
OmniHuman-1 ist ein Forschungspaper mit beeindruckender Anwendung: Stell dir vor, du könntest aus einem einzigen Foto und einer Audioaufnahme ein lebensechtes Video erstellen. Genau das ermöglicht OmniHuman-1, die neueste KI-Innovation von ByteDance. Diese Technologie, die auf der Diffusion Transformer-Architektur basiert, setzt neue Maßstäbe in der Erzeugung realistischer Mensch-Video-Animationen. Aber wer steckt eigentlich hinter dieser bahnbrechenden Entwicklung, was genau macht OmniHuman-1 so besonders, und wann und warum solltest du dich damit auseinandersetzen?
Das ByteDance viel drauf hat in Sachen KI-Videogenerierung war bereits mehrfach zu bemerken. Zuletzt Anfang November, machte ByteDance Schlagzeilen mit dem X-Portrait2 – Charakteranimation war auf neuem Level möglich. Mit OmniHuman-1 hat ByteDance die eigene Messlatte DEUTLICH höher gelegt.
OmniHuman-1 wurde von einem Team um Gaojie Lin und Jianwen Jiang bei ByteDance entwickelt und zielt darauf ab, die Erstellung realistischer Mensch-Videos durch die Kombination verschiedener Eingabesignale zu vereinfachen und zu verbessern. Im Gegensatz zu älteren Modellen, die oft aufwendige Filterung und Bereinigung der Trainingsdaten erfordern, nutzt OmniHuman-1 eine innovative „Omni-Conditions Training“-Strategie, um eine breitere Palette von Daten zu integrieren und so natürlichere und lebensechtere Animationen zu erzeugen. Diese Technologie verspricht nicht nur die Qualität von Mensch-Video-Animationen zu steigern, sondern auch die Effizienz des gesamten Prozesses erheblich zu verbessern. Doch wie genau funktioniert diese Technologie, und welche konkreten Vorteile bietet sie im Vergleich zu anderen Modellen?
In diesem Artikel schauen wir uns die Welt von OmniHuman-1 an. Wir werden die zugrunde liegende Technologie, die „Omni-Conditions Training“-Strategie und die vielfältigen Anwendungsmöglichkeiten beleuchten. Außerdem werden wir die Vor- und Nachteile gegenüber anderen KI-Modellen diskutieren und einen Ausblick auf die zukünftigen Entwicklungspotenziale dieser spannenden Technologie geben. Mach dich bereit, die nächste Generation der Mensch-Video-Animation kennenzulernen – mit OmniHuman-1.
Das musst Du wissen – OmniHuman-1: Revolutionäre KI für realistische Mensch-Video-Animation
- OmniHuman-1 ist eine KI von ByteDance, die realistische Mensch-Videos aus einem Foto und Audio erzeugt.
- Die „Omni-Conditions Training“-Strategie ermöglicht die Nutzung vielfältiger Daten für natürlichere Animationen.
- Diffusion Transformer-Architektur verbessert die Qualität und Effizienz der Videoerstellung.
- Vielseitige Anwendungsmöglichkeiten in Entertainment, Bildung und Content-Erstellung.
- Übertrifft andere Modelle in Bezug auf Realismus, Flexibilität und Anpassungsfähigkeit.
Hauptfrage: Wie revolutioniert OmniHuman-1 die Mensch-Video-Animation durch seine innovative Technologie und vielfältigen Anwendungsmöglichkeiten?
Folgefragen (FAQs)
- Wie unterscheidet sich OmniHuman-1 von anderen KI-Modellen in Bezug auf Video-Realismus?
- Welche Hauptanwendungen von OmniHuman-1 gibt es in der Unterhaltungsindustrie?
- Kann OmniHuman-1 zur Erstellung von Lerninhalten verwendet werden?
- Wie verbessert die Diffusion Transformer-Architektur die Videoerzeugung?
- Welche Einschränkungen hat OmniHuman-1 und wie können diese behoben werden?
- Wie funktioniert die „Omni-Conditions Training“-Strategie von OmniHuman-1?
- Welche Rolle spielen Audio- und Videodaten bei der Erstellung realistischer Animationen mit OmniHuman-1?
- Wie unterstützt OmniHuman-1 verschiedene visuelle und Audio-Stile?
- Welche ethischen Bedenken gibt es bei der Nutzung von OmniHuman-1 und wie können diese adressiert werden?
- Welche zukünftigen Entwicklungen sind für OmniHuman-1 geplant?
Antworten auf jede Frage
Wie unterscheidet sich OmniHuman-1 von anderen KI-Modellen in Bezug auf Video-Realismus?
OmniHuman-1 übertrifft andere KI-Modelle in Bezug auf Video-Realismus durch eine Kombination von Faktoren, die es ermöglichen, lebensechtere und natürlichere Animationen zu erzeugen. Die wichtigsten Unterschiede sind:
- Multimodale Eingabeunterstützung: OmniHuman-1 kann verschiedene Arten von Eingaben gleichzeitig verarbeiten, einschließlich Text, Audio und Körperposen. Dies ermöglicht es, eine breitere Palette von Daten zu nutzen und realistischere Videos zu generieren. Ältere Modelle waren oft auf eine einzige Eingabeart beschränkt, was zu weniger überzeugenden Ergebnissen führte.
- Omni-Conditions Training Strategie: Diese innovative Strategie ermöglicht es dem Modell, von umfangreichen, gemischt konditionierten Daten zu profitieren. Im Gegensatz zu früheren Methoden, die oft mit der Skalierung von Daten zu kämpfen hatten, kann OmniHuman-1 eine größere Vielfalt an Informationen nutzen, um realistischere Animationen zu erzeugen.
- Diffusion Transformer Architektur: Die Verwendung einer Diffusion Transformer (DiT) Architektur verbessert sowohl die Qualität der Videoerzeugung als auch die Effizienz des Trainingsprozesses. Die DiT-Architektur ermöglicht eine bessere Modellierung von komplexen Abhängigkeiten in Videodaten, was zu detaillierteren und kohärenteren Animationen führt.
- Realismus in verschiedenen Szenarien: OmniHuman-1 unterstützt verschiedene visuelle und Audio-Stile und erzeugt realistische Videos in jedem Seitenverhältnis und jeder Körperproportion (Porträt, Halb- oder Ganzkörper). Dies wird durch die Fähigkeit des Modells erreicht, Bewegung, Beleuchtung und Texturdetails umfassend zu berücksichtigen.
- Verbesserte Gesten und Lippensynchronisation: OmniHuman-1 verbessert die Generierung von Gesten und die Lippensynchronisation erheblich, was für den Realismus von Mensch-Video-Animationen entscheidend ist. Diese Verbesserungen resultieren aus der Verwendung fortschrittlicherer Algorithmen und einer umfassenderen Trainingsdatengrundlage.
- Flexibilität und Vielseitigkeit: Im Gegensatz zu älteren Modellen, die oft auf bestimmte Körperproportionen oder Eingabegrößen beschränkt sind, unterstützt OmniHuman-1 eine breite Palette von Eingabegrößen und -verhältnissen mit einem einzigen Modell. Diese Flexibilität ermöglicht es, eine größere Vielfalt an Animationen zu erstellen.
- Stil-Anpassungsfähigkeit: OmniHuman-1 kann nicht nur reale Personen animieren, sondern auch Zeichentrickfiguren effektiv animieren und seine Anpassungsfähigkeit an verschiedene Stile demonstrieren. Diese Fähigkeit macht es zu einem vielseitigeren Werkzeug für verschiedene Anwendungen.
Welche Hauptanwendungen von OmniHuman-1 gibt es in der Unterhaltungsindustrie?
OmniHuman-1 hat das Potenzial, die Unterhaltungsindustrie durch eine Vielzahl von Anwendungen erheblich zu beeinflussen:
- Virtuelle Influencer und Schauspieler: OmniHuman-1 kann realistische Videos aus einem einzigen Bild und Audio erzeugen, was die Erstellung virtueller Schauspieler oder Influencer ermöglicht. Dies könnte den Bedarf an echten Schauspielern in bestimmten Rollen reduzieren, insbesondere in Szenarien, in denen die Anwesenheit des Schauspielers nicht entscheidend ist oder wenn der Schauspieler nicht verfügbar ist.
- Anpassbare Leistungen: Durch die Anpassung von Körperproportionen und Bewegungen kann OmniHuman-1 Leistungen auf spezifische Regievorstellungen zuschneiden und so mehr Kontrolle über das Endprodukt bieten.
- Visuelle Effekte (VFX) und Animation: Das Modell kann Cartoons und Anime-Charaktere mit beeindruckendem Realismus animieren und möglicherweise Animationstechniken in Film und Fernsehen revolutionieren. Durch die nahtlose Integration von CGI-Elementen in Live-Action-Aufnahmen kann OmniHuman-1 VFX in Filmen und Fernsehsendungen verbessern und die Erstellung komplexer Szenen erleichtern.
- Musik- und Live-Auftritte: Künstler könnten OmniHuman-1 für virtuelle Auftritte nutzen, was flexiblere und kostengünstigere Konzerterlebnisse ermöglicht. Dies könnte auch ermöglichen, dass verstorbene Künstler mithilfe ihrer Abbilder und Audioaufnahmen wieder „auftreten“. Die Technologie kann realistische Musikvideos aus Standbildern und Audiotracks erstellen, was die Produktionskosten senkt und die kreativen Möglichkeiten erhöht.
- Inhalts-Erstellung und Storytelling: OmniHuman-1 kann historische Figuren, die Reden halten oder Handlungen ausführen, nachbilden und so Bildungsinhalte und Dokumentationen verbessern. Durch die Erzeugung realistischer Videos aus Benutzereingaben könnte OmniHuman-1 in interaktiven Storytelling-Plattformen verwendet werden, die es Benutzern ermöglichen, ihre eigenen Erzählungen mit realistischen Charakteren zu erstellen.
Es ist jedoch wichtig, die ethischen Implikationen zu berücksichtigen. Die Verwendung von Deepfakes ohne Zustimmung kann zu rechtlichen Problemen und öffentlichem Misstrauen führen. Daher sind klare Vorschriften und ethische Richtlinien erforderlich, um eine verantwortungsvolle Nutzung dieser Technologie in der Unterhaltungsindustrie sicherzustellen.
Kann OmniHuman-1 zur Erstellung von Lerninhalten verwendet werden?
Ja, OmniHuman-1 ist ein vielversprechendes Werkzeug zur Erstellung von Lerninhalten. Seine Fähigkeit, realistische menschliche Videos aus einem einzigen Bild und Bewegungssignalen wie Audio oder Video zu generieren, bietet zahlreiche Vorteile für die Bildung:
- Interaktive Lernmaterialien: OmniHuman-1 kann interaktive Videos erstellen, die Schüler effektiver einbeziehen als herkömmliche statische Bilder oder Texte. Beispielsweise kann es historische Figuren oder Charaktere aus der Literatur animieren, wodurch das Lernen immersiver und einprägsamer wird.
- Personalisiertes Lernen: Durch die Verwendung verschiedener Audioeingaben können Pädagogen individuelle Lernvideos erstellen, die auf spezifische Lernbedürfnisse oder Sprachen zugeschnitten sind, wodurch die Zugänglichkeit und Inklusivität verbessert werden.
- Kosteneffiziente Produktion: Die herkömmliche Videoproduktion erfordert erhebliche Ressourcen und Zeit. OmniHuman-1 kann diese Kosten senken, indem es realistische Videos aus minimalen Eingaben generiert, wodurch es möglich wird, Bildungsinhalte in größerem Umfang zu produzieren.
- Barrierefreiheitsfunktionen: Die Fähigkeit, Videos mit verschiedenen Seitenverhältnissen und Körperproportionen zu generieren, ermöglicht Inhalte, die problemlos für verschiedene Plattformen wie mobile Geräte oder Virtual-Reality-Umgebungen angepasst werden können.
- Verbessertes Storytelling: Bildungsinhalte sind oft auf Storytelling angewiesen, um komplexe Konzepte zu vermitteln. OmniHuman-1 kann Charaktere oder Szenarien animieren, wodurch diese Geschichten ansprechender und leichter verständlich werden.
- Virtuelle Vorlesungen: Erstellen Sie realistische virtuelle Vorlesungen, in denen Dozenten Lektionen aus der Ferne erteilen können, indem sie Audioeingaben verwenden, um ihre Avatare zu animieren.
- Animierte Tutorials: Erstellen Sie schrittweise Anleitungen für komplexe Verfahren, z. B. Laborexperimente oder technische Fähigkeiten, mithilfe einer Kombination aus Audio- und Videoeingaben.
- Historische Nachstellungen: Erwecken Sie historische Ereignisse zum Leben, indem Sie historische Figuren basierend auf Audioerzählungen oder Drehbüchern animieren.
- Sprachunterricht: Produzieren Sie interaktive Sprachlektionen, in denen Charaktere Gespräche führen und Lernenden helfen können, Aussprache und Verständnis zu üben.
Es gibt jedoch auch Herausforderungen zu beachten:
- Ethische Nutzung: Der Realismus der Ausgaben von OmniHuman-1 wirft ethische Bedenken auf, insbesondere in Bezug auf Deepfakes. Bildungsinhalte müssen Transparenz darüber gewährleisten, was real und was generiert ist.
- Qualität der Eingaben: Die Qualität der generierten Videos hängt von der Qualität der Referenzbilder und Audioeingaben ab. Die Sicherstellung hochwertiger Eingaben ist für effektive Bildungsinhalte von entscheidender Bedeutung.
- Technische Einschränkungen: Die Fähigkeit des Systems, komplexe Posen oder Bilder von geringer Qualität zu verarbeiten, kann bestimmte Anwendungen einschränken.
Insgesamt kann OmniHuman-1 ein wertvolles Werkzeug zur Erstellung von Lerninhalten sein, indem es das Engagement, die Zugänglichkeit und die Kosteneffizienz verbessert. Es erfordert jedoch eine sorgfältige Berücksichtigung ethischer Implikationen und technischer Einschränkungen.
Wie verbessert die Diffusion Transformer-Architektur die Videoerzeugung?
Die Diffusion Transformer (DiT)-Architektur verbessert die Videoerzeugung auf verschiedene wichtige Weisen:
- Skalierbarkeit und Leistung: DiTs ersetzen die traditionelle U-Net-Architektur durch eine Transformer-Architektur, die für ihre Skalierbarkeit und Flexibilität in verschiedenen Bereichen bekannt ist. Dies ermöglicht eine effizientere Verarbeitung großer Datensätze und eine bessere Handhabung komplexer Videosequenzen. Durch die Skalierung der Modellgröße und der Eingabe-Token erzielen DiTs eine verbesserte Leistung in Bezug auf die visuelle Qualität, gemessen an Metriken wie Frechet Inception Distance (FID).
- Temporale und räumliche Modellierung: In der Videoerzeugung können DiTs temporale Selbstaufmerksamkeits-Schichten einbauen, um temporale Abhängigkeiten zwischen Frames zu erfassen, was die Kohärenz und Qualität der generierten Videos verbessert. Die räumliche Modellierung wird ebenfalls verbessert, da Transformer latente Patches effektiv verarbeiten können, was eine bessere räumliche Kohärenz und Detailgenauigkeit in Videoframes ermöglicht.
- Bewegungssteuerung und -führung: Modelle wie Tora integrieren Trajektorienbedingungen, um eine robuste Bewegungssteuerung zu ermöglichen, die die Erzeugung von Videos mit bestimmten Bewegungen und Trajektorien ermöglicht. Techniken wie die bewegungsfreie Führung in GenTron verbessern die Videoqualität, indem sie die Bewegungsmodellierung während des Trainings intermittierend deaktivieren, was zur Aufrechterhaltung der visuellen Konsistenz über Frames hinweg beiträgt.
- In-Context-Lernen: DiTs können für das In-Context-Lernen angepasst werden, was es ihnen ermöglicht, konsistente Multi-Szenen-Videos ohne signifikanten zusätzlichen Rechenaufwand zu generieren, was für steuerbare Videoerzeugungssysteme entscheidend ist.
- Multimodale Konditionierung: DiTs können multimodale Eingaben wie Text und Bilder verarbeiten, was sie für Text-zu-Video-Generierungsaufgaben geeignet macht. Diese Fähigkeit verbessert die Fähigkeit des Modells, Videos zu generieren, die gut mit Textbeschreibungen übereinstimmen.
Trotz dieser Fortschritte bestehen weiterhin Herausforderungen, wie z. B. die hohen Rechenanforderungen für das Training von DiTs und die Notwendigkeit weiterer Verfeinerungen bei der Handhabung komplexer temporaler Dynamiken und Bewegungsmodellierung. Zukünftige Forschungen können sich auf die Optimierung dieser Aspekte konzentrieren, um DiTs effizienter und effektiver für ein breiteres Spektrum von Videoerzeugungsaufgaben zu machen.
Welche Einschränkungen hat OmniHuman-1 und wie können diese behoben werden?
Obwohl OmniHuman-1 beeindruckende Ergebnisse erzielt, gibt es auch Einschränkungen, die angegangen werden müssen:
- Qualität der Referenzbilder: Das System hat Schwierigkeiten mit Referenzbildern von geringer Qualität, was zu minderwertigen Videoausgaben führen kann. Dies unterstreicht, wie wichtig es ist, hochwertige Bilder für optimale Ergebnisse zu verwenden. Um dieses Problem zu beheben, könnten Algorithmen entwickelt werden, die minderwertige Referenzbilder vor der Verarbeitung verbessern oder korrigieren.
- Herausforderungen bei Posen und Bewegungen: OmniHuman-1 hat manchmal Schwierigkeiten mit bestimmten Posen und Bewegungen, wie z. B. unnatürlichen Gesten oder Gliedmaßenbewegungen. Diese Probleme können die generierten Videos weniger überzeugend machen. Um dieses Problem zu beheben, könnte die Vielfalt und Qualität der Trainingsdaten erhöht werden, um dem System zu helfen, verschiedene Posen und Bewegungen natürlicher zu verarbeiten.
- Ethische und Sicherheitsbedenken: Der Realismus von OmniHuman-1 wirft erhebliche ethische und Sicherheitsbedenken auf, einschließlich des potenziellen Missbrauchs für Betrug, Falschinformationen oder die Erstellung von Inhalten ohne Zustimmung. Um diese Bedenken auszuräumen, sollten Regierungen und Aufsichtsbehörden klare Richtlinien und Gesetze erlassen, um den Missbrauch von Deepfake-Technologien zu verhindern, z. B. die Erstellung von Inhalten ohne Zustimmung oder die Verbreitung von Falschinformationen.
Zusätzlich zu diesen Maßnahmen ist es wichtig, die Öffentlichkeit über die potenziellen Risiken und Vorteile von Deepfake-Technologien aufzuklären und wirksame Instrumente zur Erkennung von Deepfakes zu entwickeln. Durch die Förderung der Zusammenarbeit zwischen KI-Forschern, Ethikern und politischen Entscheidungsträgern können ausgewogene technologische Fortschritte erzielt werden, die sowohl das kreative Potenzial als auch die gesellschaftlichen Risiken berücksichtigen.
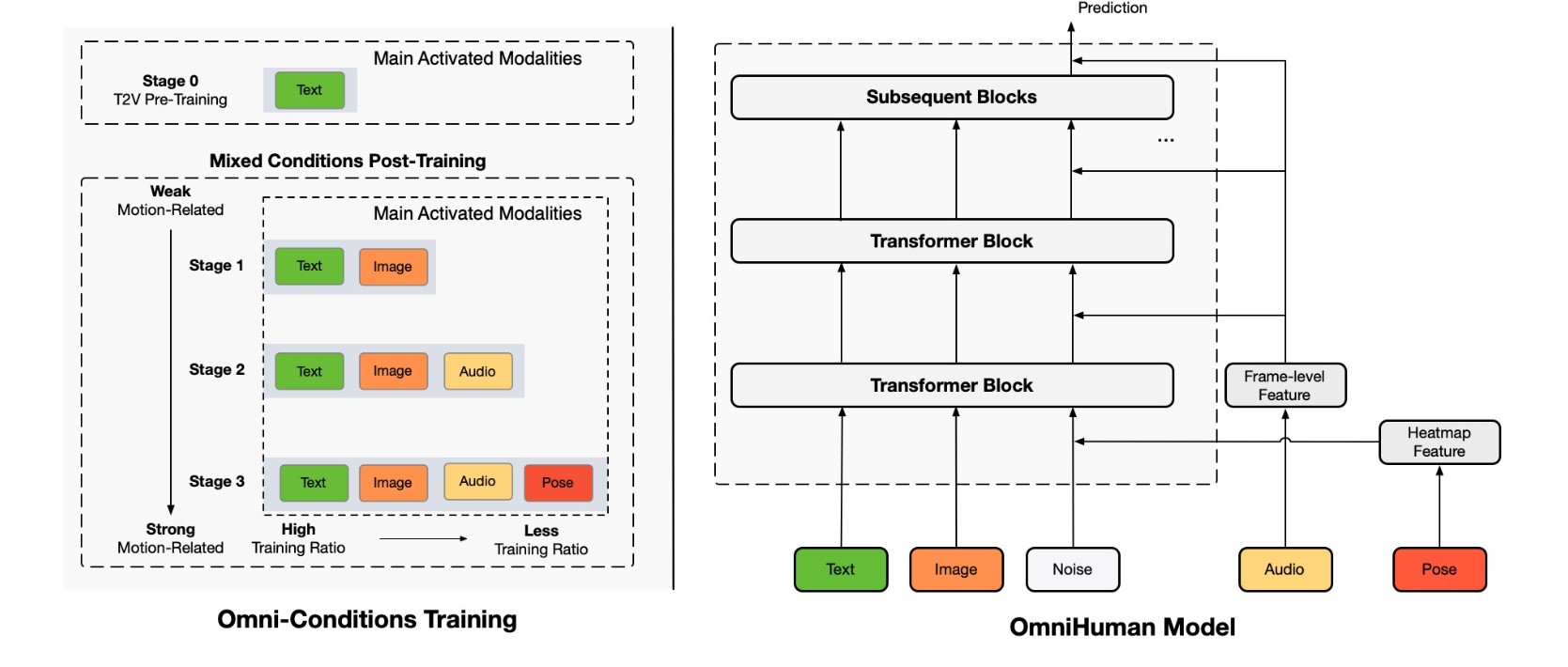
Wie funktioniert die „Omni-Conditions Training“-Strategie von OmniHuman-1?
Die „Omni-Conditions Training“-Strategie von OmniHuman-1 ist ein innovativer Ansatz, um realistische Mensch-Video-Animationen zu erzeugen, indem verschiedene Arten von Eingabedaten (Conditions) während des Trainingsprozesses kombiniert werden. Das Ziel ist es, die Grenzen herkömmlicher Methoden zu überwinden, die oft aufwendige Filterung und Bereinigung der Trainingsdaten erfordern. Hier ist eine detaillierte Erklärung, wie diese Strategie funktioniert:
- Grundprinzip: Die Strategie basiert auf der Idee, dass durch die Integration verschiedener Motion-Conditions wie Text, Audio und Pose während des Trainings die Datenverschwendung reduziert werden kann. Dies bietet zwei Hauptvorteile:
- Daten, die sonst für Einzel-Condition-Modelle (z. B. Audio- oder Pose-konditioniert) verworfen würden, können in Aufgaben mit schwächeren oder allgemeineren Bedingungen (z. B. Textkonditionierung) genutzt werden.
- Verschiedene Konditionierungssignale können sich gegenseitig ergänzen. Beispielsweise kann Audio allein Körperposen nicht präzise steuern, aber stärkere Bedingungen wie Pose-Eingaben können zusätzliche Anleitungen geben.
- Zwei Trainingsprinzipien: Die „Omni-Conditions Training“-Strategie folgt zwei vorgeschlagenen Trainingsprinzipien:
- Stärker konditionierte Aufgaben können schwächer konditionierte Aufgaben und deren entsprechende Daten nutzen, um eine Datenskalierung während des Modelltrainings zu erreichen.
- Je stärker die Bedingung, desto geringer sollte das verwendete Trainingsverhältnis sein.
- Implementierung: Um diese Strategie umzusetzen, wurde ein Mixed-Condition-Human-Video-Generierungsmodell namens OmniHuman entwickelt, das auf der fortschrittlichen Video-Generierungsmodellarchitektur DiT basiert. OmniHuman kann mit drei bewegungsbezogenen Bedingungen (Text, Audio und Pose) von schwach bis stark trainieren.
- Text: Beschreibt das aktuelle Ereignis.
- Referenzbild: Definiert den Bewegungsbereich.
- Audio: Bestimmt den Rhythmus der Co-Speech-Gesten.
- Pose: Gibt die genaue Bewegung an.
- Training in mehreren Phasen: Das Modelltraining wird in mehrere Aufgaben unterteilt, darunter Bild- und Text-zu-Video, Bild- und Text-, Audio-zu-Video- sowie Bild- und Text-, Audio-, Pose-zu-Video. Während des Trainings werden verschiedene Modalitäten für verschiedene Daten aktiviert, sodass eine breitere Palette von Daten am Trainingsprozess teilnehmen und die Generierungsfähigkeiten des Modells verbessern kann.
- Training-Ratios: Während des Trainings trainieren stärkere bewegungsbezogene Bedingungen wie Pose im Allgemeinen besser als schwächere Bedingungen wie Audio, da es weniger Mehrdeutigkeit gibt. Wenn beide Bedingungen vorhanden sind, neigt das Modell dazu, sich auf die stärkere Bedingung für die Bewegungserzeugung zu verlassen, wodurch verhindert wird, dass die schwächere Bedingung effektiv lernt. Daher wird sichergestellt, dass schwächere Bedingungen ein höheres Trainingsverhältnis haben als stärkere Bedingungen.
Welche Rolle spielen Audio- und Videodaten bei der Erstellung realistischer Animationen mit OmniHuman-1?
Audio- und Videodaten spielen eine entscheidende Rolle bei der Erstellung realistischer Animationen mit OmniHuman-1. Sie dienen als primäre Antriebskräfte, die die Bewegungen und Ausdrücke der generierten menschlichen Figuren bestimmen:
- Audiodaten: Audiodaten werden hauptsächlich verwendet, um Gesichtsausdrücke und Lippensynchronisation zu steuern. OmniHuman-1 verwendet das wav2vec-Modell, um akustische Merkmale aus Audiodaten zu extrahieren. Diese Merkmale werden dann verwendet, um die Mundbewegungen und Gesichtsausdrücke der animierten Figur anzupassen, um sicherzustellen, dass sie mit dem gesprochenen oder gesungenen Wort übereinstimmen. Darüber hinaus kann Audio auch die allgemeine Körpersprache und Gesten beeinflussen, wodurch die Animation lebensechter und ansprechender wird.
- Videodaten: Videodaten können verwendet werden, um eine breitere Palette von Bewegungen und Aktionen zu steuern, einschließlich Körperposen, Gesten und Umgebungsinteraktionen. OmniHuman-1 kann Videodaten verwenden, um die Bewegungen einer realen Person nachzuahmen, wodurch die animierte Figur realistischere und natürlichere Bewegungen ausführen kann. Videodaten sind besonders nützlich, um komplexe Aktionen wie Tanzen, Sport treiben oder mit Objekten interagieren zu animieren.
- Kombinierte Nutzung: Die effektivste Methode, realistische Animationen zu erstellen, ist die kombinierte Nutzung von Audio- und Videodaten. Durch die gleichzeitige Verwendung von Audio- und Videodaten kann OmniHuman-1 Animationen erzeugen, die sowohl visuell überzeugend als auch akustisch synchronisiert sind. Dies ist besonders wichtig für Anwendungen wie virtuelle Assistenten, Videospiele und Filme, in denen der Realismus der Animation entscheidend ist.
Wie unterstützt OmniHuman-1 verschiedene visuelle und Audio-Stile?
OmniHuman-1 ist darauf ausgelegt, verschiedene visuelle und Audio-Stile zu unterstützen, indem es die Eingabedaten anpasst und die Generierungsprozesse entsprechend anpasst. Hier sind einige Möglichkeiten, wie OmniHuman-1 dies erreicht:
- Visuelle Stile:
- Referenzbild: OmniHuman-1 kann verschiedene visuelle Stile unterstützen, indem es unterschiedliche Referenzbilder verwendet. Das Modell kann das Aussehen der animierten Figur an das des Referenzbildes anpassen, wodurch es möglich ist, eine Vielzahl von Stilen zu erzeugen, von realistisch bis cartoonartig.
- Eingabegrößen und -verhältnisse: OmniHuman-1 unterstützt verschiedene Eingabegrößen und -verhältnisse, wodurch es möglich ist, Animationen in verschiedenen Formaten zu erstellen, wie z. B. Porträts, Halb- oder Ganzkörperaufnahmen.
- Stilanpassung: OmniHuman-1 kann verschiedene Stile unterstützen, wie z. B. die Anpassung der Beleuchtung, Textur und Farbgebung der generierten Animationen.
- Audio-Stile:
- Audioanalyse: OmniHuman-1 kann Audio-Stile durch Analyse der Audioeingabe unterstützen. Das Modell kann die Tonhöhe, den Rhythmus und die Melodie der Audioeingabe analysieren, um die Gesichtsausdrücke und Bewegungen der animierten Figur entsprechend anzupassen.
- Lippensynchronisation: OmniHuman-1 kann die Lippensynchronisation an verschiedene Audio-Stile anpassen. Das Modell kann die Mundbewegungen der animierten Figur an die Phoneme der Audioeingabe anpassen, um sicherzustellen, dass die Lippensynchronisation korrekt und natürlich ist.
- Bewegungsanpassung: OmniHuman-1 kann verschiedene Bewegungsstile unterstützen, wie z. B. die Anpassung der Körpersprache und Gesten der animierten Figur an den Stil der Audioeingabe.
Durch die Anpassung an verschiedene visuelle und Audio-Stile kann OmniHuman-1 Animationen erzeugen, die sowohl realistisch als auch ausdrucksstark sind.
Welche ethischen Bedenken gibt es bei der Nutzung von OmniHuman-1 und wie können diese adressiert werden?
Die Nutzung von OmniHuman-1, insbesondere im Bereich der Mensch-Video-Animation und Deepfake-Technologie, birgt eine Reihe ethischer Bedenken, die sorgfältig adressiert werden müssen. Hier sind einige der wichtigsten Bedenken und mögliche Lösungsansätze:
- Desinformation und Manipulation:
- Bedenken: OmniHuman-1 kann verwendet werden, um überzeugende gefälschte Videos zu erstellen, die dazu dienen, falsche Informationen zu verbreiten oder Einzelpersonen und Organisationen zu diffamieren. Dies könnte die öffentliche Meinung beeinflussen und das Vertrauen in Medien und Institutionen untergraben.
- Lösungsansätze:
- Technologien zur Deepfake-Erkennung: Entwicklung und Einsatz von Algorithmen und Tools, die Deepfakes zuverlässig erkennen und kennzeichnen können.
- Medienkompetenz: Förderung der Medienkompetenz in der Bevölkerung, um Menschen in die Lage zu versetzen, gefälschte Inhalte zu erkennen und kritisch zu hinterfragen.
- Transparenz: Kennzeichnung von Inhalten, die mit KI-Technologien wie OmniHuman-1 erstellt wurden, um die Herkunft und den Grad der Manipulation offenzulegen.
- Verletzung der Privatsphäre und Identitätsdiebstahl:
- Bedenken: OmniHuman-1 kann verwendet werden, um das Abbild und die Stimme von Personen ohne deren Zustimmung zu nutzen. Dies könnte zu Identitätsdiebstahl, Rufschädigung und anderen Formen der Belästigung führen.
- Lösungsansätze:
- Einwilligungserfordernis: Einführung klarer Richtlinien und Gesetze, die die Verwendung des Abbilds und der Stimme einer Person ohne deren ausdrückliche Einwilligung verbieten.
- Datenschutzbestimmungen: Strikte Anwendung von Datenschutzbestimmungen, um den unbefugten Zugriff auf und die Verwendung von persönlichen Daten zu verhindern.
- Wasserzeichen und digitale Signaturen: Verwendung von Wasserzeichen und digitalen Signaturen, um die Authentizität von Inhalten zu gewährleisten und die Verfolgung von Missbrauch zu erleichtern.
- Diskriminierung und Stereotypisierung:
- Bedenken: OmniHuman-1 könnte verwendet werden, um diskriminierende oder stereotype Darstellungen von Personen oder Gruppen zu erzeugen. Dies könnte Vorurteile verstärken und soziale Ungleichheit fördern.
- Lösungsansätze:
- Voreingenommenheits-Erkennung und -Minderung: Entwicklung von Algorithmen, die Voreingenommenheiten in Trainingsdaten erkennen und minimieren können.
- Vielfalt und Inklusion: Förderung von Vielfalt und Inklusion in den Teams, die KI-Systeme entwickeln und trainieren.
- Ethische Richtlinien: Etablierung ethischer Richtlinien für die Entwicklung und Verwendung von KI-Systemen, die Diskriminierung und Stereotypisierung verhindern.
- Verlust von Arbeitsplätzen:
- Bedenken: Die Automatisierung von Aufgaben durch OmniHuman-1 könnte zu einem Verlust von Arbeitsplätzen in Branchen wie Schauspielerei, Animation und Content-Erstellung führen.
- Lösungsansätze:
- Umschulung und Weiterbildung: Investition in Umschulungs- und Weiterbildungsprogramme, um Arbeitnehmer auf neue Rollen in der sich verändernden Arbeitswelt vorzubereiten.
- Soziale Sicherheitsnetze: Stärkung sozialer Sicherheitsnetze, um Arbeitnehmer zu unterstützen, die aufgrund von Automatisierung ihren Arbeitsplatz verlieren.
- Förderung von Innovation und Unternehmertum: Schaffung eines Umfelds, das Innovation und Unternehmertum fördert, um neue Arbeitsplätze in aufstrebenden Branchen zu schaffen.
Welche zukünftigen Entwicklungen sind für OmniHuman-1 geplant?
Die zukünftigen Entwicklungen für OmniHuman-1 zielen darauf ab, seine Fähigkeiten zu erweitern, seine ethischen Auswirkungen zu minimieren und seine Anwendbarkeit in verschiedenen Bereichen zu verbessern. Hier sind einige der geplanten Entwicklungen:
- Verbesserung der Realitätsnähe und Ausdruckskraft:
- Detailliertere Gesichtsausdrücke und Emotionen: Entwicklung von Algorithmen, die subtilere und nuanciertere Gesichtsausdrücke erzeugen können, um Emotionen authentischer darzustellen.
- Natürlichere Körperbewegungen und Gesten: Verbesserung der Fähigkeit, komplexe und natürliche Körperbewegungen und Gesten zu generieren, um die Animationen lebensechter zu gestalten.
- Realistischere Texturen und Beleuchtung: Verbesserung der Modellierung von Texturen und Beleuchtung, um die generierten Videos visuell ansprechender zu gestalten.
- Erweiterung der Kontrollmöglichkeiten:
- Feingranulare Steuerung von Posen und Bewegungen: Ermöglichung einer präziseren Steuerung der Posen und Bewegungen der animierten Figuren, um spezifische kreative Anforderungen zu erfüllen.
- Interaktive Bearbeitung: Entwicklung von Tools, mit denen Benutzer die generierten Animationen in Echtzeit bearbeiten und anpassen können.
- Integration mit anderen KI-Systemen: Integration mit anderen KI-Systemen wie Sprachmodellen und Bilderkennung, um komplexere und interaktivere Anwendungen zu ermöglichen.
- Ethische und verantwortungsvolle Nutzung:
- Verbesserte Deepfake-Erkennung: Entwicklung von robusten Deepfake-Erkennungstechnologien, um den Missbrauch der Technologie zu verhindern.
- Transparenz und Kennzeichnung: Implementierung von Mechanismen zur transparenten Kennzeichnung von Inhalten, die mit OmniHuman-1 generiert wurden.
- Ethische Richtlinien und Standards: Etablierung ethischer Richtlinien und Standards für die Entwicklung und Verwendung von OmniHuman-1, um Diskriminierung, Manipulation und andere negative Auswirkungen zu verhindern.
- Anwendungsbereiche:
- Bildung und Training: Entwicklung interaktiver Lernmaterialien und Schulungssimulationen, die auf OmniHuman-1 basieren.
- Unterhaltung und Medien: Schaffung neuer Formen der Unterhaltung und des Storytellings, die durch die realistischen Animationen von OmniHuman-1 ermöglicht werden.
- Gesundheitswesen: Entwicklung von virtuellen Assistenten und Therapieanwendungen, die auf OmniHuman-1 basieren.
- Kundenservice und Marketing: Erstellung personalisierter Kundenservice- und Marketinginhalte mit animierten Avataren.
Konkrete Tipps und Anleitungen
Obwohl OmniHuman-1 primär ein Werkzeug für Entwickler und Content-Ersteller mit technischem Hintergrund ist, gibt es einige allgemeine Tipps und Anleitungen, die bei der Verwendung hilfreich sein können:
- Qualitativ hochwertige Eingangsdaten verwenden: OmniHuman-1 erzielt die besten Ergebnisse mit hochwertigen Referenzbildern und klaren Audioaufnahmen. Achte darauf, dass deine Eingangsdaten so sauber und detailliert wie möglich sind.
- Die richtigen Bedingungen wählen: Experimentiere mit verschiedenen Kombinationen von Text, Audio und Pose-Conditions, um den gewünschten Effekt zu erzielen. Berücksichtige, welche Art von Bewegung und Ausdruck du erzeugen möchtest, und wähle die Bedingungen entsprechend.
- Mit den Training-Ratios spielen: Passe die Training-Ratios der verschiedenen Bedingungen an, um die Balance zwischen Realismus und Kontrolle zu optimieren. Beachte, dass stärkere Bedingungen wie Pose in der Regel niedrigere Ratios erfordern als schwächere Bedingungen wie Audio.
- Ethische Überlegungen berücksichtigen: Sei dir der ethischen Implikationen der Verwendung von OmniHuman-1 bewusst, insbesondere in Bezug auf Desinformation, Privatsphäre und Diskriminierung. Verwende die Technologie verantwortungsvoll und transparent.
- Auf dem Laufenden bleiben: OmniHuman-1 ist eine sich schnell entwickelnde Technologie. Verfolge die neuesten Forschungsergebnisse und Entwicklungen, um dein Wissen und deine Fähigkeiten auf dem neuesten Stand zu halten.
Darüber hinaus gibt es einige spezifische Anleitungen, die bei der Verwendung von OmniHuman-1 hilfreich sein können:
- Für realistische Gesichtsausdrücke: Verwende hochwertige Audioaufnahmen mit klaren Sprechmustern und Emotionen. Experimentiere mit verschiedenen Textbeschreibungen, um die gewünschten Gesichtsausdrücke und Emotionen zu erzielen.
- Für natürliche Körperbewegungen: Verwende Videodaten als Referenz für Körperbewegungen und Gesten. Passe die Pose-Conditions an, um die gewünschten Posen und Bewegungen zu erzielen.
- Für spezifische Stile: Passe das Referenzbild an, um den gewünschten visuellen Stil zu erzielen. Experimentiere mit verschiedenen Beleuchtungs- und Textureinstellungen, um den gewünschten Effekt zu erzielen.
Indem du diese Tipps und Anleitungen befolgst, kannst du das Potenzial von OmniHuman-1 voll ausschöpfen und beeindruckende und realistische Mensch-Video-Animationen erstellen.
Regelmäßige Aktualisierung
Dieser Artikel wird regelmäßig aktualisiert, um die neuesten Entwicklungen und Erkenntnisse zu OmniHuman-1 zu berücksichtigen. Schau regelmäßig vorbei, um auf dem Laufenden zu bleiben.
Jianwen Jiang: Ein Pionier der KI-gestützten Mensch-Video-Animation
Hinter all dem Staunen über diese bahnbrechenden Filme und Animationen stecken natürlich echte Menschen, die diese Technologie möglich gemacht haben. Einer von ihnen ist Jianwen Jiang, ein renommierter Forscher, der seit Jahren als Pionier in diesem Forschungszweig tätig ist – hat in diesem Project den ProjectLead übernommen.
Jianwen Jiang, ein renommierter Forscher bei ByteDance, hat sich in den letzten Jahren als einer der führenden Köpfe im Bereich der KI-gestützten Mensch-Video-Animation etabliert. Seine bisherigen Arbeiten, insbesondere die Veröffentlichungen zu „Loopy“ und „CyberHost„, zeigen ein tiefes Verständnis für die Herausforderungen und Potenziale der Audio-gesteuerten Avatar-Erzeugung. In „Loopy“ beschäftigte er sich mit der Modellierung langfristiger Bewegungsabhängigkeiten in Audio-gesteuerten Porträt-Avataren, während er in „CyberHost“ einen auf Diffusion basierenden Ansatz zur Erzeugung von Avataren mit Codebook-Attention untersuchte. Diese Vorarbeiten legten den Grundstein für OmniHuman-1, indem sie Jiangs Expertise in den Bereichen Bewegungsmodellierung, Audio-Visual-Synchronisation und realistische Avatar-Generierung festigten. Die Entwicklung von OmniHuman-1 kann somit als logische Konsequenz und Krönung seiner bisherigen Forschungstätigkeit betrachtet werden, bei der er seine umfangreichen Kenntnisse und Erfahrungen in ein bahnbrechendes System zur Erzeugung realistischer Mensch-Video-Animationen einbrachte. Seine Arbeit an OmniHuman-1 ist ein Beweis für seine Fähigkeit, innovative Lösungen für komplexe Probleme zu finden und die Grenzen der KI-gestützten Videoerzeugung zu verschieben.
Fazit: OmniHuman-1 – Die Zukunft der realistischen Mensch-Video-Animation ist hier
OmniHuman-1 stellt einen bedeutenden Fortschritt in der Welt der KI-gestützten Videoerzeugung dar. Durch die Kombination der Diffusion Transformer-Architektur mit der innovativen „Omni-Conditions Training“-Strategie ermöglicht dieses Modell die Erzeugung realistischer und lebensechter Mensch-Video-Animationen, die bisher unvorstellbar waren. Die Fähigkeit, verschiedene Eingabesignale wie Text, Audio und Pose zu verarbeiten, eröffnet neue Möglichkeiten für Kreativität und Innovation in verschiedenen Branchen.
Die vielfältigen Anwendungsmöglichkeiten von OmniHuman-1 in den Bereichen Unterhaltung, Bildung, Marketing und Gesundheitswesen sind beeindruckend. Von der Erstellung virtueller Influencer und Schauspieler über die Entwicklung interaktiver Lernmaterialien bis hin zur Bereitstellung personalisierter Kundenservice- und Marketinginhalte bietet OmniHuman-1 ein breites Spektrum an Anwendungsmöglichkeiten. Die ethischen Bedenken, die mit dieser Technologie einhergehen, dürfen jedoch nicht außer Acht gelassen werden. Es ist wichtig, die Technologie verantwortungsvoll und transparent einzusetzen und Maßnahmen zur Verhinderung von Missbrauch zu ergreifen.
Die zukünftigen Entwicklungen von OmniHuman-1 versprechen noch mehr Realismus, Ausdruckskraft und Kontrolle. Durch die Verbesserung der Gesichtsausdrücke, Körperbewegungen und Texturen sowie die Erweiterung der Steuerungsmöglichkeiten und die Integration mit anderen KI-Systemen wird OmniHuman-1 seine Anwendbarkeit in verschiedenen Bereichen weiter verbessern.
Insgesamt stellt OmniHuman-1 einen Wendepunkt in der Mensch-Video-Animation dar. Es ist ein leistungsstarkes Werkzeug, das das Potenzial hat, die Art und Weise, wie wir Inhalte erstellen, kommunizieren und interagieren, grundlegend zu verändern. Es liegt an uns, diese Technologie verantwortungsvoll und zum Wohle der Gesellschaft einzusetzen.
https://KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar. Hier kannst Du Dich in einer aktiven Community austauschen und KI lernen.
Quellen
- OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models (ArXiv)
- OmniHuman-1 Projektseite
#AI #KI #ArtificialIntelligence #KuenstlicheIntelligenz #OmniHuman1 #VideoAnimation #Deepfake #Bytedance
Über den Autor
Ich bin Oliver Welling, 57, und beschäftige mich mit Chatbots, seit ich ELIZA 1987 zum ersten Mal erlebt habe. Seit knapp zwei Jahren arbeite ich an den KINEWS24.de – jeden Tag gibt es die neuesten News und die besten KI-Tools – und eben auch: Jede Menge AI-Science. KI erlebe ich als Erweiterung meiner Fähigkeiten und versuche, mein Wissen zu teilen.
KI-Videogeneratoren haben scheinbar gerade Hochkonjunktur. Jede Woche kommen neue Features und neue spannende Möglichkeiten auf den Mark. Egal ob Runway, Luma, Hailuo, Kling, Krea – oder viele, viel andere. ByteDance sticht mit OmniHuman-1 aber deutlich hervor. Die Qualität, die wir hier sehen, gab es bisher noch nicht. Auch die Eingangs-Voraussetzungen „Photo“ und „Audio“ klingen einfach. Der neue Trainings-Ansatz „Omni-Conditions Training“ ermöglicht die Nutzung vielfältiger Daten für natürlichere Animationen – und auch die eingesetzte Diffusion Transformer-Architektur verbessert die Qualität und Effizienz der Videoerstellung.
Keine Frage, ByteDance OmniHuman-1 bietet extrem viele Anwendungsmöglichkeiten in Entertainment, Bildung und Content-Erstellung – ich freue mich das Modell zu benutzen, sobald es verfügbar ist! Prognose: Alle KI-Videogeneratoren werden in den kommenden Wochen von sich reden machen. ByteDance sorgt absolut sicher, für Sprachlosigkeit – und setzt die Branche sicher sehr unter Druck.






