
Grundlagen der o1-Roadmap: Die Arbeit „Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective“ stellt einen strukturierten Ansatz vor, wie sich fortschrittliche Fähigkeiten eines Modells wie OpenAIs o1 mithilfe von Reinforcement Learning (RL) nachbilden lassen. Dabei werden vier zentrale Komponenten identifiziert, die notwendig sind, um die reasoning-Fähigkeiten von o1 zu reproduzieren.
OpenAI o1 markiert einen Meilenstein in der Entwicklung künstlicher Intelligenz (KI). Mit fortschrittlichen Fähigkeiten im Bereich des logischen Denkens, der Problemanalyse und der Selbstkorrektur hebt sich dieses Modell deutlich von seinen Vorgängern ab. Im Zentrum steht eine Roadmap, die auf vier Schlüsselkomponenten basiert: Policy-Initialisierung, Reward-Design, Suche und Lernen. Dieser Artikel beleuchtet, wie diese Prinzipien zusammenwirken und zur Entwicklung von leistungsstarken Large Language Models (LLMs) wie o1 beitragen.
Das musst Du wissen: Die Grundlagen der o1-Roadmap
- Policy-Initialisierung: Der erste Schritt zur Entwicklung von LLMs besteht darin, menschliches Denkverhalten durch Vortraining und Feintuning zu simulieren.
- Reward-Design: Effiziente Belohnungssysteme formen das Verhalten des Modells, sei es durch Prozess- oder Ergebnissignale.
- Suche: Optimierte Suchmethoden wie Monte-Carlo-Baum-Suche (MCTS) verbessern die Qualität von Lösungen während des Trainings und der Inferenz.
- Lernen: Durch Daten, die aus der Suche generiert werden, verfeinert sich die Politik des Modells kontinuierlich, was zu einer übermenschlichen Leistung führen kann.
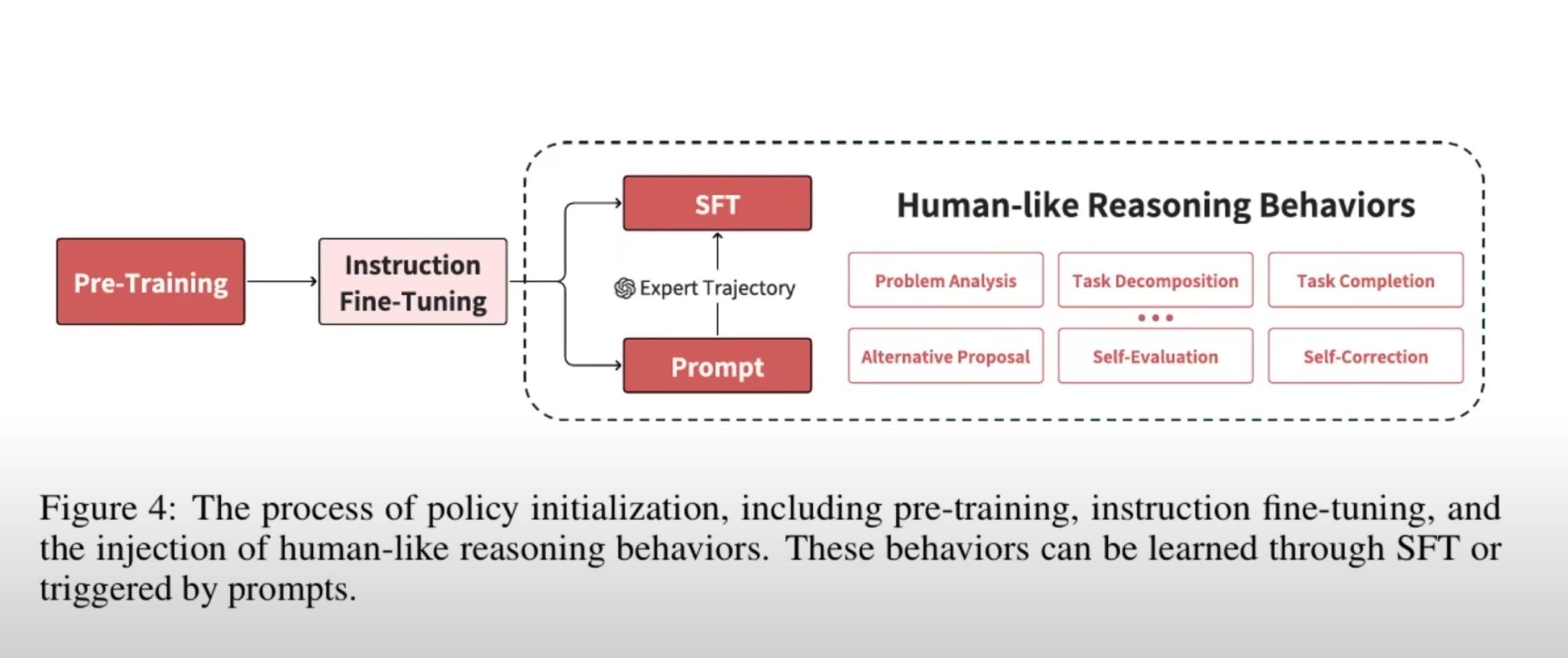
Was macht OpenAI o1 so besonders?
OpenAI o1 hat Fähigkeiten erreicht, die weit über das hinausgehen, was frühere Modelle leisten konnten. Es zeigt menschliches Denkverhalten, wie etwa die Fähigkeit zur Problemanalyse, Aufgabenzerlegung und Selbstkorrektur. Besonders bemerkenswert ist seine Fähigkeit, aus längeren Denkprozessen bessere Lösungen zu generieren.
Wie funktioniert die Roadmap von o1?
Policy-Initialisierung
Die Policy-Initialisierung legt den Grundstein für die menschliche Denkweise in o1. Sie umfasst:
- Vortraining: Aufbau grundlegender Sprach- und Denkfähigkeiten durch riesige Textkorpora.
- Instruction Fine-Tuning: Transformation von Vortrainierten Modellen zu aufgabenorientierten Agenten.
- Menschliches Denkverhalten: Aktivierung von Fähigkeiten wie Problemanalyse, Aufgabenzerlegung und Selbstkorrektur durch feingetunte Trajektorien oder spezielle Eingabeaufforderungen.
Reward-Design
Effektive Belohnungssysteme sind entscheidend, um das Modellverhalten zu formen:
- Ergebnis-Belohnungen: Beurteilen die endgültige Lösung.
- Prozess-Belohnungen: Bewertet Zwischenschritte und fördert eine schrittweise Verbesserung.
- Belohnungsmodellierung: Nutzt Experten- oder Präferenzdaten, um Belohnungssignale zu generieren, wenn keine Umgebungsbelohnungen verfügbar sind.
Suche
Die Suche ist ein zentraler Bestandteil sowohl während des Trainings als auch der Inferenz:
- Interne Führung: Nutzt Modellevaluationen wie Unsicherheitsmessungen oder Selbstbewertungen.
- Externe Führung: Bezieht Feedback aus der Umgebung oder nutzt Heuristiken, um Entscheidungen zu treffen.
- Suchstrategien: Von Monte-Carlo-Baum-Suche (MCTS) bis hin zu Best-of-N-Sampling werden fortschrittliche Techniken genutzt, um qualitativ hochwertige Lösungen zu finden.
Lernen
Das Lernen bei o1 basiert auf datengetriebenen Methoden:
- Verstärkungslernen: Kombiniert die Suchergebnisse mit Techniken wie Policy-Gradient-Methoden.
- Verhaltensklonen: Einfachere Methoden zur Nutzung von Demonstrationsdaten zur Verbesserung der Modellpolitik.
Häufige Fragen zu OpenAI o1 und seiner Roadmap
Wie wird Verstärkungslernen in o1 angewendet?
Verstärkungslernen ist das Kernstück der Roadmap. Es wird verwendet, um die Modellpolitik durch Umgebungsinteraktionen und Belohnungssignale zu optimieren.
Welche Rolle spielt die Suche in der Roadmap?
Die Suche generiert qualitativ hochwertige Lösungen während des Trainings und der Inferenz. Sie ermöglicht es, die besten Ergebnisse durch iterative Verbesserungen zu finden.
Was sind die größten Herausforderungen bei der Nachbildung von o1?
Zu den Hauptschwierigkeiten gehören die Bewältigung von Verteilungsschieflagen in Belohnungsmodellen, die Definition feinkörniger Belohnungen und die Datenanforderungen für komplexe Aufgaben.
Wie beeinflusst das Reward-Design die Leistung?
Ein gut gestaltetes Belohnungssystem beschleunigt das Lernen und verbessert die Sucheffizienz, während schlecht gestaltete Belohnungen das Modellverhalten negativ beeinflussen können.
Praktische Tipps zur Anwendung der o1-Prinzipien
- Policy-Initialisierung: Beginne mit umfassendem Vortraining und fokussiere dich auf domänenspezifisches Feintuning.
- Belohnungssignale: Nutze Prozess-Belohnungen für Aufgaben mit langen Ketten von Zwischenschritten.
- Suchmethoden: Implementiere MCTS oder Best-of-N für komplexe Problemlösungen.
- Selbstbewertung aktivieren: Fördere die Fähigkeit zur Selbstkorrektur durch gezielte Trainingsdaten und Anreize.
OpenAI o1 zeigt, wie verstärkungslerngetriebene Ansätze die Grenzen von KI verschieben können. Mit einer klaren Roadmap, die auf Policy-Initialisierung, effektives Reward-Design, optimierte Suche und datengetriebenes Lernen setzt, eröffnet o1 neue Möglichkeiten in der KI-Entwicklung. Um diese Prinzipien anzuwenden, sind kontinuierliche Forschung und Anpassung erforderlich.
1. Policy Initialization (Politikinitialisierung)
- Ziel: Ermöglicht es Modellen, menschliches Denken nachzuahmen und große Aktionsräume effektiv zu erkunden.
- Prozess:
- Vortraining: Grundlegendes Sprachverständnis wird durch selbstüberwachtes Lernen aus großen Textkorpora entwickelt.
- Instruction Fine-Tuning: Das Modell wird auf spezifische Aufgaben abgestimmt, einschließlich Fähigkeiten wie Aufgabenzerlegung, Fehlerkorrektur und Selbstbewertung.
2. Reward Design (Belohnungsgestaltung)
- Ziel: Liefert Rückmeldungen (Belohnungssignale), die den Lernprozess steuern.
- Techniken:
- Outcome Rewards (Ergebnisbasierte Belohnungen): Bewertet die Korrektheit der Endlösung.
- Process Rewards (Prozessbasierte Belohnungen): Gibt Feedback für Zwischenschritte, um eine höhere Lösungsqualität zu gewährleisten.
- Herausforderungen:
- Gestaltung feinkörniger Belohnungssignale.
- Sicherstellung der Generalisierbarkeit auf unterschiedliche Aufgabenbereiche.
3. Search (Suche)
- Ziel: Verbessert die Lösungsqualität während des Trainings und der Inferenz, indem mehrere Kandidatenlösungen erzeugt und bewertet werden.
- Methoden:
- Tree Search (Baumsuche): Hierarchische Erkundung von Lösungen, z. B. mit Monte Carlo Tree Search (MCTS).
- Sequential Revisions (Sequentielle Überarbeitungen): Iterative Verfeinerung von Lösungen basierend auf Feedback.
- Leitlinien:
- Interne Leitlinien: Modellunsicherheit und Selbstbewertung.
- Externe Leitlinien: Belohnungen und heuristische Regeln.
4. Learning (Lernen)
- Ziel: Nutzt die durch die Suche generierten Daten, um die Politik iterativ zu verbessern.
- Ansätze:
- Policy Gradient-Methoden wie Proximal Policy Optimization (PPO).
- Behavior Cloning (Verhaltensnachahmung) für einfache und effiziente Anpassung.
Zentrale Erkenntnisse und Herausforderungen
- Der Fahrplan orientiert sich an Richard Suttons „Bitter Lesson“, die die Bedeutung von skalierbaren, allgemeinen Methoden wie Suche und Lernen betont.
- Herausforderungen umfassen:
- Balance zwischen Exploration und Performance.
- Umgang mit Verteilungsverschiebungen, wenn sich das Belohnungsmodell oder die Politik ändert.
Fazit
Die Arbeit bietet Forschern einen umfassenden Fahrplan zur Entwicklung leistungsstarker reasoning-Modelle. Dabei werden kombinierte Ansätze aus rechnerischer Skalierung, fortgeschrittenen RL-Techniken und strukturierten Suchstrategien hervorgehoben.
Für weitere Details: Scaling of Search and Learning: A Roadmap to Reproduce o1.









