Die Welt der künstlichen Intelligenz bewegt sich in rasantem Tempo, und mit der Vorstellung der Qwen3-Modellfamilie setzt Alibaba einen neuen, beeindruckenden Meilenstein. Insbesondere das jüngste Update, das Qwen3-235B-A22B-Instruct-2507, sorgt für Aufsehen. Es verspricht nicht nur massive Leistungssteigerungen, sondern definiert auch neu, was von einem frei verfügbaren Open-Source-Modell erwartet werden kann. Doch was steckt wirklich hinter diesem technologischen Kraftpaket?
In diesem umfassenden Artikel tauchen wir tief in die Architektur, die Trainingsmethoden und die reale Performance des neuen Flaggschiff-Modells ein. Du erfährst, wie es sich gegen etablierte Konkurrenten wie GPT-4o und Claude schlägt, welche innovativen Konzepte es einzigartig machen und wie du es selbst für deine Projekte nutzen kannst. Wir analysieren die offiziellen Daten und beleuchten das kritische Feedback der Community, um dir ein vollständiges und ehrliches Bild zu geben.
Das musst Du wissen – Qwen3-235B-Instruct-2507 in Kürze
- Neues Flaggschiff-Modell: Das Update
Qwen3-235B-A22B-Instruct-2507ist die neueste, optimierte Version, die in entscheidenden Benchmarks nicht nur ihr Vorgängermodell, sondern auch namhafte Konkurrenten übertrifft. - Innovative Architektur & riesiger Kontext: Es nutzt eine hocheffiziente Mixture-of-Experts (MoE)-Struktur mit 22 Milliarden aktiven von insgesamt 235 Milliarden Parametern und verfügt über ein natives 256K-Kontextfenster, was die Verarbeitung extrem langer Texte ermöglicht.
- Wirklich Open Source & Multilingual: Unter der freizügigen Apache 2.0 Lizenz ist das Modell vollständig kommerziell nutzbar und versteht dank Training auf 36 Billionen Tokens beeindruckende 119 Sprachen und Dialekte.
- Fokus auf Effizienz: Während die Qwen3-Familie einen „Thinking Mode“ für tiefes Nachdenken und einen „Non-Thinking Mode“ für schnelle Antworten kennt, ist das neue
-2507-Modell speziell für den Non-Thinking Mode optimiert, um maximale Performance und Anwenderfreundlichkeit zu gewährleisten.
Was ist Qwen3? Eine neue Generation von Open-Source-KI
Hinter Qwen3 steht der chinesische Tech-Gigant Alibaba, der mit dieser Modellreihe eine leistungsstarke und vor allem frei zugängliche Alternative zu den proprietären Systemen von OpenAI, Google und Anthropic geschaffen hat. Die Familie umfasst eine breite Palette von Modellen, die von kleinen, agilen Varianten mit 0,6 Milliarden Parametern bis hin zum gigantischen 235-Milliarden-Parameter-Modell reichen.
Das Besondere am Flaggschiff-Modell ist seine Mixture-of-Experts (MoE)-Architektur. Stell dir das nicht wie ein einzelnes, riesiges Gehirn vor, sondern wie ein hochspezialisiertes Expertenteam. Von den insgesamt 235 Milliarden Parametern werden pro Anfrage nur etwa 22 Milliarden „aktiviert“ – nämlich genau die Experten, die für die jeweilige Aufgabe am besten geeignet sind. Dieses Design macht das Modell nicht nur extrem leistungsfähig, sondern auch überraschend effizient im Betrieb.
Die Revolution im Denken: Thinking vs. Non-Thinking Mode erklärt
Eine der zentralen Innovationen der Qwen3-Architektur ist die Integration von zwei grundlegend verschiedenen Betriebsmodi in einem einzigen Modell.
- Thinking Mode: Dieser Modus ist für komplexe, mehrstufige Denkprozesse konzipiert. Wenn das Modell eine schwierige Mathematikaufgabe lösen oder einen komplizierten Code-Bug finden soll, nutzt es diesen Modus, um Schritt für Schritt zu einer Lösung zu gelangen. Entwickler können dem Modell sogar ein „Thinking Budget“ zuweisen, also eine bestimmte Anzahl von Tokens, die es für seinen Denkprozess verwenden darf.
- Non-Thinking Mode: Dieser Modus ist auf schnelle, kontextbasierte Antworten ausgelegt. Für Aufgaben wie eine schnelle Zusammenfassung, eine Übersetzung oder eine einfache Frage-Antwort-Situation ist dieser Modus ideal, da er ohne lange „Denkpausen“ direkt zur Sache kommt.
Mit dem Release des Qwen3-235B-A22B-Instruct-2507 hat das Entwicklerteam einen klaren Fokus gesetzt: Dieses Modell ist vollständig auf den Non-Thinking Mode spezialisiert und optimiert. Es erfordert keine speziellen Parameter mehr zur Aktivierung und wurde darauf trainiert, seine beeindruckenden Fähigkeiten ohne den expliziten Denkprozess abzurufen, was die Nutzung vereinfacht und die Antwortgeschwindigkeit erhöht.
Das Update 2507: Was ist neu am Qwen3-235B-A22B-Instruct-2507?
Das -2507-Update ist mehr als nur eine kleine Anpassung. Es stellt eine gezielte Weiterentwicklung dar, die auf direktem Nutzerfeedback und umfassenden Analysen basiert. Die Kernverbesserungen sind:
- Gesteigerte Allgemeinfähigkeiten: Das Modell wurde in zentralen Disziplinen wie dem Befolgen von Anweisungen (Instruction Following), logischem Denken, Textverständnis, Mathematik, Wissenschaft und Programmierung signifikant verbessert.
- Erweitertes Wissen: Die Abdeckung von Nischen- und „Long-Tail“-Wissen in einer Vielzahl von Sprachen wurde stark ausgebaut.
- Besseres Alignment: Bei subjektiven und offenen Fragestellungen orientiert sich das Modell nun deutlich besser an den Präferenzen der Nutzer. Das Ergebnis sind hilfreichere Antworten und eine höhere Qualität bei der Texterstellung.
- Optimiertes Langkontext-Verständnis: Die Fähigkeit, Informationen aus extrem langen Texten (bis zu 262.144 Tokens) zu extrahieren und zu verarbeiten, wurde weiter gestärkt.
Leistung im Härtetest: Qwen3-2507 in den Benchmarks
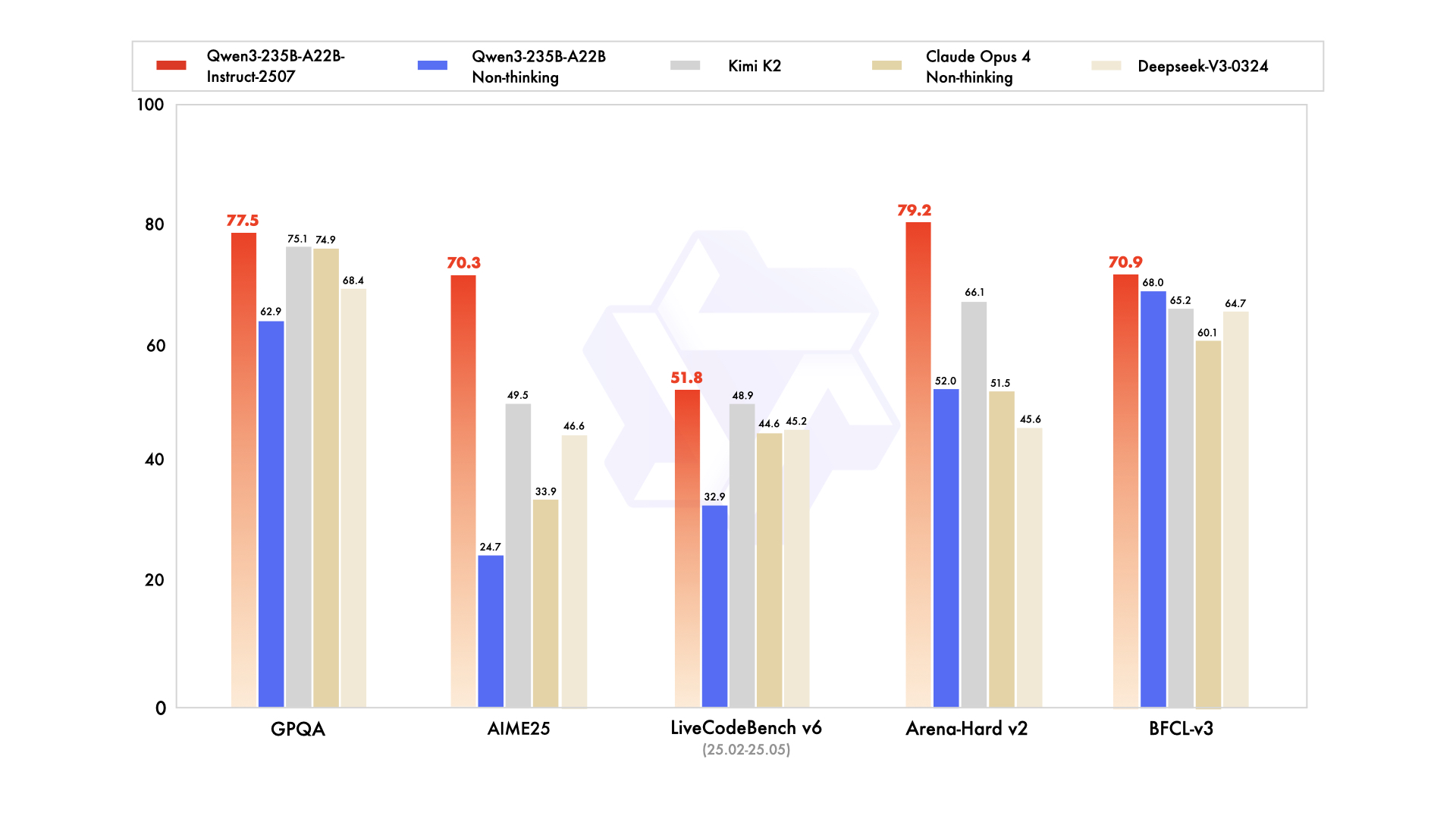
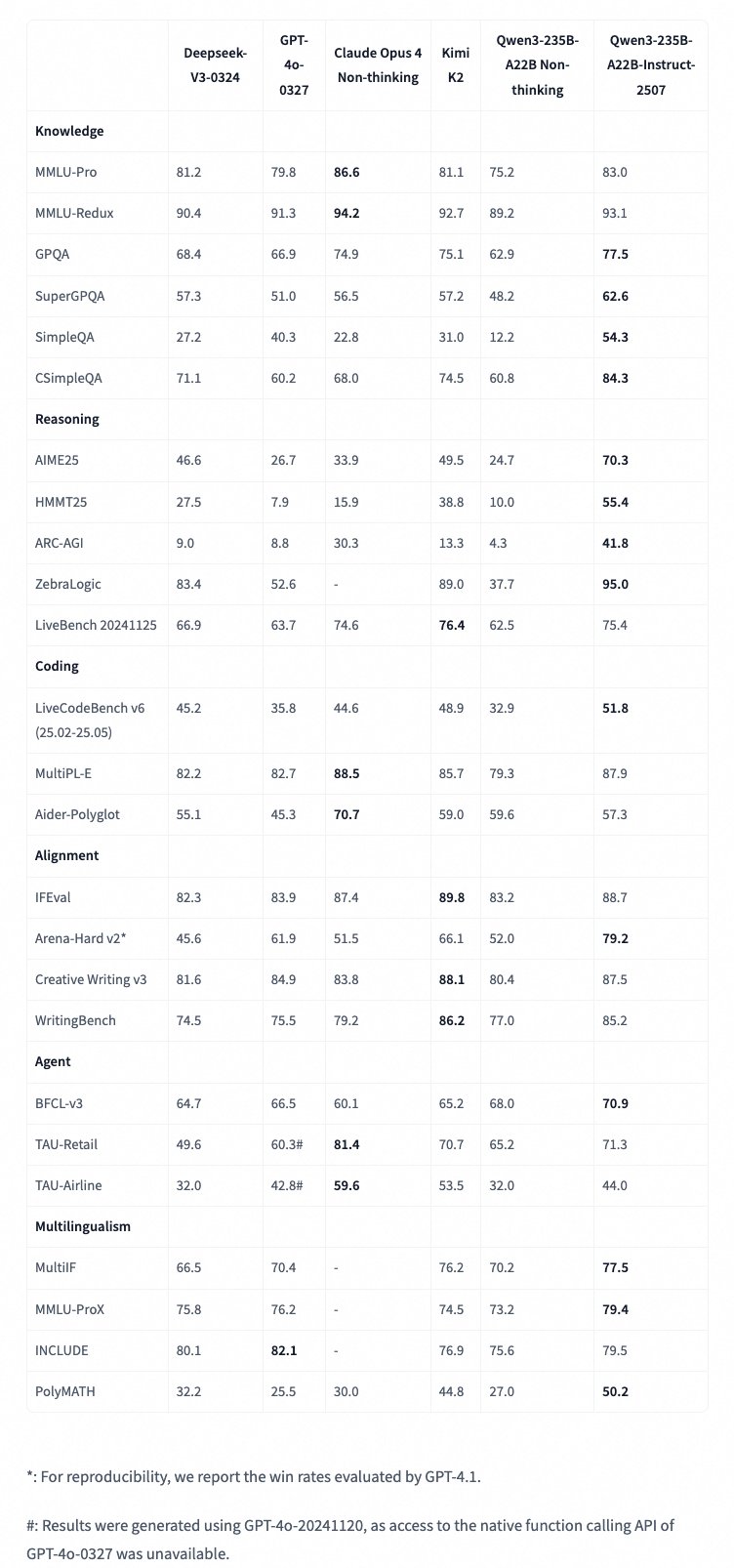
Zahlen sagen oft mehr als tausend Worte. Die Performance des neuen Qwen3-Modells im Vergleich zu den stärksten Konkurrenten ist beeindruckend. Die folgende Tabelle fasst einige der wichtigsten Benchmark-Ergebnisse zusammen:
| Benchmark | Metrik | Qwen3-2507 (Neu) | GPT-4o-0327 | Claude Opus 4 | Deepseek-V3-0324 | Kimi K2 | Qwen3 Non-thinking (Alt) |
| Wissen | MMLU-Pro | 83.0 | 79.8 | 86.6 | 81.2 | 81.1 | 75.2 |
| GPQA | 77.5 | 66.9 | 74.9 | 68.4 | 75.1 | 62.9 | |
| CSimpleQA | 84.3 | 60.2 | 68.0 | 71.1 | 74.5 | 60.8 | |
| Logik & Mathe | AIME’25 | 70.3 | 26.7 | 33.9 | 46.6 | 49.5 | 24.7 |
| ZebraLogic | 95.0 | 52.6 | – | 83.4 | 89.0 | 37.7 | |
| Coding | LiveCodeBench v6 | 51.8 | 35.8 | 44.6 | 45.2 | 48.9 | 32.9 |
| Alignment | Arena-Hard v2* | 79.2 | 61.9 | 51.5 | 45.6 | 66.1 | 52.0 |
| Mehrsprachig | MultiIF | 77.5 | 70.4 | – | 66.5 | 76.2 | 70.2 |
*Win-Rate ausgewertet durch GPT-4.1 zur Reproduzierbarkeit.
Wie du siehst, positioniert sich Qwen3-235B-A22B-Instruct-2507 als extrem starker Konkurrent. Besonders in anspruchsvollen Logik- und Mathematik-Benchmarks wie AIME’25 und ZebraLogic deklassiert es die Konkurrenz teilweise deutlich. Auch in Wissens- und Programmieraufgaben zeigt es eine Leistung auf oder über dem Niveau der besten proprietären Modelle.
Jenseits der Benchmarks: Nutzerfeedback und reale Performance
Während Benchmarks die theoretische Leistungsfähigkeit messen, zeigt sich die wahre Stärke eines Modells erst im praktischen Einsatz. Das Feedback aus der Entwickler-Community zeichnet ein differenziertes Bild:
Positive Rückmeldungen:
- Hervorragende Coding-Fähigkeiten: Viele Nutzer loben die Performance bei Programmieraufgaben. Spezielle Coder-Varianten von Qwen3 werden als konkurrenzfähig zu Premium-Modellen wie Claude Sonnet und Opus beschrieben.
- Geschwindigkeit und Effizienz: Die Inferenzgeschwindigkeit, insbesondere auf moderner Hardware wie Apple Silicon (M-Chips), wird konstant als beeindruckend hoch gelobt.
- Kosteneffizienz: Die MoE-Architektur und der Open-Source-Ansatz ermöglichen den Betrieb leistungsstarker KI zu einem Bruchteil der Kosten proprietärer APIs, oft sogar lokal auf der eigenen Hardware.
Kritik und Limitationen:
- Diskrepanz zwischen Benchmarks und Realität: Einige Nutzer berichten, dass die überragenden Benchmark-Ergebnisse, insbesondere im Coding, sich nicht immer in komplexen, realen Projekten widerspiegeln.
- Vorwurf des „Benchmark Hacking“: In der Community gibt es Diskussionen darüber, ob die Modelle gezielt auf Benchmarks hin optimiert wurden, was ihre Allgemeingültigkeit in Frage stellen könnte.
- Schwächen im komplexen Reasoning: Im Vergleich zu dedizierten Reasoning-Modellen wie QwQ (ebenfalls aus der Qwen-Familie) wird berichtet, dass Qwen3 bei sehr tiefgehenden logischen Herausforderungen zurückfällt.
- Wissensstand: Wie alle aktuellen LLMs hat auch Qwen3 einen Wissensstichtag und ist nicht mit Echtzeitinformationen verbunden.
Anleitung für den Einstieg: So nutzt Du Qwen3 selbst
Dank der Veröffentlichung auf Plattformen wie Hugging Face ist der Einstieg in Qwen3 unkompliziert.
Best Practices für optimale Ergebnisse:
- Sampling-Parameter: Die Entwickler empfehlen
Temperature=0.7,TopP=0.8undTopK=20. - Ausgabelänge: Setze die maximale Ausgabelänge großzügig (z. B. 16.384 Tokens), um dem Modell genügend Raum zu geben.
- Standardisierte Prompts: Für spezifische Aufgaben wie Mathematik-Probleme, füge dem Prompt Anweisungen wie
"Bitte schlussfolgere Schritt für Schritt und setze deine finale Antwort in ein \boxed{}"hinzu, um die besten Ergebnisse zu erzielen.
Fazit und Ausblick
Das Qwen3-235B-A22B-Instruct-2507 ist ohne Zweifel ein gewaltiger Schritt nach vorn für die Open-Source-KI-Community. Es demonstriert eindrucksvoll, dass frei verfügbare Modelle nicht nur mit den besten proprietären Systemen mithalten, sondern sie in spezifischen, anspruchsvollen Disziplinen sogar übertreffen können. Die Kombination aus einer hocheffizienten MoE-Architektur, einem gigantischen Kontextfenster, echter Mehrsprachigkeit und einer liberalen kommerziellen Lizenz macht es zu einem der attraktivsten KI-Modelle auf dem Markt.
Die Stärken liegen klar in der rohen Leistungsfähigkeit bei Logik-, Mathematik- und Wissensaufgaben sowie in der beeindruckenden Geschwindigkeit und Kosteneffizienz. Gleichzeitig zeigt das kritische Feedback der Community, dass der Weg zur perfekten Allround-KI noch weit ist und eine gesunde Skepsis gegenüber reinen Benchmark-Ergebnissen angebracht ist. Die Entwickler bei Alibaba haben jedoch bewiesen, dass sie auf Feedback hören und ihre Modelle in kurzen Zyklen signifikant verbessern.
Mit dem Fokus auf die weitere Skalierung von Trainingsdaten, die Verbesserung der Modellarchitektur und die Erforschung von agentenbasiertem Reinforcement Learning steht die nächste Revolution bereits vor der Tür. Qwen3 ist heute schon ein unglaublich mächtiges Werkzeug, das Entwicklern und Unternehmen weltweit neue Möglichkeiten eröffnet und den Wettbewerb im KI-Sektor weiter anheizt.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
- Qwen Team. (2025). Qwen3 Technical Report. arXiv:2505.09388v1 [cs.CL]. Verfügbar unter: https://arxiv.org/abs/2505.09388
- Qwen. (2025). Qwen/Qwen3-235B-A22B-Instruct-2507. Hugging Face. Verfügbar unter: https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507
- 通义千问. (2025). Qwen/Qwen3-235B-A22B-Instruct-2507. ModelScope. Verfügbar unter: https://modelscope.cn/models/Qwen/Qwen3-235B-A22B-Instruct-2507
- 通义千问. (2025). Qwen/Qwen3-235B-A22B-Instruct-2507-FP8. ModelScope. Verfügbar unter: https://modelscope.cn/models/Qwen/Qwen3-235B-A22B-Instruct-2507-FP8
- https://view.caduceusapp.eu/apollonvisual/qwenllmmodelsalibaba
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #Qwen3 #LLM #OpenSource #Alibaba, Qwen3 235B Instruct







