die eines Tages menschliche Intelligenz übertreffen könnten. R-Zero liefert hierfür einen funktionierenden Prototyp.
- Synergie mit existierenden Methoden: Die Forschung zeigt auch, dass R-Zero als eine Art „Vor-Training“ dienen kann. Modelle, die zuerst mit R-Zero verbessert wurden, erreichen nach anschließendem Training mit gelabelten Daten eine noch höhere Leistung (+2,35 Punkte über dem Standard-Training).
Empfohlene Tools & Ressourcen
Für alle, die tiefer in die Materie eintauchen möchten, sind hier die wichtigsten Ressourcen direkt von den Entwicklern:
- Das Original-Forschungspapier: „R-Zero: Self-Evolving Reasoning LLM from Zero Data“ auf arXiv für alle technischen Details.
- Der offizielle Code: Das GitHub-Repository (Chengsong-Huang/R-Zero) für die praktische Implementierung und zum Experimentieren.
- EasyR1 Codebase: Das Framework basiert auf dieser Codebase, die für Reinforcement-Learning-Experimente mit LLMs entwickelt wurde.
Häufig gestellte Fragen zu Tencent R-Zero
H2: Häufig gestellte Fragen zu Tencent R-Zero
Was bedeutet das „Zero“ in R-Zero? Das „Zero“ steht für „Zero external data“. Es unterstreicht die Fähigkeit des Frameworks, LLMs von Grund auf zu trainieren, ohne auf externe, von Menschen kuratierte Aufgaben oder gelabelte Datensätze angewiesen zu sein.
Ist R-Zero dasselbe wie Self-Play in Spielen wie AlphaGo? Es gibt eine konzeptionelle Ähnlichkeit, da das System gegen sich selbst spielt, um besser zu werden. Der entscheidende Unterschied liegt im Belohnungsmechanismus. AlphaGo hatte klare Spielregeln und ein binäres Ergebnis (Sieg/Niederlage). R-Zero muss seinen eigenen Belohnungsmechanismus in einer offenen Domäne durch die Messung von „Unsicherheit“ erst erschaffen.
Kann R-Zero verwendet werden, um eine kreative Schreib-KI zu trainieren? Derzeit nicht. Die Methode ist auf Domänen mit objektiv bewertbaren Ergebnissen angewiesen. Bei kreativem Schreiben gibt es keine einzelne „richtige“ Antwort, was die Generierung von zuverlässigen Pseudo-Labels und einer klaren Belohnungsfunktion extrem schwierig macht. Dies ist eine der größten Herausforderungen für die Zukunft.
Wie verhindert R-Zero, dass die KI sich selbst falsche Informationen beibringt? Durch einen mehrstufigen Qualitätssicherungsprozess: 1. Mehrheitsentscheid (Majority Voting): Die wahrscheinlichste Antwort aus vielen Versuchen wird zum Pseudo-Label. 2. Konsistenz-Filterung: Nur Aufgaben, bei denen eine moderate, aber nicht vollständige Übereinstimmung herrscht, werden verwendet. Dies filtert inkonsistente (und damit wahrscheinlich falsche) Pseudo-Label heraus. Dennoch ist dies eine Schwachstelle, da die Genauigkeit der Labels mit steigender Schwierigkeit sinkt.
Ist der Code für R-Zero Open Source? Ja, die Forscher haben den Code auf GitHub veröffentlicht, was es der breiteren KI-Community ermöglicht, auf dieser Arbeit aufzubauen, sie zu überprüfen und sie für eigene Projekte zu nutzen.
Welche Hardware wird benötigt, um R-Zero zu implementieren? Das Paper erwähnt den Einsatz leistungsfähiger GPUs. Der Prozess des co-evolutionären Trainings mit mehrfachem Sampling ist rechenintensiv. Es ist also eine erhebliche Menge an Rechenleistung erforderlich, die typischerweise in Forschungsclustern oder bei Cloud-Anbietern zu finden ist.
Was ist der größte Vorteil von R-Zero gegenüber traditionellen Methoden? Der größte Vorteil ist die Eliminierung des Daten-Labeling-Engpasses. Dies spart nicht nur enorme Mengen an Zeit und Geld, sondern ermöglicht auch eine bisher unerreichte Skalierbarkeit und befreit die KI-Entwicklung von den inhärenten Beschränkungen und Vorurteilen menschlich erstellter Datensätze.
Der Co-Evolutionäre Kompromiss: Zwischen Schwierigkeit und Datengenauigkeit
Eine der faszinierendsten und zugleich kritischsten Erkenntnisse aus der R-Zero-Forschung ist der inhärente Zielkonflikt des Systems. Während der co-evolutionäre Prozess die Modelle immer leistungsfähiger macht, stößt er an eine natürliche Grenze, die durch die Genauigkeit der selbst erzeugten Daten definiert wird. Die Analyse des Tencent-Teams (siehe Tabelle 4 im Paper) enthüllt diese Dynamik schonungslos.
Was passiert?
- Der Challenger wird immer besser darin, intrinsisch schwierigere Fragen zu stellen.
- Dadurch sinkt die Fähigkeit des Solvers, durch Mehrheitsentscheid ein verlässliches „Pseudo-Label“ zu erzeugen.
- Das Ergebnis: Die Qualität des selbstgenerierten Trainingsdatensatzes nimmt über die Iterationen ab, obwohl die Fähigkeiten der Modelle zunehmen.
Die Daten im Klartext:
| Trainings-Iteration | Schwierigkeit der Fragen (Lösungsrate für ein fixes Modell) | Genauigkeit der Pseudo-Label (vs. Ground Truth) |
| Iteration 1 | 59.0% | 79.0% |
| Iteration 2 | 53.0% | 69.0% |
| Iteration 3 | 47.0% | 63.0% |
Diese Gratwanderung ist entscheidend: R-Zero muss eine Balance finden zwischen der Generierung maximal herausfordernder Aufgaben und der Aufrechterhaltung einer ausreichend hohen Datenqualität, um ein stabiles Lernen zu gewährleisten. Zukünftige Versionen des Frameworks könnten intelligentere Mechanismen zur Wahrheitsfindung benötigen, die über einen einfachen Mehrheitsentscheid hinausgehen, um dieses Plateau zu durchbrechen.
Praktische Anwendungsfälle: Welche Branchen R-Zero revolutionieren wird
Die Fähigkeit, komplexe Probleme ohne menschliche Vorgaben zu lösen, eröffnet revolutionäre Möglichkeiten in Sektoren, die auf verifizierbare Ergebnisse angewiesen sind. R-Zero ist nicht nur ein Forschungsprojekt; es ist ein Vorbote für eine neue Klasse von KI-Anwendungen.
- Softwareentwicklung & Cybersicherheit: Stellen Sie sich einen R-Zero-Agenten vor, der unermüdlich nach Sicherheitslücken in Code sucht (Challenger), während ein anderer lernt, diese zu schließen (Solver). Dies könnte zu selbstheilender Software führen, die ihre eigenen Schwachstellen entdeckt und behebt, bevor sie ausgenutzt werden können.
- Wissenschaftliche Forschung & Entdeckung: In der Medikamentenentwicklung könnte ein Challenger Molekülstrukturen vorschlagen, die an der Grenze des Bekannten liegen, während ein Solver deren potenzielle Wirksamkeit und Stabilität simuliert. Dieser Prozess könnte die Entdeckung neuer Wirkstoffe massiv beschleunigen.
- Finanzmodellierung: Ein KI-System könnte komplexe Handelsstrategien (Challenger) entwickeln, um Marktineffizienzen auszunutzen. Der Solver würde lernen, die Rentabilität und das Risiko dieser Strategien in Simulationen zu bewerten und so robustere Algorithmen für den Hochfrequenzhandel zu schaffen.
- Logistik & Optimierung: Das Framework könnte zur Lösung extrem komplexer logistischer Probleme eingesetzt werden, wie z.B. der Optimierung globaler Lieferketten unter sich ständig ändernden Bedingungen. Der Challenger erfindet Störungsszenarien (z.B. Hafenschließungen, Nachfrageschocks), der Solver entwickelt optimale Reaktionsstrategien.
Checkliste: Ist ein R-Zero-Ansatz für Ihr Projekt geeignet?
Nicht jede KI-Anwendung kann oder sollte mit einem autonomen Framework wie R-Zero entwickelt werden. Diese Checkliste hilft Ihnen bei der Einschätzung, ob Ihr Problemfeld für diesen revolutionären Ansatz geeignet ist.
Beantworten Sie die folgenden Fragen für Ihr Projekt:
- Gibt es eine objektive Wahrheit?
☐ Ja: Unsere Ergebnisse können klar als „richtig/falsch“, „funktioniert/funktioniert nicht“ oder „optimal/nicht optimal“ bewertet werden (z.B. mathematische Lösungen, erfolgreiche Code-Kompilierung, Erreichen eines Ziels in einer Simulation).☐ Nein: Unsere Ergebnisse sind subjektiv und hängen von menschlicher Interpretation oder Geschmack ab (z.B. Gedichte, Marketingtexte, Kunst). (Wenn Nein, ist R-Zero ungeeignet.)
- Ist die Datengenerierung der Engpass?
☐ Ja: Die Erstellung hochwertiger, gelabelter Trainingsdaten ist für uns extrem teuer, langsam oder praktisch unmöglich.☐ Nein: Wir haben bereits Zugang zu riesigen, gut kuratierten Datensätzen. (Wenn Ja, bietet R-Zero den größten Hebel.)
- Steht logisches Denken im Vordergrund?
☐ Ja: Unser Kernproblem erfordert mehrstufiges logisches Denken, Planung und die Anwendung von Regeln.☐ Nein: Unser Kernproblem ist die Klassifizierung von Daten, die Erkennung von Mustern oder die Nachahmung eines Stils. (R-Zero glänzt besonders bei Problemen, die logisches Denken erfordern.)
- Verfügen Sie über signifikante Rechenressourcen?
☐ Ja: Wir haben Zugang zu einem GPU-Cluster und können die Kosten für intensives, iteratives Reinforcement-Learning-Training tragen.☐ Nein: Unsere Rechenkapazitäten sind stark begrenzt. (Ohne erhebliche Rechenleistung ist die Implementierung unrealistisch.)
Auswertung: Wenn Sie die ersten drei Fragen überwiegend mit „Ja“ beantwortet haben und über die nötige Rechenleistung verfügen, könnte Ihr Projekt ein idealer Kandidat sein, um von einem R-Zero-ähnlichen, selbstlernenden Ansatz zu profitieren und einen Wettbewerbsvorteil zu erzielen.
Fazit: Ein neues Kapitel in der KI-Evolution
Tencents R-Zero ist nicht nur eine weitere inkrementelle Verbesserung in der Welt der künstlichen Intelligenz. Es ist ein fundamentaler Durchbruch, der die Art und Weise, wie wir über das Lehren und Lernen von Maschinen denken, neu definiert. Indem es den Menschen als Lehrer aus der Gleichung nimmt und ein autonomes, sich selbst verbesserndes System schafft, löst es das größte praktische Problem der modernen KI-Entwicklung – die Abhängigkeit von Daten.
Die unmittelbaren Auswirkungen sind eine drastische Kostensenkung und eine Demokratisierung des Zugangs zu Spitzen-KI. Die langfristige Vision ist jedoch weitaus größer: R-Zero liefert einen plausiblen und funktionierenden Bauplan für KI-Systeme, die ihre eigenen Fähigkeiten über das menschliche Wissen hinaus erweitern können. Es ist ein entscheidender, wenn auch früher Schritt auf dem langen und komplexen Weg zur allgemeinen künstlichen Intelligenz (AGI).
Die vor uns liegenden Herausforderungen, insbesondere die Anwendung auf subjektive Domänen und die Sicherstellung der Datenqualität im autonomen Kreislauf, sind immens. Doch der erste, entscheidende Schritt ist getan. R-Zero hat gezeigt, dass die Zukunft der KI nicht nur darin liegt, menschliches Wissen zu verarbeiten, sondern es autonom zu erschaffen und zu übertreffen. Die Evolution hat begonnen.
Quellen und weiterführende Literatur
- Original Paper (arXiv): Huang, C., Yu, W., et al. (2025). R-Zero: Self-Evolving Reasoning LLM from Zero Data. https://arxiv.org/html/2508.05004v1
- Official GitHub Repository: Chengsong-Huang/R-Zero. https://github.com/Chengsong-Huang/R-Zero
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #RZero #Tencent #LLM #Tech2025 #ReinforcementLearning






