

Die Landschaft der Künstlichen Intelligenz (KI) und insbesondere der großen Sprachmodelle (LLMs) explodiert förmlich. Fast wöchentlich erscheinen neue, leistungsfähigere Modelle von Anbietern wie Google, OpenAI, Anthropic und vielen weiteren. Doch wie findest Du heraus, welches Modell für Deine spezifischen Anforderungen wirklich das Beste ist? Genau hier setzt Google LMEval an, ein im Mai 2025 vorgestelltes Open-Source-Framework, das verspricht, die Evaluierung von KI-Modellen grundlegend zu vereinheitlichen und zu vereinfachen. Es ist mehr als nur ein weiteres Tool – es ist ein strategischer Schritt hin zu mehr Transparenz, Vergleichbarkeit und Vertrauen in der KI-Welt. Wir zeigen Dir, was LMEval so besonders macht und wie Du es für Dich nutzen kannst.
In diesem Artikel analysieren wir die Architektur, die Kernfunktionen und die praktischen Anwendungsmöglichkeiten von Google LMEval. Du erfährst, wie es Dir hilft, Modelle wie GPT-4o, Claude 3.7 Sonnet oder Gemini 2.0 Flash objektiv zu bewerten und warum dieser standardisierte Ansatz für Forscher, Entwickler und Unternehmen im Jahr 2025 und darüber hinaus unverzichtbar wird.
OpenAI SimpleQA ist eine weiterer Benchmark, alle Infos dazu hier.
Das Wichtigste in Kürze – Google LMEval auf den Punkt gebracht
- Standardisierte Evaluierung für LLMs und multimodale Modelle (Text, Bild, Code).
- Anbieterübergreifende Kompatibilität durch die clevere LiteLLM-Integration.
- Effiziente Tests dank inkrementeller Evaluierung und Multithreading.
- Umfassende Analysefähigkeiten, inklusive Erkennung von Ausweichstrategien der Modelle.
- Sichere lokale Datenspeicherung und intuitive Ergebnisvisualisierung mit LMEvalboard.

Die Herausforderung: Warum ein neues Framework für KI-Modelltests?
Bevor wir uns Google LMEval genauer ansehen, lass uns kurz beleuchten, warum ein solches Framework überhaupt notwendig wurde. Die KI-Entwicklung gleicht aktuell einem Goldrausch: Jeder Anbieter preist sein Modell als das Nonplusultra an. Benchmarks sind oft inkonsistent, schwer vergleichbar oder auf bestimmte Modelltypen beschränkt. Für Dich als Anwender bedeutet das:
- Hoher Zeitaufwand: Die Evaluierung verschiedener Modelle erfordert oft die Einarbeitung in unterschiedliche APIs und Auswertungsmethoden.
- Fehlende Vergleichbarkeit: Ohne einheitliche Metriken und Testverfahren ist ein fairer Vergleich der tatsächlichen Leistungsfähigkeit kaum möglich.
- Intransparenz: Es ist oft unklar, unter welchen Bedingungen Benchmarks erstellt wurden.
- Schnelle Veralterung: Neue Modelle und Fähigkeiten erfordern eine ständige Anpassung der Testmethoden.
Genau diese Schmerzpunkte adressiert Google mit LMEval. Das Ziel: Ein Framework zu schaffen, das robust, flexibel und zukunftssicher ist, um Dir eine verlässliche Entscheidungsgrundlage zu bieten.
Google LMEval im Detail: Mehr als nur ein weiteres Tool
Google LMEval ist nicht einfach nur eine weitere Software, sondern ein durchdachtes Ökosystem zur Evaluierung von KI-Modellen. Es wurde von Grund auf konzipiert, um die Bewertung von LLMs und multimodalen Modellen über verschiedene Anbietergrenzen hinweg zu standardisieren und zu beschleunigen. „Google betont, dass LMEval von Grund auf entwickelt wurde, um mit dem rasanten Tempo neuer Modellveröffentlichungen Schritt zu halten und schnelle, zuverlässige Bewertungen zu ermöglichen,“ so die Kernaussage aus den Ankündigungen (frei nach Quelle 1, 2).

Herzstück Architektur: LiteLLM als Brückenbauer
Ein technisches Kernstück von Google LMEval ist die Integration des LiteLLM-Frameworks. Stell Dir LiteLLM als einen universellen Adapter vor: Es übersetzt Deine Anfragen so, dass sie von den spezifischen APIs verschiedener Anbieter (wie OpenAI, Google Vertex AI, Anthropic, Hugging Face, Ollama etc.) verstanden werden. Gleichzeitig sorgt es dafür, dass die Ergebnisse in einem einheitlichen Format zurückkommen.
Das bedeutet für Dich: Du musst Dich nicht mehr mit den Eigenheiten jeder einzelnen API herumschlagen. LMEval nimmt Dir diese Komplexität ab und ermöglicht es Dir, Modelle von Google, OpenAI, Anthropic und vielen anderen über einen standardisierten Prozess zu evaluieren. Diese „Out-of-the-Box“-Kompatibilität ist ein enormer Vorteil und spart wertvolle Entwicklungszeit.
Multimodalität und intelligente Analyse im Fokus
Die wahre Stärke moderner KI-Modelle liegt oft in ihrer Fähigkeit, verschiedene Datentypen zu verarbeiten. Google LMEval trägt dem Rechnung, indem es nicht nur Text-, sondern auch Bild- und Code-Evaluierungen unterstützt. Du kannst also umfassend testen, wie gut ein Modell beispielsweise Code generiert, Bilder interpretiert oder komplexe textbasierte Aufgaben löst.
Besonders spannend ist die Fähigkeit von LMEval, sogenannte „Punting-Strategien“ oder „Ausweichmanöver“ zu erkennen. Das sind Versuche von Modellen, absichtlich vage oder ausweichende Antworten zu geben, um die Generierung problematischer oder riskanter Inhalte zu vermeiden. Diese Funktion ist besonders wichtig für Sicherheits- und Zuverlässigkeitsbewertungen.
Intelligente Effizienz: Der inkrementelle Evaluierungs-Motor
Ein herausragendes Merkmal von Google LMEval ist seine intelligente, inkrementelle Evaluierungs-Engine. Stell Dir vor, Du hast bereits eine Reihe von Modellen getestet und es kommt ein neues Modell hinzu oder Du möchtest ein bestehendes Modell mit einem neuen Prompt testen. Anstatt die gesamte Testsuite erneut durchlaufen zu lassen, führt LMEval nur die wirklich notwendigen neuen Evaluierungen durch.
Zeit und Kosten sparen: So funktioniert’s
Dieser inkrementelle Ansatz spart nicht nur massiv Zeit, sondern auch Rechenressourcen und damit Kosten. Das System analysiert, welche Tests aufgrund von Änderungen (neues Modell, neuer Prompt, neue Frage) tatsächlich neu ausgeführt werden müssen. Das ist besonders in agilen Entwicklungsumgebungen oder bei umfangreichen Vergleichsstudien ein unschätzbarer Vorteil.
Multithreading für den Performance-Boost
Um auch große Evaluierungsläufe zügig zu bewältigen, setzt LMEval auf eine Multithreading-Engine. Diese ermöglicht die parallele Ausführung mehrerer Berechnungen und beschleunigt den gesamten Prozess erheblich. So kannst Du auch umfangreiche Benchmark-Suiten oder Tests mit vielen Modellen gleichzeitig effizient durchführen.
Sicherheit und Datenschutz: Ein kritisches Fundament
Bei der Evaluierung von KI-Modellen, insbesondere mit eigenen, möglicherweise sensiblen Datensätzen, spielt Sicherheit eine übergeordnete Rolle. Google LMEval legt hierauf einen besonderen Fokus. Benchmark-Daten und Evaluierungsergebnisse werden verschlüsselt in einer lokalen, selbstverschlüsselnden SQLite-Datenbank gespeichert. Dies schützt Deine Daten vor unbefugtem Zugriff und verhindert, dass sie von Suchmaschinen indiziert werden können, während sie für Dich zugänglich bleiben.
LMEval in der Praxis: So startest Du Deine erste Evaluierung
Obwohl Google LMEval ein mächtiges Framework ist, wurde auf eine einfache Nutzung Wert gelegt. Hier ist ein konzeptioneller Ablauf, wie Du Deine erste Evaluierung starten könntest:
- Installation: LMEval ist als Python-Paket verfügbar und kann einfach via
pip install lmevalinstalliert werden. - Benchmark-Definition: Du definierst die Aufgaben (Tasks), die evaluiert werden sollen. Das kann beispielsweise das Beantworten von Ja/Nein-Fragen, Multiple-Choice-Aufgaben oder die Generierung von freiem Text sein. Du legst Prompts, ggf. Bilder oder Code-Snippets und die erwarteten Ergebnisse oder Bewertungskriterien fest.
- Modell-Spezifikation: Du wählst die Modelle aus, die Du testen möchtest, und konfigurierst den Zugriff über die LiteLLM-Schnittstelle.
- Evaluierung durchführen: Die
Evaluator-Klasse in LMEval plant und führt die Tests gemäß Deiner Definition aus. Dank der inkrementellen Engine werden nur notwendige Tests gestartet. - Ergebnisse analysieren: Die Resultate werden in der SQLite-Datenbank gespeichert und können anschließend mit LMEvalboard visualisiert oder für tiefere Analysen beispielsweise in Pandas exportiert werden.
Die offizielle GitHub-Seite (siehe Quellen) bietet detaillierte Anleitungen und Beispiel-Notebooks, die Dir den Einstieg erleichtern.
LMEvalboard: Ergebnisse visualisieren und verstehen
Was nützen die besten Daten, wenn man sie nicht interpretieren kann? Hier kommt LMEvalboard ins Spiel, ein interaktives Dashboard, das mit Google LMEval ausgeliefert wird. Es ermöglicht Dir, die Evaluierungsergebnisse aus verschiedenen Perspektiven zu betrachten:
- Gesamtperformance-Metriken: Erhalte einen schnellen Überblick über die Leistung.
- Einzelmodell-Analyse: Tauche tief in die Stärken und Schwächen eines spezifischen Modells ein, oft dargestellt in intuitiven Radar-Charts, die Performance über verschiedene Kategorien visualisieren.
- Modellvergleiche: Stelle mehrere Modelle direkt gegenüber, um Unterschiede klar zu erkennen.
- Drill-Down-Analysen: Untersuche spezifische Fragen und Antworten, um das Verhalten der Modelle im Detail nachzuvollziehen.
Diese Visualisierungshilfe ist essenziell, um komplexe Testergebnisse greifbar zu machen und fundierte Entscheidungen für die Auswahl und den Einsatz von KI-Modellen zu treffen.
Bist Du bereit, Deine LLM-Evaluierungen auf das nächste Level zu heben? Entdecke die Potenziale von Google LMEval für Deine Projekte und triff fundiertere Entscheidungen bei der Modellauswahl. Weiterführende Links und die GitHub-Seite findest Du am Ende des Artikels!
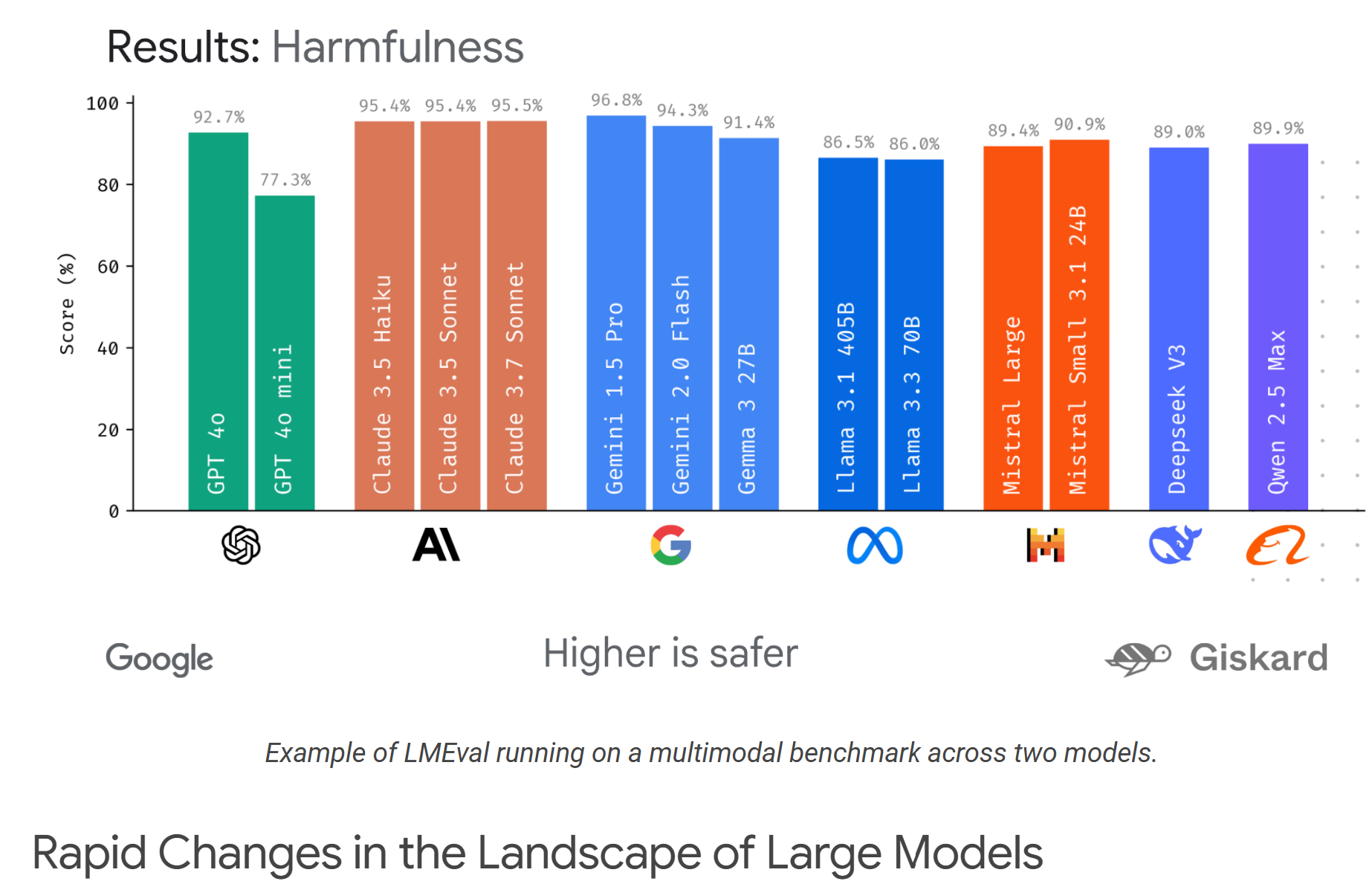
Anwendungsfälle und erste Erfolge: Der Phare LLM Benchmark
Die Praxistauglichkeit von Google LMEval zeigt sich bereits in konkreten Projekten. Ein prominentes Beispiel ist der Phare LLM Benchmark, der in Zusammenarbeit mit Giskard entwickelt wurde. Dieser spezielle Benchmark fokussiert sich auf die Sicherheit und Zuverlässigkeit von LLMs und bewertet kritische Aspekte wie:
- Resistenz gegen Halluzinationen (Falschaussagen)
- Faktische Korrektheit
- Erkennung von Bias (Verzerrungen)
- Bewertung potenzieller schädlicher Ausgaben
Die Entwicklung des Phare Benchmarks mit LMEval unterstreicht die Flexibilität des Frameworks und sein Potenzial, auch spezialisierte und anspruchsvolle Bewertungsanforderungen im Bereich KI-Sicherheit zu adressieren. Diese Kollaboration wurde auch auf dem InCyber Forum Europe im April 2025 vorgestellt.
Ein Blick auf die Konkurrenz: Wie schlägt sich LMEval?
Google LMEval ist nicht das erste Framework zur Evaluierung von Sprachmodellen, aber es bringt einige entscheidende Vorteile mit. Bekannte Alternativen sind beispielsweise:
- EleutherAI’s LM Evaluation Harness: Ein etabliertes Framework mit einer breiten Abdeckung von über 60 Benchmarks und der Möglichkeit, eigene Tests via YAML zu definieren. Es ist sehr umfassend, hat aber seinen Fokus primär auf Text und die Konfiguration kann komplexer sein.
- Harbor Bench: Dieses Framework ist auf Text-Prompts beschränkt, bietet aber die interessante Funktion, ein anderes LLM zur Beurteilung der Ergebnisqualität heranzuziehen.
Gegenüber diesen und anderen Lösungen positioniert sich LMEval durch folgende Alleinstellungsmerkmale:
- Echte Multimodalität: Die native Unterstützung für Text, Bild und Code ist ein signifikanter Vorteil.
- Nahtlose Cross-Provider-Integration via LiteLLM: Vereinfacht das Testen von Modellen verschiedenster Anbieter enorm.
- Inkrementelle Evaluierung: Spart Zeit und Ressourcen.
- Integrierte Sicherheitsfeatures: Verschlüsselung und Detektion von Ausweichstrategien.
- LMEvalboard: Ein leistungsstarkes, integriertes Visualisierungstool.
Diese Kombination macht Google LMEval zu einer äußerst attraktiven Option für alle, die eine moderne, effiziente und umfassende Lösung für die Bewertung von KI-Modellen im Jahr 2025 suchen.
LMEval einrichten und nutzen: Dein Quick-Start Guide
Hier eine kompakte Anleitung, um Dir den technischen Einstieg in Google LMEval zu erleichtern und Deine eigenen Evaluierungen zu starten:
- Voraussetzungen prüfen: Stelle sicher, dass Du eine aktuelle Python-Version (meist 3.8+) installiert hast.
- LMEval installieren: Öffne Dein Terminal oder Deine Kommandozeile und gib den Befehl
pip install lmevalein. Damit wird das Paket aus dem Python Package Index (PyPI) heruntergeladen und installiert. - (Optional) Entwicklungsumgebung einrichten: Wenn Du zur Entwicklung von LMEval beitragen oder tiefere Anpassungen vornehmen möchtest, empfiehlt sich die Einrichtung mit
uv. Folge dazu den Anweisungen auf der GitHub-Seite von LMEval (z.B.uv venvunduv pip install -e .). - Beispiel-Notebooks erkunden: Der beste Weg, um LMEval kennenzulernen, ist die Nutzung der bereitgestellten Beispiel-Jupyter-Notebooks. Du findest sie im offiziellen GitHub-Repository von Google LMEval. Diese Notebooks führen Dich schrittweise durch die Definition von Benchmarks, die Auswahl von Modellen und die Ausführung von Tests.
- Eigene Evaluierungen konfigurieren: Basierend auf den Beispielen kannst Du beginnen, eigene Benchmark-Szenarien mit Deinen spezifischen Prompts, Daten und den zu testenden Modellen zu erstellen. Definiere Tasks, Questions und nutze die
Evaluator-Klasse, um Deine Tests durchzuführen. - Ergebnisse analysieren: Nach Abschluss der Tests kannst Du die Ergebnisse mit LMEvalboard visualisieren oder die Daten für eigene Analysen in Formate wie Pandas DataFrames exportieren.
Wichtiger Hinweis: Wie im GitHub-Repository vermerkt, ist LMEval (Stand Juni 2025) kein offiziell unterstütztes Google-Produkt. Bei der Nutzung mit privaten Datensätzen solltest Du stets die Datenrichtlinien der jeweiligen Modellanbieter beachten, da Anfragen an deren Server gesendet werden könnten.
Die strategische Bedeutung von LMEval für die KI-Landschaft
Die Einführung von Google LMEval ist mehr als nur die Veröffentlichung eines neuen Tools; es ist ein Signal für die gesamte KI-Branche.
Standardisierung als Fortschrittsmotor
Durch die Bereitstellung eines einheitlichen, anbieterübergreifenden Frameworks treibt Google die Standardisierung von KI-Evaluierungspraktiken maßgeblich voran. Dies fördert nicht nur fairere und transparentere Modellvergleiche, sondern kann auch die Entwicklung robusterer und zuverlässigerer KI-Systeme beschleunigen. Wenn sich die Community auf gemeinsame Standards einigt, können Fortschritte schneller validiert und verbreitet werden.
Demokratisierung der KI-Bewertung
Ein weiterer wichtiger Aspekt ist die Demokratisierung des Zugangs zu hochwertigen Evaluierungswerkzeugen. LMEval, als Open-Source-Projekt, steht Organisationen jeder Größe zur Verfügung – von großen Technologiekonzernen bis hin zu kleineren Forschungseinrichtungen oder Start-ups. Dies ebnet das Spielfeld und ermöglicht es mehr Akteuren, fundierte Entscheidungen über den Einsatz von KI-Modellen zu treffen und zur Qualitätssicherung beizutragen. Die Möglichkeit, neue Modelle schnell zu bewerten, ist in der sich rasant entwickelnden KI-Welt von entscheidender Bedeutung.
Häufig gestellte Fragen – Google LMEval
Hier beantworten wir einige der häufigsten Fragen rund um Google LMEval:
- Was genau ist Google LMEval? Google LMEval ist ein Open-Source-Framework zur standardisierten Evaluierung und zum Benchmarking von großen Sprachmodellen (LLMs) und multimodalen KI-Modellen (Text, Bild, Code) verschiedener Anbieter.
- Welche Vorteile bietet LMEval gegenüber anderen Tools? LMEval zeichnet sich durch seine anbieterübergreifende Kompatibilität (dank LiteLLM), die Unterstützung multimodaler Evaluierungen, eine effiziente inkrementelle Test-Engine, Sicherheitsfeatures wie Datenverschlüsselung und ein integriertes Visualisierungsdashboard (LMEvalboard) aus.
- Wie installiere und nutze ich LMEval? Die Installation erfolgt einfach über
pip install lmeval. Die Nutzung beinhaltet die Definition von Benchmarks (Tasks, Prompts, erwartete Ergebnisse), die Auswahl der zu testenden Modelle und die Ausführung der Evaluierung über die im Framework bereitgestellten Klassen. Beispiel-Notebooks auf GitHub helfen beim Einstieg. - Ist LMEval sicher für meine Daten? LMEval speichert Benchmark-Daten und Ergebnisse in einer lokalen, selbstverschlüsselnden SQLite-Datenbank, um sie vor unbefugtem Zugriff zu schützen. Bei der Evaluierung von Modellen externer Anbieter können jedoch Daten an diese gesendet werden; hier sind die jeweiligen Datenschutzrichtlinien zu beachten.
- Welche Modelle kann ich mit LMEval evaluieren? Dank der LiteLLM-Integration unterstützt LMEval eine breite Palette von Modellen wichtiger Anbieter, darunter Google (z.B. Gemini-Modelle), OpenAI (z.B. GPT-Serie), Anthropic (z.B. Claude-Modelle), sowie Modelle von Hugging Face, Ollama und anderen.
Fazit und Ausblick: Warum Google LMEval 2025 so wichtig ist
Google LMEval tritt zu einem entscheidenden Zeitpunkt auf den Plan. In einer Ära, in der die Leistungsfähigkeit und Komplexität von KI-Modellen exponentiell zunehmen, wird eine standardisierte, zuverlässige und effiziente Evaluierungsmethodik immer wichtiger. Das Framework adressiert zentrale Herausforderungen wie mangelnde Vergleichbarkeit, hohen Zeitaufwand und die Notwendigkeit, multimodale Fähigkeiten umfassend zu testen.
Mit seiner Open-Source-Natur, der cleveren LiteLLM-Integration für anbieterübergreifende Kompatibilität, der inkrementellen Evaluierungs-Engine und dem Fokus auf Sicherheit und Benutzerfreundlichkeit durch LMEvalboard hat Google LMEval das Potenzial, sich als ein De-facto-Standard in der KI-Community zu etablieren. Es ist nicht nur ein Werkzeug für Forscher, die neue Modelle entwickeln, sondern auch für Entwickler und Unternehmen, die fundierte Entscheidungen über den Einsatz von KI in ihren Produkten und Prozessen treffen müssen.
Die erfolgreiche Anwendung im Phare LLM Benchmark zeigt bereits, wie LMEval zur Verbesserung der Sicherheit und Vertrauenswürdigkeit von KI-Systemen beitragen kann. Für Dich bedeutet das: Du erhältst ein mächtiges Instrument an die Hand, um im Dschungel der KI-Modelle den Überblick zu behalten, die Spreu vom Weizen zu trennen und letztendlich die besten und sichersten Lösungen für Deine spezifischen Anwendungsfälle auszuwählen.
Die Weiterentwicklung von Google LMEval wird spannend zu beobachten sein. Angesichts des rasanten Fortschritts im KI-Bereich werden Tools, die Transparenz, Vergleichbarkeit und Qualitätssicherung ermöglichen, immer unverzichtbarer. LMEval ist hier ein wichtiger Schritt in die richtige Richtung und wird voraussichtlich einen signifikanten Beitrag zur Professionalisierung und Standardisierung der KI-Evaluierung im Jahr 2025 und darüber hinaus leisten. Es befähigt Dich, die Potenziale der künstlichen Intelligenz verantwortungsvoll und effektiv zu nutzen.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
- InfoQ: Google LMEval: A Comprehensive Framework for Cross-Provider Large Language Model Evaluation
- Google Open Source Blog: Announcing LMEval an open source framework for cross model evaluation
- GitHub – google/lmeval
- The Decoder: Google releases open source LMEval to benchmark language and multimodal models
- AI Base News (18373) – Google LMEval.
- GitHub – EleutherAI/lm-evaluation-harness
[Hashtags für Social Media]: #GoogleLMEval #LMEval #KIEvaluierung #LLM #MultimodalAI #AIBenchmarking #OpenSourceAI #KuenstlicheIntelligenz #KI2025






