NVIDIA hat soeben einen gewaltigen Schritt nach vorn für die Entwicklung mehrsprachiger Sprach-KI gemacht und damit die Spielregeln für den europäischen Markt neu definiert. Mit der Veröffentlichung von Granary, dem größten Open-Source-Sprachdatensatz für europäische Sprachen, sowie zwei hochmodernen Modellen, Canary-1b-v2 und Parakeet-tdt-0.6b-v3, wird ein neuer Standard für zugängliche und qualitativ hochwertige Ressourcen gesetzt. Diese Entwicklung ist besonders für Entwickler, Unternehmen und Forscher von Bedeutung, die an automatischer Spracherkennung (ASR) und Sprachübersetzung (AST) arbeiten.
Die Veröffentlichung zielt direkt auf eine der größten Herausforderungen in der KI-Entwicklung ab: die mangelnde Verfügbarkeit von Daten für weniger verbreitete Sprachen. NVIDIA stößt damit eine Tür auf, die es ermöglicht, inklusive und leistungsstarke KI-Anwendungen für die sprachliche Vielfalt Europas zu schaffen. Du erfährst hier, was hinter diesen Namen steckt, welche technologischen Durchbrüche sie mit sich bringen und wie sie die Entwicklung von mehrsprachigen Chatbots, Voice Agents und Echtzeit-Übersetzungsdiensten beschleunigen werden.
Das musst Du wissen – NVIDIAs Sprach-KI-Offensive im Überblick
- Größter Open-Source-Datensatz: Granary liefert rund eine Million Audiostunden für 25 europäische Sprachen und demokratisiert damit die KI-Entwicklung, insbesondere für bisher unterrepräsentierte Sprachen wie Maltesisch oder Kroatisch.
- Zwei State-of-the-Art-Modelle: Canary-1b-v2 ist ein Alleskönner für hochpräzise Transkription und Übersetzung, während Parakeet-tdt-0.6b-v3 auf blitzschnelle Echtzeit-Transkription in allen unterstützten Sprachen spezialisiert ist.
- Frei zugänglich & extrem leistungsstark: Alle neuen Tools sind unter der sehr freizügigen CC BY 4.0 Lizenz verfügbar und bieten eine Performance, die teilweise Modelle übertrifft, die dreimal so groß sind, was sie unglaublich effizient macht.
NVIDIA Speech AI 2025: Was Du über Granary, Canary & Parakeet wirklich wissen musst – KURZ!
| Spezifikation | 🗄️ Granary (Datensatz) | 🚀 Canary-1b-v2 (Modell) | 🦜 Parakeet-tdt-0.6b-v3 (Modell) | Kurzerklärung |
| Primärfunktion | Daten-Fundament für Training | Multitask: Transkription & Übersetzung | Spezialist: Echtzeit-Transkription | Definiert den Hauptzweck der jeweiligen Komponente. |
| Typ | Open-Source Audio-Datensatz | Encoder-Decoder-Modell | Transducer-Modell | Klassifiziert die technische Natur des Produkts. |
| Gesamtumfang | ~1 Million Audio-Stunden | ~1 Milliarde Parameter | ~600 Millionen Parameter | Gibt die Größe des Datensatzes bzw. die Komplexität der Modelle an. |
| Sprachenabdeckung | 25 europäische Sprachen | 25 europäische Sprachen | 25 europäische Sprachen | Zeigt die enorme sprachliche Vielfalt, die unterstützt wird. |
| Unterstützte Aufgaben | Spracherkennung (ASR)<br>Sprachübersetzung (AST) | ✅ ASR (25 Sprachen)<br>✅ AST (Engl. ↔ 24 Sprachen) | ✅ ASR (25 Sprachen) | Listet die Kernfähigkeiten der KI-Modelle auf. |
| Architektur | N/A (Daten-Pipeline) | FastConformer Encoder<br>Transformer Decoder | FastConformer Encoder<br>TDT Decoder | Beschreibt den technischen Aufbau der Modelle. |
| Besonderheit | Halbierte Datenmenge für gleiche Genauigkeit | Zeitstempel für übersetzte Texte | Automatische Spracherkennung | Hebt das herausragendste Alleinstellungsmerkmal hervor. |
| Lange Audio-Dateien | N/A | Effizient durch dynamisches „Chunking“ | Bis 24 Min. (Full Attention)<br>Bis 3 Std. (Local Attention) | Zeigt die Fähigkeit, lange Aufnahmen wie Meetings oder Podcasts zu verarbeiten. |
| Input | Unlabeled Public Audio | 16kHz Audio (.wav, .flac) | 16kHz Audio (.wav, .flac) | Definiert das Format der zu verarbeitenden Daten. |
| Output-Features | Pseudo-gelabelte Trainingsdaten | Text mit Satzzeichen, Großschreibung & Zeitstempeln | Text mit Satzzeichen, Großschreibung & Zeitstempeln | Beschreibt die Qualität und den Detailgrad der Ergebnisse. |
| Lizenz | Mix aus CC-BY-3.0 & CC-BY-4.0 | CC BY 4.0 (kommerziell nutzbar) | CC BY 4.0 (kommerziell nutzbar) | Gibt die Nutzungsrechte an, die für Entwickler entscheidend sind. |
| Toolkit-Integration | NeMo Speech Data Processor | NVIDIA NeMo | NVIDIA NeMo | Zeigt die Einbindung in NVIDIAs Entwickler-Ökosystem. |

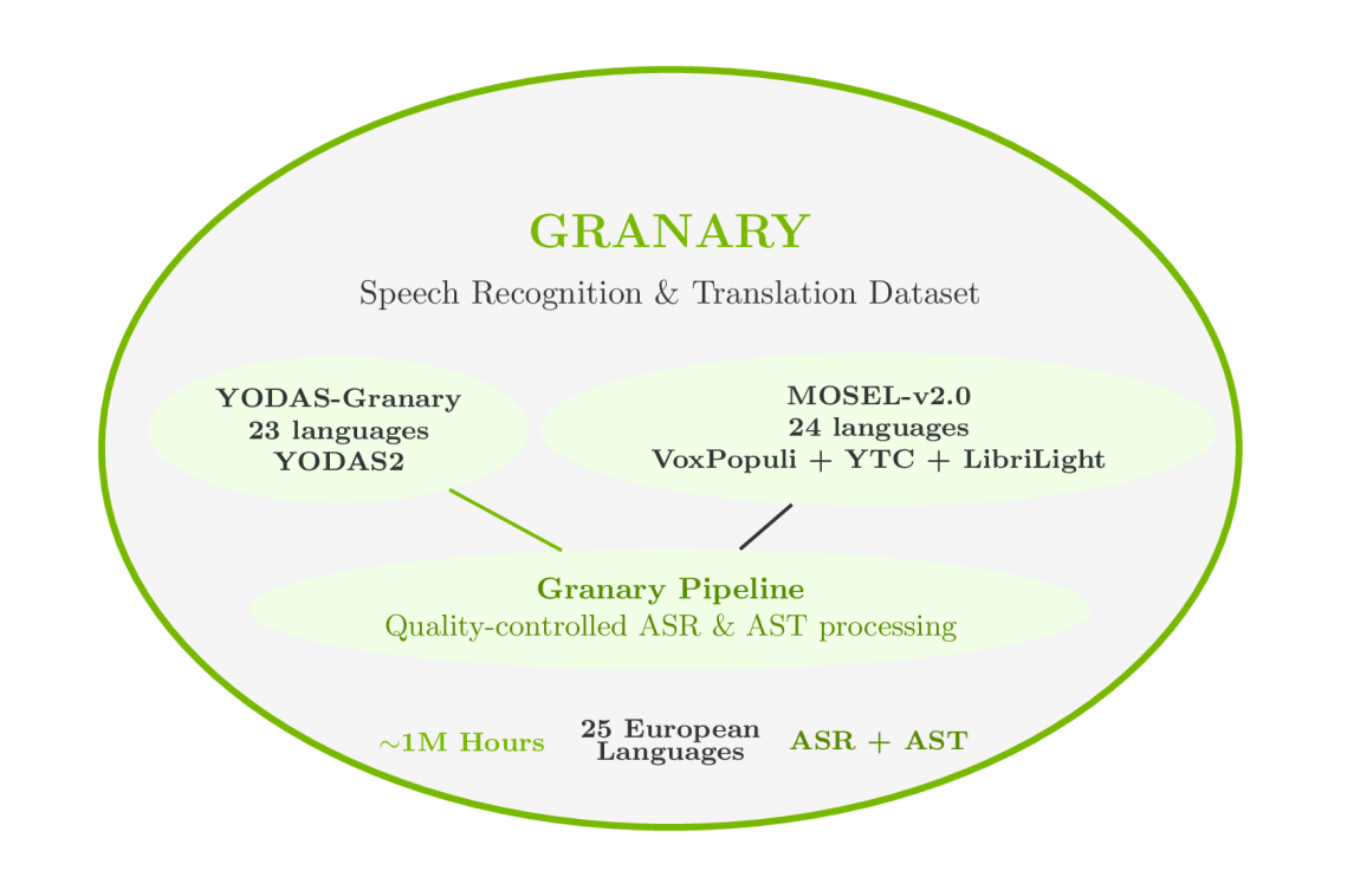
Granary: Das Fundament für Europas mehrsprachige Sprach-KI
Das Herzstück dieser Revolution ist ohne Zweifel der Granary-Datensatz. Er wurde in Zusammenarbeit mit der Carnegie Mellon University und der Fondazione Bruno Kessler entwickelt und ist weit mehr als nur eine Ansammlung von Audiodateien. Mit einem riesigen Umfang von etwa einer Million Stunden Audio – aufgeteilt in 650.000 Stunden für Spracherkennung und 350.000 Stunden für Sprachübersetzung – bildet er die bisher größte frei zugängliche Grundlage für das Training von Sprachmodellen im europäischen Raum.
Der Datensatz deckt 25 Sprachen ab, darunter fast alle offiziellen EU-Sprachen sowie Russisch und Ukrainisch. Der besondere Fokus liegt dabei auf Sprachen, für die es bisher nur sehr wenige annotierte, also beschriftete und für KI-Training aufbereitete Daten gab. Sprachen wie Estnisch, Kroatisch oder Maltesisch rücken damit aus dem Schatten der großen Weltsprachen und werden für die KI-Entwicklung erstklassig erschlossen.
Das wirklich Geniale an Granary ist die innovative Pseudo-Labeling-Pipeline. Anstatt auf extrem zeit- und kostenintensive manuelle Beschriftung von Audiodaten zu setzen, nutzt NVIDIA hier einen intelligenten, automatisierten Prozess. Unbeschriftete, öffentlich verfügbare Audiodaten werden durch den „Nvidia NeMo’s Speech Data Processor“ geschickt. Dieses Werkzeug fügt den Daten automatisch Struktur hinzu, verbessert die Qualität und erstellt hochwertige „Pseudo-Labels“. Dieser Ansatz macht das Training nicht nur günstiger, sondern auch erheblich schneller. Forschungen zeigen, dass Entwickler mit Granary nur halb so viele Daten benötigen, um eine vergleichbare Genauigkeit wie mit anderen Datensätzen zu erreichen – ein unschätzbarer Vorteil für schnelles Prototyping und Projekte mit begrenzten Ressourcen.

Canary-1b-v2: Der Alleskönner für Transkription und Übersetzung
Aufbauend auf dem Granary-Datensatz präsentiert NVIDIA das Modell Canary-1b-v2. Dieses Encoder-Decoder-Modell mit rund einer Milliarde Parametern ist ein wahres Multitalent. Es ist darauf ausgelegt, sowohl Sprache in Text umzuwandeln (ASR) als auch direkt zwischen Englisch und 24 anderen europäischen Sprachen zu übersetzen (AST).
Canary-1b-v2 ist ein Musterbeispiel für Effizienz. Es liefert eine Genauigkeit, die mit Modellen mithalten kann, die dreimal so groß sind, benötigt aber für die Verarbeitung – die sogenannte Inferenz – bis zu zehnmal weniger Zeit. Das macht es ideal für den Einsatz in skalierbaren Produktionsumgebungen, wo Geschwindigkeit und Ressourcenschonung entscheidend sind.
Für dich als Anwender oder Entwickler bietet das Modell eine Fülle an praktischen Funktionen, die direkt einsatzbereit sind:
- Automatische Zeichensetzung und Großschreibung: Der transkribierte Text ist sauber formatiert und sofort lesbar.
- Präzise Zeitstempel: Das Modell liefert exakte Zeitstempel auf Wort- und Satzebene, was beispielsweise für die Erstellung von Untertiteln oder die Analyse von Gesprächen unerlässlich ist.
- Zeitstempel für Übersetzungen: Eine besondere Stärke ist, dass Canary-1b-v2 sogar für übersetzte Textsegmente Zeitstempel generieren kann, was eine präzise Synchronisation von Audio und übersetztem Text ermöglicht.
Die technische Architektur basiert auf einem FastConformer Encoder und einem Transformer Decoder, die für ihre hohe Genauigkeit und Geschwindigkeit bekannt sind. Zudem ist das Modell sehr robust gegenüber Störgeräuschen im Audio und neigt kaum zu Halluzinationen, also der Erfindung von nicht vorhandenen Inhalten.

Parakeet-tdt-0.6b-v3: Echtzeit-Transkription für alle 25 Sprachen
Wo Canary der flexible Allrounder ist, glänzt Parakeet-tdt-0.6b-v3 als hochspezialisierter Sprinter. Dieses 600-Millionen-Parameter-Modell wurde speziell für die schnelle und massenhafte Transkription von Audioinhalten entwickelt und erweitert die bisher primär auf Englisch fokussierte Parakeet-Modellfamilie auf den gesamten europäischen Sprachraum.
Das herausragendste Merkmal von Parakeet ist die automatische Spracherkennung. Du musst dem Modell nicht mitteilen, in welcher Sprache das Audio vorliegt – es erkennt dies selbstständig und liefert die passende Transkription. Das vereinfacht die Verarbeitung von gemischtsprachigen Inhalten enorm.
Das Modell ist auf geringe Latenz und hohen Durchsatz optimiert, was es zur perfekten Wahl für Echtzeitanwendungen macht. Es kann bis zu 24 Minuten lange Audiosegmente in einem einzigen Durchgang verarbeiten. Gleichzeitig ist es extrem robust und zuverlässig, selbst bei anspruchsvollen Inhalten wie der Transkription von Zahlen, Liedtexten oder bei schlechten Audiobedingungen. Natürlich liefert auch Parakeet präzise Wort-Zeitstempel sowie eine automatische Zeichensetzung und Großschreibung.
Um dir die Auswahl des richtigen Werkzeugs für dein Projekt zu erleichtern, hier ein direkter Vergleich der beiden neuen State-of-the-Art-Modelle von NVIDIA:
| Merkmal | 🚀 Canary-1b-v2 (Der Alleskönner) | 🦜 Parakeet-tdt-0.6b-v3 (Der Spezialist) |
| Primäraufgabe | Multitask: Transkription & Übersetzung | Spezialist: Echtzeit-Transkription |
| Unterstützte Aufgaben | ✅ Automatische Spracherkennung (ASR)<br>✅ Sprachübersetzung (AST) | ✅ Automatische Spracherkennung (ASR) |
| Sprachenabdeckung | 25 europäische Sprachen | 25 europäische Sprachen |
| Besonderes Feature | Generiert Zeitstempel für übersetzte Textsegmente | Automatische Spracherkennung (keine Sprachangabe nötig) |
| Architektur-Typ | Encoder-Decoder (FastConformer + Transformer) | Transducer (FastConformer + TDT) |
| Modellgröße | ~ 1 Milliarde Parameter | ~ 600 Millionen Parameter |
| Idealer Anwendungsfall | Mehrsprachige Assistenten, Untertitelung inkl. Live-Übersetzung, Analyse von internationalem Kundenfeedback. | Massenhafte Transkription von Audioarchiven, Live-Untertitelung von Events, Telefonie-Analyse in Echtzeit. |
Diese Gegenüberstellung macht deutlich, dass NVIDIA zwei sich perfekt ergänzende Werkzeuge anbietet: Canary als flexible Lösung für komplexe, mehrsprachige Aufgaben und Parakeet als hocheffizienten Spezialisten für schnelle und skalierbare Transkription.

Was dieser Release für Entwickler und die Zukunft der Sprach-AI bedeutet
Die Veröffentlichung von Granary, Canary-1b-v2 und Parakeet-tdt-0.6b-v3 durch NVIDIA ist mehr als nur ein technisches Update. Es ist ein Akt der Demokratisierung von Sprach-KI in Europa. Indem NVIDIA diese leistungsstarken Werkzeuge als Open Source unter einer freizügigen Lizenz zur Verfügung stellt, ermöglicht das Unternehmen Entwicklern, Forschern und Unternehmen jeder Größe, fortschrittliche und inklusive Sprachanwendungen zu entwickeln.
Bisher war die Entwicklung solcher Systeme oft durch den teuren und schwierigen Zugang zu hochwertigen Trainingsdaten limitiert, besonders für kleinere Sprachräume. Diese Hürde wird nun deutlich gesenkt. Die Konsequenzen sind weitreichend und werden die digitale Landschaft in Europa nachhaltig prägen:
- Entwicklung mehrsprachiger Chatbots: Unternehmen können Kundenservice-Bots entwickeln, die eine Vielzahl europäischer Sprachen fließend verstehen und beantworten.
- Intelligente Voice Agents: Sprachassistenten und Steuerungssysteme werden zugänglicher und können besser auf die sprachliche Vielfalt ihrer Nutzer eingehen.
- Echtzeit-Übersetzungsdienste: Die Vision von nahezu verzögerungsfreien Übersetzungen bei Konferenzen, in Medien oder im persönlichen Gespräch rückt in greifbare Nähe.
Dieser Schritt fördert nicht nur die technologische Innovation, sondern leistet auch einen wichtigen Beitrag zur Bewahrung der sprachlichen Vielfalt Europas im digitalen Zeitalter.
Für Entwickler und Power-User: Ein tieferer Einblick in die Technik
Die Ankündigung von NVIDIA ist nicht nur auf strategischer Ebene bedeutsam, sondern überzeugt auch durch beeindruckende technische Details. Wenn du tiefer in die Materie eintauchen und verstehen möchtest, was diese Modelle so leistungsstark macht und wie du sie konkret nutzen kannst, sind die folgenden Punkte für dich entscheidend.
Die Architektur hinter der Leistung: Was steckt in Canary und Parakeet?
Die außergewöhnliche Performance der neuen Modelle ist kein Zufall, sondern das Ergebnis einer durchdachten und modernen Architektur.
Bei Canary-1b-v2 setzt NVIDIA auf eine bewährte Encoder-Decoder-Struktur. Der Encoder, ein sogenannter FastConformer, ist darauf spezialisiert, die wesentlichen Merkmale aus dem rohen Audiosignal zu extrahieren. Stell es dir so vor: Er hört der Sprache zu und wandelt sie in eine reichhaltige, computerverständliche Zwischensprache um. Der Decoder, ein klassischer Transformer, nimmt diese Zwischensprache und übersetzt sie in den finalen Text – sei es eine Transkription in der Originalsprache oder eine Übersetzung ins Englische. Diese Kombination ist bekannt für ihre hohe Genauigkeit und Effizienz, besonders bei komplexen sprachlichen Aufgaben.
Parakeet-tdt-0.6b-v3 verfolgt einen etwas anderen Ansatz, der auf maximale Geschwindigkeit für die Transkription ausgelegt ist. Es nutzt ebenfalls eine FastConformer-Architektur, kombiniert diese aber mit einem speziellen TDT-Decoder (Transducer/Duration-based Transcriber). Diese Technologie ist besonders gut für Streaming-Anwendungen und die Verarbeitung langer Audio-Dateien geeignet, da sie den Text quasi parallel zum eingehenden Audio generiert, was die Latenz drastisch reduziert. Es ist die perfekte Wahl, wenn es auf sofortige Ergebnisse ankommt.
So startest Du: Erste Schritte mit den neuen NVIDIA-Modellen
NVIDIA hat großen Wert darauf gelegt, den Einstieg so einfach wie möglich zu gestalten. Der zentrale Anlaufpunkt für die Nutzung der Modelle ist das NVIDIA NeMo Toolkit, ein Open-Source-Framework für die Entwicklung von KI-Anwendungen im Sprachbereich.
Um loszulegen, musst du lediglich das NeMo-Toolkit installieren. Anschließend kannst du die vortrainierten Modelle wie Canary oder Parakeet mit nur einer einzigen Codezeile laden. Die eigentliche Transkription oder Übersetzung ist dann ebenso unkompliziert: Du übergibst dem Modell einfach deine Audiodatei und definierst, welche Aufgabe es ausführen soll (z. B. Transkription von Deutsch nach Deutsch oder Übersetzung von Deutsch nach Englisch).
Das Beste daran ist, dass du dich nicht um die komplexe Vorverarbeitung der Audiodaten kümmern musst. Das Toolkit übernimmt das für dich und stellt sicher, dass die Modelle optimal arbeiten. Diese einfache Handhabung senkt die Einstiegshürde erheblich und erlaubt es auch Entwicklern ohne tiefes KI-Fachwissen, modernste Sprachtechnologie in ihre Anwendungen zu integrieren.
Getestet auf Herz und Nieren: Wie robust und präzise sind die Modelle wirklich?
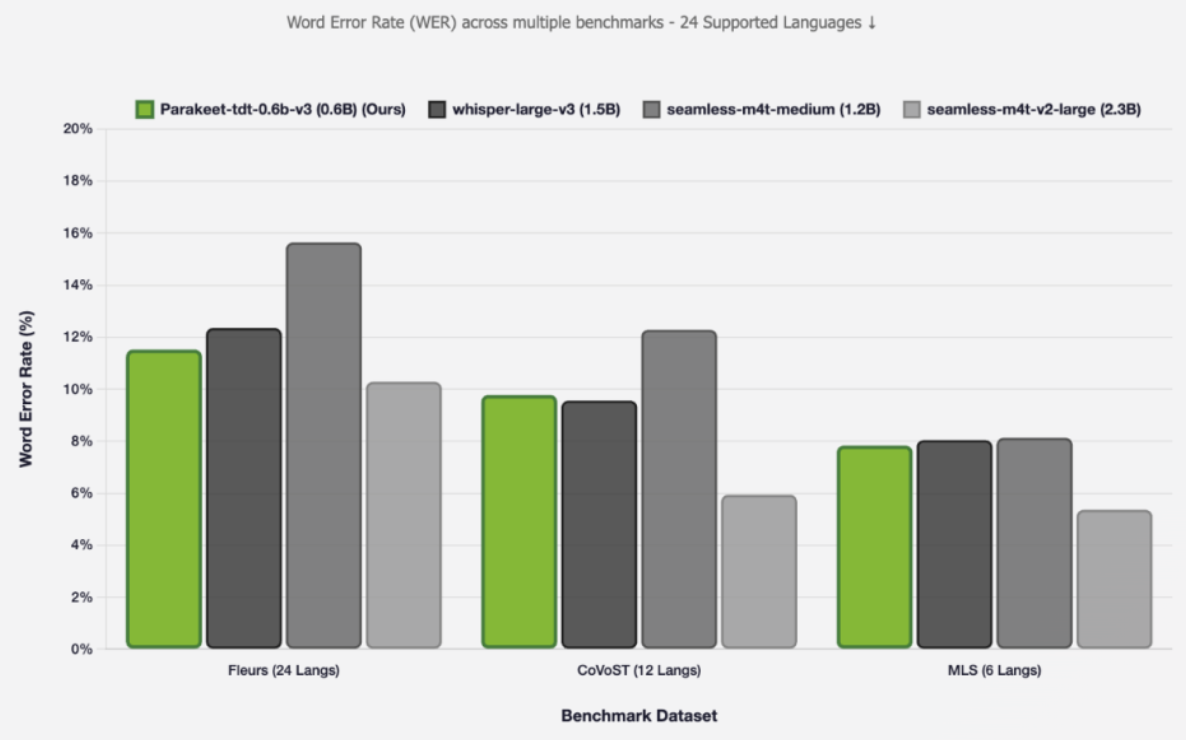
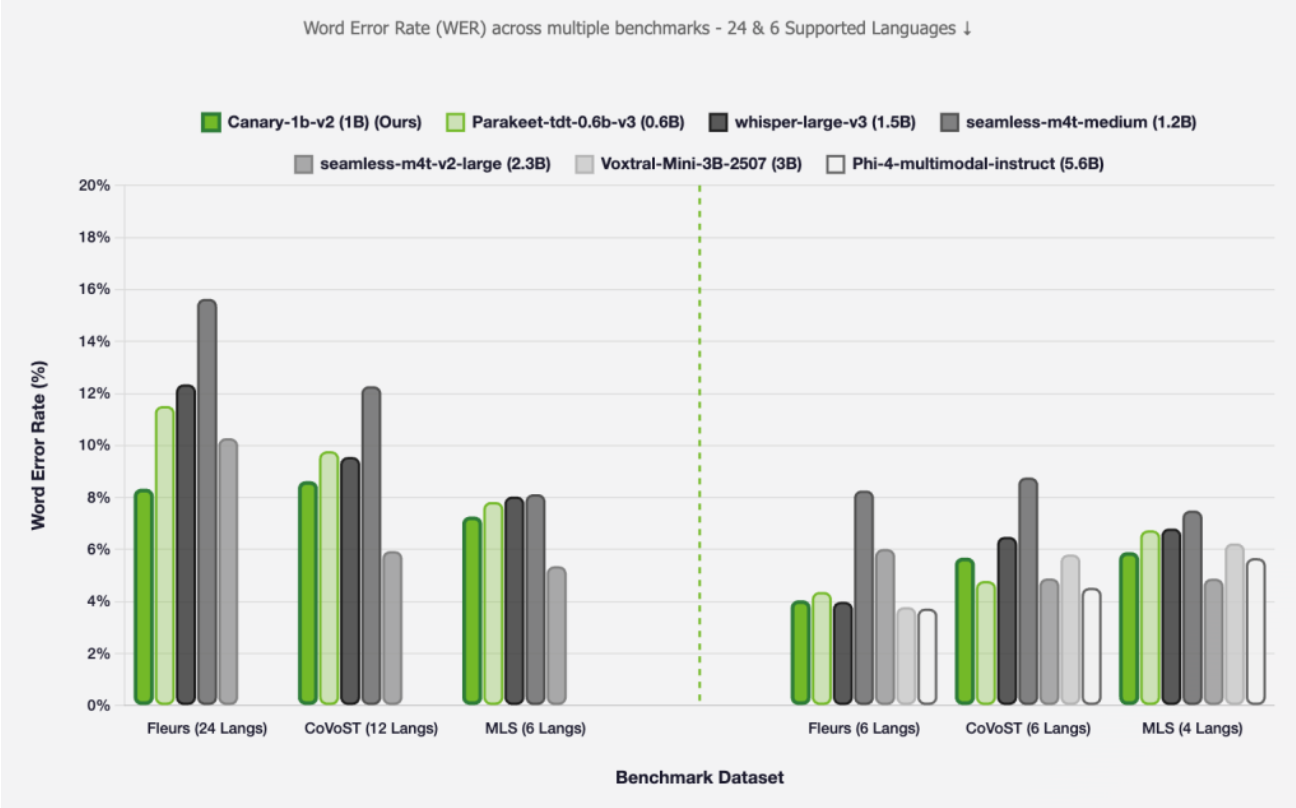
Die Modelle wurden intensiv auf ihre Leistung und Zuverlässigkeit geprüft, und die Ergebnisse sprechen für sich. In standardisierten wissenschaftlichen Benchmarks, in denen die Fehlerraten (Word Error Rate, WER) und die Übersetzungsqualität (COMET-Scores) gemessen werden, schneiden sowohl Canary als auch Parakeet hervorragend ab und setzen sich oft an die Spitze der öffentlich zugänglichen Ranglisten.
Besonders hervorzuheben ist die Robustheit gegenüber Störgeräuschen. Die Modelle wurden gezielt darauf trainiert, auch unter nicht idealen Bedingungen zuverlässig zu arbeiten. Selbst wenn im Hintergrund Musik läuft oder andere Umgebungsgeräusche die Aufnahme stören, bleibt die Transkriptionsqualität bemerkenswert hoch.
Ein weiteres praktisches Highlight ist die Fähigkeit zur Verarbeitung von langen Audioformaten. Parakeet kann beispielsweise problemlos Aufnahmen von Meetings, Vorlesungen oder Podcasts transkribieren, die bis zu 24 Minuten lang sind – und das in einem einzigen Durchgang mit voller Aufmerksamkeit auf den Kontext. Für noch längere Aufnahmen schaltet das Modell intelligent in einen Modus mit lokaler Aufmerksamkeit um, der die Verarbeitung von bis zu drei Stunden Audio am Stück ermöglicht. Diese Fähigkeit, kombiniert mit der hohen Genauigkeit und Geschwindigkeit, macht die neuen NVIDIA-Modelle zu extrem vielseitigen und praxistauglichen Werkzeugen für nahezu jeden denkbaren Anwendungsfall im Bereich der Sprachverarbeitung.
Die strategische Dimension: NVIDIAs Schachzug für den europäischen KI-Markt
Diese umfassende Veröffentlichung ist weit mehr als nur eine technologische Weiterentwicklung – sie ist ein gezielter strategischer Schritt von NVIDIA, der die Landschaft der künstlichen Intelligenz in Europa nachhaltig verändern dürfte. Um die volle Tragweite zu verstehen, lohnt sich ein Blick auf die übergeordneten Zusammenhänge.
Zum einen positioniert sich NVIDIA damit klar im Wettbewerb zu anderen großen Tech-Playern wie OpenAI, dessen Whisper-Modell bisher als einer der Goldstandards für Spracherkennung galt. NVIDIAs Ansatz ist jedoch differenzierter und für den europäischen Markt maßgeschneidert. Während viele Modelle primär auf Englisch trainiert werden, liegt der Fokus hier explizit auf der Vielfalt von 25 europäischen Sprachen. In Kombination mit der Open-Source-Lizenz und der nahtlosen Integration in das eigene NeMo-Framework schafft NVIDIA ein extrem attraktives Ökosystem. Entwickler erhalten nicht nur die Modelle, sondern eine komplette, auf NVIDIA-Hardware optimierte Werkzeugkette – ein entscheidender Vorteil, um sie langfristig an die eigene Plattform zu binden.
Zum anderen fungiert diese Initiative als gewaltiger Innovations- und Wirtschaftsmotor. Indem NVIDIA die grundlegenden Bausteine – einen riesigen, hochwertigen Datensatz und State-of-the-Art-Modelle – kostenlos zur Verfügung stellt, senkt das Unternehmen die Eintrittsbarrieren für unzählige Start-ups, Forschungseinrichtungen und etablierte Unternehmen in Europa. Plötzlich wird es für ein kleines dänisches Softwarehaus oder ein polnisches E-Commerce-Unternehmen möglich, KI-gestützte Sprachdienste auf Weltklasse-Niveau zu entwickeln, ohne Millionen in die Datensammlung und das Modelltraining investieren zu müssen. Dies kurbelt nicht nur die Entwicklung neuer Produkte und Dienstleistungen an, sondern stärkt letztlich auch die Nachfrage nach NVIDIAs Kernprodukt: leistungsstarker GPU-Hardware.
Zuletzt ist dieser Schritt auch ein starkes Statement für die digitale Souveränität und kulturelle Vielfalt Europas. In einer Zeit, in der die Abhängigkeit von außereuropäischen Technologiekonzernen intensiv diskutiert wird, bietet NVIDIA Werkzeuge, die es der europäischen Tech-Szene ermöglichen, eigenständige und an lokale Bedürfnisse angepasste Lösungen zu schaffen. Die gezielte Unterstützung von kleineren Sprachen ist dabei nicht nur ein technisches, sondern auch ein kulturelles Bekenntnis. Es stellt sicher, dass die sprachliche Vielfalt, die Europa ausmacht, auch im Zeitalter der künstlichen Intelligenz erhalten bleibt und nicht einer rein englischzentrierten digitalen Welt weichen muss.
Ein neues Kapitel für die europäische Sprach-KI
Zusammenfassend lässt sich sagen, dass NVIDIA mit dieser Veröffentlichung nicht nur neue Werkzeuge, sondern eine komplett neue Grundlage für die Sprach-KI in Europa geschaffen hat. Der Granary-Datensatz schließt eine entscheidende Lücke bei der Verfügbarkeit von Trainingsdaten, insbesondere für bisher vernachlässigte Sprachen. Er ermöglicht es der globalen Entwicklergemeinschaft, schneller und effizienter zu besseren Ergebnissen zu kommen.
Die beiden Modelle, Canary-1b-v2 und Parakeet-tdt-0.6b-v3, demonstrieren eindrucksvoll, was auf dieser Datenbasis möglich ist. Canary besticht als vielseitiges und hocheffizientes Multitask-Modell für Transkription und Übersetzung, während Parakeet neue Maßstäbe für die automatisierte Echtzeit-Transkription setzt. Beide Modelle sind nicht nur leistungsstark, sondern durch ihre offene Lizenz auch für kommerzielle Projekte frei nutzbar.
Für Europa bedeutet dies eine enorme Chance. Die Fähigkeit, KI-Anwendungen zu entwickeln, die die reiche sprachliche Landschaft des Kontinents widerspiegeln, wird die digitale Inklusion fördern und neue wirtschaftliche Möglichkeiten eröffnen. Entwickler haben nun die Mittel an der Hand, um intelligentere, schnellere und zugänglichere Sprachdienste zu bauen, die wirklich jeden verstehen. NVIDIA hat damit einen Meilenstein gesetzt, der die Entwicklung von künstlicher Intelligenz in Europa auf Jahre hinaus prägen und beschleunigen wird. Es ist der Beginn einer Ära, in der Sprachbarrieren durch Technologie nicht nur überwunden, sondern aktiv abgebaut werden.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
- Razzaq, Asif. „NVIDIA AI Just Released the Largest Open-Source Speech AI Dataset and State-of-the-Art Models for European Languages“. Veröffentlicht auf einer ungenannten Plattform, 15. August 2025.
- NVIDIA. „Granary: Speech Recognition and Translation Dataset in 25 European Languages“. Hugging Face Datasets. https://huggingface.co/datasets/nvidia/Granary (abgerufen am 16. August 2025).
- NVIDIA. „Canary 1B v2: Multitask Speech Transcription and Translation Model“. Hugging Face Models. https://huggingface.co/nvidia/canary-1b-v2 (abgerufen am 16. August 2025).
- NVIDIA. „parakeet-tdt-0.6b-v3: Multilingual Speech-to-Text Model“. Hugging Face Models. https://huggingface.co/nvidia/parakeet-tdt-0.6b-v3 (abgerufen am 16. August 2025).
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #NVIDIA #SpeechAI #Granary #Spracherkennung, NVIDIA Speech AI