
Google hat eine aktualisierte Vorschau seines bisher intelligentesten KI-Modells, Gemini 2.5 Pro, vorgestellt und damit die Messlatte im Bereich der künstlichen Intelligenz erneut höher gelegt. Diese Version, die auf der im Mai präsentierten und auf der I/O-Konferenz gezeigten Variante aufbaut, soll in wenigen Wochen allgemein verfügbar und für unternehmensweite Anwendungen bereit sein. Du fragst Dich, was dieses Modell so besonders macht und wie es sich im Vergleich zur Konkurrenz schlägt? Wir tauchen tief ein, analysieren die neuesten Benchmarks und zeigen Dir, was Du von Gemini 2.5 Pro erwarten kannst – insbesondere im direkten Duell mit Giganten wie OpenAI und Claude.
Die jüngsten Entwicklungen zeigen deutliche Fortschritte: Gemini 2.5 Pro verzeichnet einen beeindruckenden Elo-Score-Anstieg von 24 Punkten auf LMArena, wo es mit 1470 Punkten weiterhin die Rangliste anführt. Auch auf WebDevArena konnte es mit einem Plus von 35 Elo-Punkten und einem Wert von 1443 die Spitzenposition erobern. Besonders hervorzuheben sind die kontinuierlich exzellenten Leistungen im Bereich Coding, wo es anspruchsvolle Benchmarks wie Aider Polyglot dominiert. Doch auch in Sachen Wissen, logisches Denken und wissenschaftliche Fähigkeiten beweist es mit Top-Performance bei GPQA und Humanity’s Last Exam (HLE) seine Überlegenheit. Google hat zudem auf Feedback zur vorherigen Version reagiert und Stil sowie Struktur verbessert, sodass kreativere und besser formatierte Antworten möglich sind.
Für Entwickler eröffnen sich damit neue Möglichkeiten über die Gemini API via Google AI Studio und Vertex AI, wo nun auch „Thinking Budgets“ zur Kosten- und Latenzkontrolle eingeführt wurden. Und das Beste: Die Implementierung in der Gemini-App hat bereits begonnen.
Das musst Du wissen – Gemini 2.5 Pro im Schnellcheck:
- Spitzenleistung in Benchmarks: Gemini 2.5 Pro führt wichtige Ranglisten wie LMArena und WebDevArena an und glänzt bei Coding (Aider Polyglot), Wissen (GPQA) und logischem Denken (HLE).
- Verbesserte Ausgabe: Das Modell liefert nun kreativere und besser strukturierte Antworten, basierend auf Nutzerfeedback.
- Entwicklerfokus: Neue „Thinking Budgets“ in der Gemini API (Google AI Studio, Vertex AI) ermöglichen eine präzisere Kosten- und Latenzkontrolle.
- Wettbewerbsfähige Preise: Mit einem Input-Preis von $1.25 pro 1 Million Tokens (Caching) positioniert sich Gemini 2.5 Pro attraktiv gegenüber Modellen wie OpenAI o3.
- Multimodale Stärken: Obwohl nicht in allen Bereichen führend, zeigt Gemini 2.5 Pro solide Werte in visueller und Videoverarbeitung.
Was ist Gemini 2.5 Pro Neues und was kann es wirklich?
Das von Google präsentierte Upgrade für Gemini 2.5 Pro ist mehr als nur ein kleines Update; es markiert einen signifikanten Schritt nach vorn. Die bereits erwähnten Elo-Score-Steigerungen auf LMArena (auf 1470) und WebDevArena (auf 1443) sind nicht nur Zahlen, sondern Indikatoren für eine verbesserte grundlegende Intelligenz und Problemlösungsfähigkeit. Die Dominanz in Coding-Benchmarks wie Aider Polyglot (82,2% diff-fenced) unterstreicht die Ambitionen von Google, Entwicklern ein extrem leistungsfähiges Werkzeug an die Hand zu geben. Diese Fähigkeit ist entscheidend, da die Generierung und Bearbeitung von Code zu den komplexesten Aufgaben für KI-Modelle gehört und einen direkten Produktivitätsgewinn für Unternehmen und einzelne Programmierer darstellt.
Neben der reinen Rechenleistung und Coding-Expertise wurde auch das „Auftreten“ des Modells überarbeitet. Die Fähigkeit, kreativer zu sein und Antworten in einer ansprechenderen, besser formatierten Weise zu präsentieren, verbessert die Nutzererfahrung erheblich. Dies ist besonders relevant für Anwendungen, die direkten Kundenkontakt haben oder bei denen die Lesbarkeit und Ästhetik der Ausgabe eine Rolle spielen. Die Integration von „Thinking Budgets“ in Google AI Studio und Vertex AI adressiert einen wichtigen Punkt für Entwickler und Unternehmen: die Kontrolle über Ausgaben und Performance. Indem Entwickler Budgets für die „Denkzeit“ des Modells festlegen können, lässt sich ein optimales Gleichgewicht zwischen Antwortqualität, Geschwindigkeit und Kosten für spezifische Anwendungsfälle finden. Die allgemeine Verfügbarkeit in wenigen Wochen signalisiert zudem, dass Google von der Stabilität und Skalierbarkeit dieser Version überzeugt ist, bereit für den Einsatz in großem Maßstab.
KI-Modelle im direkten Vergleich: Die Benchmark-Analyse
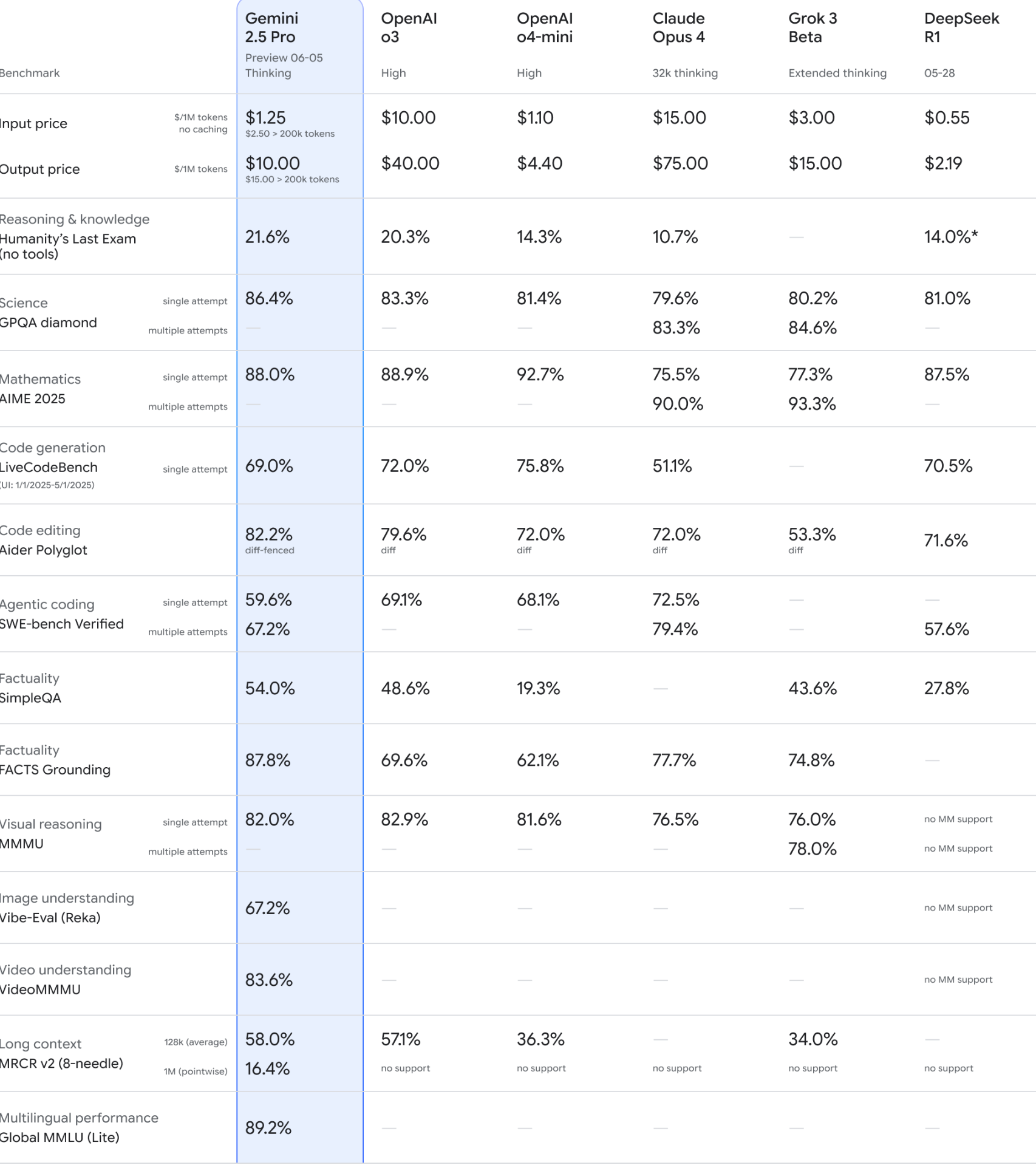
Um die Leistungsfähigkeit von Gemini 2.5 Pro wirklich einschätzen zu können, ist ein Blick auf die Konkurrenz unerlässlich. Die bereitgestellten Benchmark-Daten ermöglichen einen detaillierten Vergleich mit anderen führenden Modellen wie OpenAIs GPT-Modellen, Claude Opus 4, Grok 3 Beta und DeepSeek R1.
Preisgestaltung im Fokus
Die Kosten für die Nutzung von KI-Modellen sind ein entscheidender Faktor, besonders bei hochvolumigen Anwendungen. Hier eine Übersicht der Input- und Output-Preise pro 1 Million Tokens:
| Modell | Input Preis ($/1M tokens) | Output Preis ($/1M tokens) | Hinweis |
| Gemini 2.5 Pro | $1.25 (no caching) | $10.00 | $2.50 > 200k tokens (Input) |
| ($2.50 > 200k tokens no caching) | ($15.00 > 200k tokens no caching) | $15.00 > 200k tokens (Output) | |
| OpenAI o3 | $10.00 | $40.00 | High |
| OpenAI o4-mini | $1.10 | $4.40 | High |
| Claude Opus 4 | $15.00 | $75.00 | 32k thinking |
| Grok 3 Beta | $3.00 | $15.00 | Extended thinking |
| DeepSeek R1 | $0.55 | $2.19 | 05-28 (vermutlich Datum des Preisstands) |
Gemini 2.5 Pro positioniert sich mit $1.25 (Input, bis 200k Tokens, ohne Caching) preislich sehr attraktiv, insbesondere im Vergleich zum teureren OpenAI o3 und Claude Opus 4. DeepSeek R1 ist zwar nominell am günstigsten, jedoch muss hier die Gesamtleistung in Betracht gezogen werden. OpenAI o4-mini ist ebenfalls sehr preiswert, aber tendenziell auch in den Leistungsbenchmarks etwas niedriger angesiedelt als die Top-Modelle.
Leistungsbenchmarks: Ein detaillierter Blick
Die Performance in standardisierten Tests gibt Aufschluss über die spezifischen Stärken und Schwächen der Modelle. Betrachten wir einige Schlüsselkategorien:
Tabelle ausgewählter Leistungsbenchmarks:
| Benchmark | Gemini 2.5 Pro | OpenAI o3 | OpenAI o4-mini | Claude Opus 4 | Grok 3 Beta | DeepSeek R1 |
| Reasoning & knowledge (HLE, no tools) | 21.6% | 20.3% | 14.3% | 10.7% | — | 14.0%* |
| Science (GPQA diamond, single attempt) | 86.4% | 83.3% | 81.4% | 79.6% | 80.2% | 81.0% |
| Mathematics (AIME 2025, single attempt) | 88.0% | 88.9% | 92.7% | 75.5% | 77.3% | 87.5% |
| Code generation (LiveCodeBench) | 69.0% | 72.0% | 75.8% | 51.1% | — | 70.5% |
| Code editing (Aider Polyglot, diff-fenced) | 82.2% | 79.6% | 72.0% | 72.0% | 53.3% | 71.6% |
| Agentic coding (SWE-bench Verified, single/multiple attempts) | 59.6% / 67.2% | 69.1% / — | 68.1% / — | 72.5% / 79.4% | — / — | — / 57.6% |
| Factuality (SimpleQA) | 54.0% | 48.6% | 19.3% | — | 43.6% | 27.8% |
| Factuality (FACTS Grounding) | 87.8% | 69.6% | 62.1% | 77.7% | 74.8% | — |
| Visual reasoning (MMMU, single attempt) | 82.0% | 82.9% | 81.6% | 76.5% | 76.0% | no MM support |
| Long context (MRCR v2 (8-needle), 128k avg / 1M pointwise) | 58.0% / 16.4% | 57.1% / no support | 36.3% / no support | — / no support | 34.0% / no support | — / no support |
Analyse der Benchmark-Ergebnisse:
- Reasoning & Knowledge (HLE): Gemini 2.5 Pro (21.6%) führt hier knapp vor OpenAI o3 (20.3%). Dies deutet auf eine starke Fähigkeit hin, komplexe Schlussfolgerungen ohne externe Werkzeuge zu ziehen.
- Science (GPQA diamond): Mit 86.4% im Single Attempt liegt Gemini 2.5 Pro an der Spitze und demonstriert ein tiefes wissenschaftliches Verständnis.
- Mathematics (AIME 2025): Hier zeigt Gemini 2.5 Pro mit 88.0% eine sehr starke Leistung, wird jedoch knapp von OpenAI o3 (88.9%) und OpenAI o4-mini (92.7%) übertroffen. DeepSeek R1 ist mit 87.5% ebenfalls sehr konkurrenzfähig.
- Code Generation (LiveCodeBench): OpenAI o4-mini (75.8%) und OpenAI o3 (72.0%) liegen hier vor Gemini 2.5 Pro (69.0%). Dies ist ein Bereich, in dem die OpenAI-Modelle traditionell stark sind.
- Code Editing (Aider Polyglot): Hier glänzt Gemini 2.5 Pro mit 82.2% (diff-fenced) und übertrifft alle direkten Konkurrenten deutlich. Dies ist ein Beleg für seine Fähigkeit, bestehenden Code präzise zu analysieren und zu modifizieren.
- Agentic Coding (SWE-bench Verified): Bei multiplen Versuchen (67.2%) zeigt Gemini 2.5 Pro eine solide Leistung, wird aber von Claude Opus 4 (79.4% bei multiplen Versuchen) übertroffen. Die Fähigkeit, komplexe Software-Engineering-Aufgaben zu lösen, ist hier im Fokus.
- Factuality (SimpleQA & FACTS Grounding): Gemini 2.5 Pro dominiert in beiden Faktizitäts-Benchmarks (54.0% bzw. 87.8%), was auf eine hohe Zuverlässigkeit bei der Wiedergabe von Fakten und der Verankerung von Aussagen in Daten hindeutet.
- Visual Reasoning (MMMU): Mit 82.0% (Single Attempt) liegt Gemini 2.5 Pro auf Augenhöhe mit OpenAI o3 (82.9%) und o4-mini (81.6%), was seine starken multimodalen Fähigkeiten unterstreicht. Modelle wie DeepSeek R1 bieten hier keine Unterstützung.
- Long Context (MRCR v2): Im Bereich der Verarbeitung langer Kontexte (128k average: 58.0%, 1M pointwise: 16.4%) zeigt Gemini 2.5 Pro führende Werte, insbesondere bei sehr langen, punktuellen Abfragen, wo viele andere Modelle keine Unterstützung bieten oder schwächer abschneiden.
Diese datengestützte Analyse zeigt, dass Gemini 2.5 Pro in vielen kritischen Bereichen führend oder zumindest sehr wettbewerbsfähig ist. Besonders die Stärken im Bereich Reasoning, Science, Code Editing und Factuality, gepaart mit einem attraktiven Preis, machen es zu einer interessanten Option.
Stärken und Herausforderungen der Konkurrenten
- OpenAI o3 und o4-mini: Diese Modelle bleiben stark in der Code-Generierung und Mathematik (o4-mini). Die Preise variieren, wobei o4-mini eine sehr kostengünstige Alternative darstellt, allerdings mit teilweise geringerer Spitzenleistung.
- Claude Opus 4: Zeigt besondere Stärke im Agentic Coding bei multiplen Versuchen, ist jedoch preislich am oberen Ende angesiedelt.
- Grok 3 Beta: Liefert solide Ergebnisse in einigen Benchmarks wie Science und Mathematics, bietet aber nicht in allen Bereichen Daten.
- DeepSeek R1: Überrascht mit sehr niedrigen Preisen und guten Ergebnissen in Mathematik und teilweise Science, hat aber Defizite im multimodalen Bereich und bei einigen Faktizitäts-Tests.
Besondere Merkmale und Anwendungsbereiche von Gemini 2.5 Pro
Die Verbesserungen in Stil und Struktur machen Gemini 2.5 Pro nicht nur leistungsfähiger, sondern auch angenehmer und effektiver in der Anwendung. Du kannst kreativere Textformen, besser gegliederte Zusammenfassungen oder klarer formatierte Code-Snippets erwarten. Die „Thinking Budgets“ sind ein Segen für Entwickler, die maßgeschneiderte Lösungen bauen. Stell Dir vor, Du entwickelst eine Anwendung, bei der schnelle, aber vielleicht nicht bis ins letzte Detail perfekte Antworten für manche Anfragen ausreichen, während für andere höchste Präzision erforderlich ist – genau das kannst Du jetzt feingranular steuern.
Für wen eignet sich Gemini 2.5 Pro also?
- Entwickler und Tech-Unternehmen: Die exzellenten Coding-Fähigkeiten (insbesondere Code Editing), die API-Zugänglichkeit mit Kostenkontrolle und die starke Performance in Reasoning und Science machen es ideal für die Entwicklung von KI-gestützten Tools, Forschungsanwendungen und komplexen Backend-Systemen.
- Content-Ersteller und Marketer: Die verbesserten kreativen und formatierenden Fähigkeiten können bei der Erstellung von hochwertigem Content, Marketingmaterialien und personalisierten Nutzererlebnissen helfen.
- Unternehmen mit Bedarf an Faktentreue: Die hohen Werte in den Faktizitäts-Benchmarks prädestinieren Gemini 2.5 Pro für Anwendungen, bei denen es auf korrekte Informationen ankommt, z.B. im Wissensmanagement oder bei der automatisierten Berichterstellung.
- Anwender, die lange Kontexte verarbeiten müssen: Die führende Rolle im MRCR v2 Benchmark zeigt, dass Gemini 2.5 Pro große Mengen an Informationen effizient verarbeiten und darin spezifische Details finden kann.
Der anstehende allgemeine Release und die Integration in die Gemini-App werden die Reichweite und Anwendbarkeit dieses fortschrittlichen KI-Modells weiter erhöhen. Es ist ein klarer Schritt Googles, seine Position an der Spitze der KI-Entwicklung zu festigen und Nutzern wie Dir leistungsstarke, flexible und zunehmend kosteneffiziente Werkzeuge zur Verfügung zu stellen.
Fazit: Gemini 2.5 Pro setzt (mal wieder) neue Maßstäbe
Die Einführung der aktualisierten Vorschau von Gemini 2.5 Pro ist ein klares Signal im dynamischen Feld der künstlichen Intelligenz. Google hat nicht nur an der reinen Leistungssteigerung geschraubt, was die beeindruckenden Ergebnisse in Benchmarks wie LMArena, WebDevArena, Aider Polyglot, GPQA und HLE eindrücklich belegen, sondern auch maßgeblich auf Nutzerfeedback reagiert. Die Optimierungen in Bezug auf Stil, Struktur und Kreativität der Antworten sowie die Einführung von „Thinking Budgets“ für Entwickler sind praxisnahe Verbesserungen, die den Nutzwert des Modells erheblich steigern.
Im direkten KI-Modell-Vergleich zeigt sich Gemini 2.5 Pro als ein äußerst potenter Allrounder mit spezifischen Spitzenleistungen. Besonders im Bereich Code Editing, Reasoning, wissenschaftlichem Verständnis und Faktizität kann es sich oft an die Spitze setzen oder zumindest in der obersten Liga mitspielen. Die Preisgestaltung, insbesondere für den Input bei Standardkontextlängen, positioniert es attraktiv gegenüber einigen Hauptkonkurrenten wie OpenAI o3 und Claude Opus 4, auch wenn Modelle wie DeepSeek R1 oder OpenAI o4-mini bei den reinen Token-Kosten teilweise noch günstiger sind. Hier muss jedoch immer das Gesamtpaket aus Preis und spezifischer Leistungsfähigkeit für den jeweiligen Anwendungsfall bewertet werden.
Die Leistungsbenchmarks verdeutlichen, dass es „das eine beste KI-Modell“ für alle Aufgaben nicht gibt. Während Gemini 2.5 Pro in vielen Bereichen glänzt, zeigen Konkurrenzmodelle in Nischen wie der reinen Code-Generierung (OpenAI o4-mini) oder speziellen Mathematik-Aufgaben (OpenAI o3/o4-mini) ebenfalls Top-Resultate. Die Stärke von Gemini 2.5 Pro liegt in seiner ausgewogenen hohen Performance über ein breites Spektrum an anspruchsvollen Aufgaben, gepaart mit Entwicklerfreundlichkeit und zunehmender Wirtschaftlichkeit.
Der kontinuierliche Fortschritt und die Fokussierung auf anwendungsrelevante Features deuten darauf hin, dass Google mit Gemini 2.5 Pro eine Schlüsselrolle in der KI-Landschaft 2025 und darüber hinaus spielen wird. Für Dich als Anwender oder Entwickler bedeutet dies Zugang zu einem Werkzeug, das sowohl intellektuell herausragende Fähigkeiten besitzt als auch in der praktischen Anwendung durchdacht und flexibel ist. Die kommenden Wochen bis zur allgemeinen Verfügbarkeit werden spannend zu beobachten sein.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
—
Quellen
- Google Blog: Gemini 2.5 Pro latest preview: https://blog.google/products/gemini/gemini-2-5-pro-latest-preview/
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #GeminiPro #AIbenchmark #GoogleAI #TechUpdate2025, Gemini 2.5 Pro






