

Was, wenn Du ein KI-Modell mit der Power eines 80-Milliarden-Parameter-Giganten haben könntest, das aber so schnell und günstig läuft wie ein winziges 3-Milliarden-Modell? Genau das verspricht Alibaba mit dem Qwen3-Next-80B-A3B, einer technologischen Sensation, die die Spielregeln für Künstliche Intelligenz neu schreibt. Mit einer 10-fachen Kostenreduktion bei Training und Inferenz stellt dieses Modell nicht nur die Konkurrenz in den Schatten, sondern demokratisiert den Zugang zu Spitzen-KI.
Du stehst vor der Herausforderung, dass leistungsstarke KI-Modelle immense Rechenleistung und Budgets verschlingen, was Innovationen oft ausbremst. Qwen3-Next löst dieses Kernproblem mit einer revolutionären Hybrid-Architektur, die brachiale Leistung mit beispielloser Effizienz verbindet. In diesem Artikel zerlegen wir die Technologie hinter diesem Durchbruch, zeigen Dir, wie Du sie praktisch einsetzen kannst, und analysieren, warum dies Alibabas „DeepSeek-Moment“ sein könnte, der die gesamte Branche verändert.
Bist Du bereit, die Zukunft der KI-Effizienz zu entdecken? Wir führen Dich Schritt für Schritt durch die Architektur, die Performance-Benchmarks und die praktischen Anwendungsfälle. Am Ende wirst Du nicht nur verstehen, was Qwen3-Next ist, sondern auch, wie es Deine Arbeit mit KI fundamental verbessern kann.
Beeindruckend: Qwen3-Max Preview ist Alibabas KI-Gigant mit 1 Billion Parametern fordert ChatGPT & Co. heraus – erschienen am 7.9.2025 – jetzt bereits Qwen3-Next. Der Konkurrenzdruck auf die US-KI Industrie steigt stetig. China hat immer schneller immer bessere Modelle!
Qwen3-Next – Das Wichtigste in Kürze
- Revolutionäre Effizienz: Qwen3-Next ist ein 80-Milliarden-Parameter-Modell, das pro Inferenz-Schritt nur 3 Milliarden Parameter aktiviert. Dies führt zu einer 90%igen Reduktion der Trainingskosten und einer 10-fachen Beschleunigung der Inferenzgeschwindigkeit.
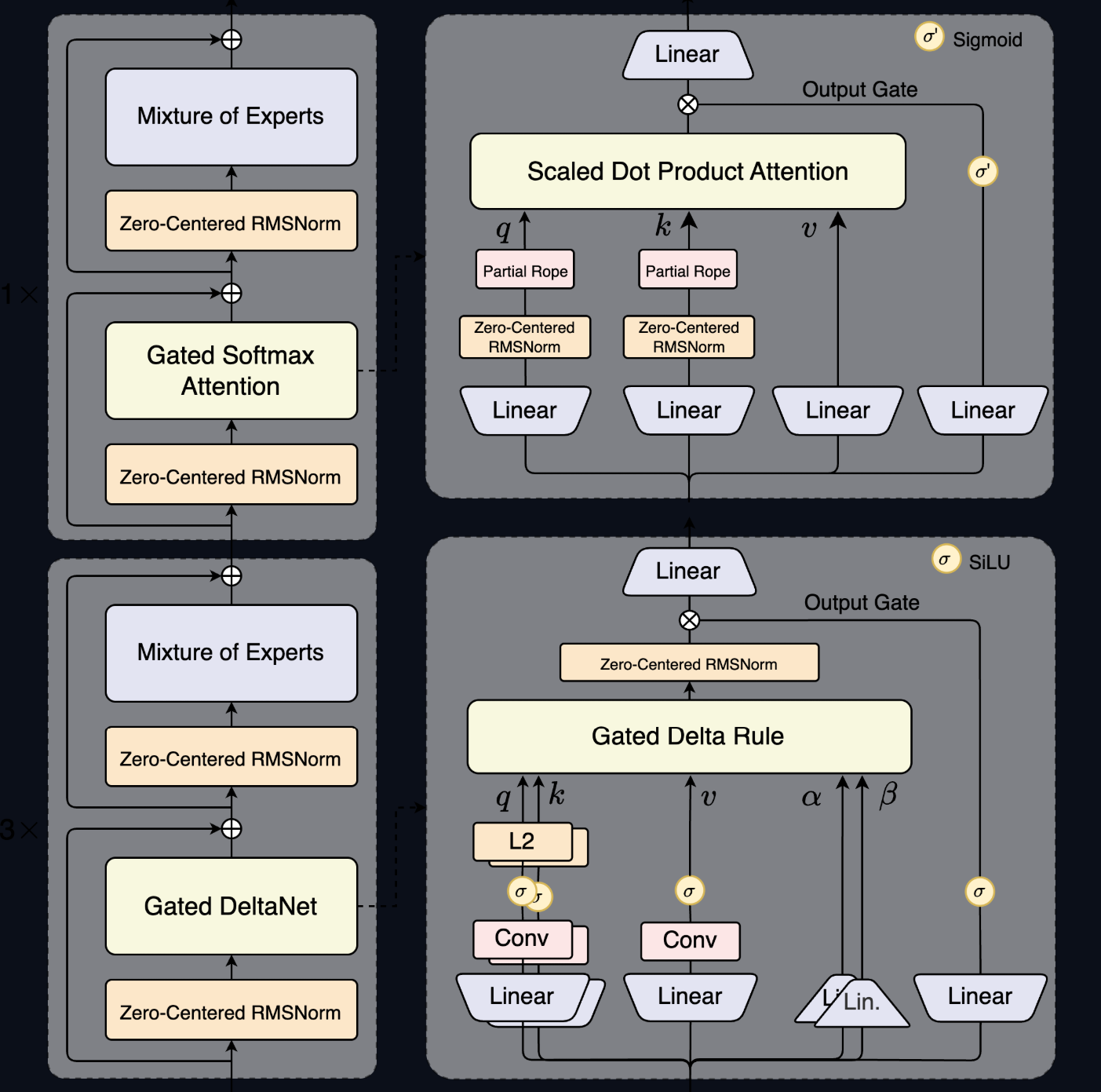
- Hybride Architektur: Das Modell kombiniert erstmals zwei Aufmerksamkeitsmechanismen: schnelles „Gated DeltaNet“ (75% der Layer) für lange Kontexte und präzises „Gated Attention“ (25%) für Detailgenauigkeit.
- Extreme Sparsamkeit (Sparsity): Durch ein Ultra-Sparse Mixture-of-Experts (MoE) Design werden aus 512 verfügbaren „Experten“ nur 11 pro Token ausgewählt, was die Ressourcennutzung maximiert.
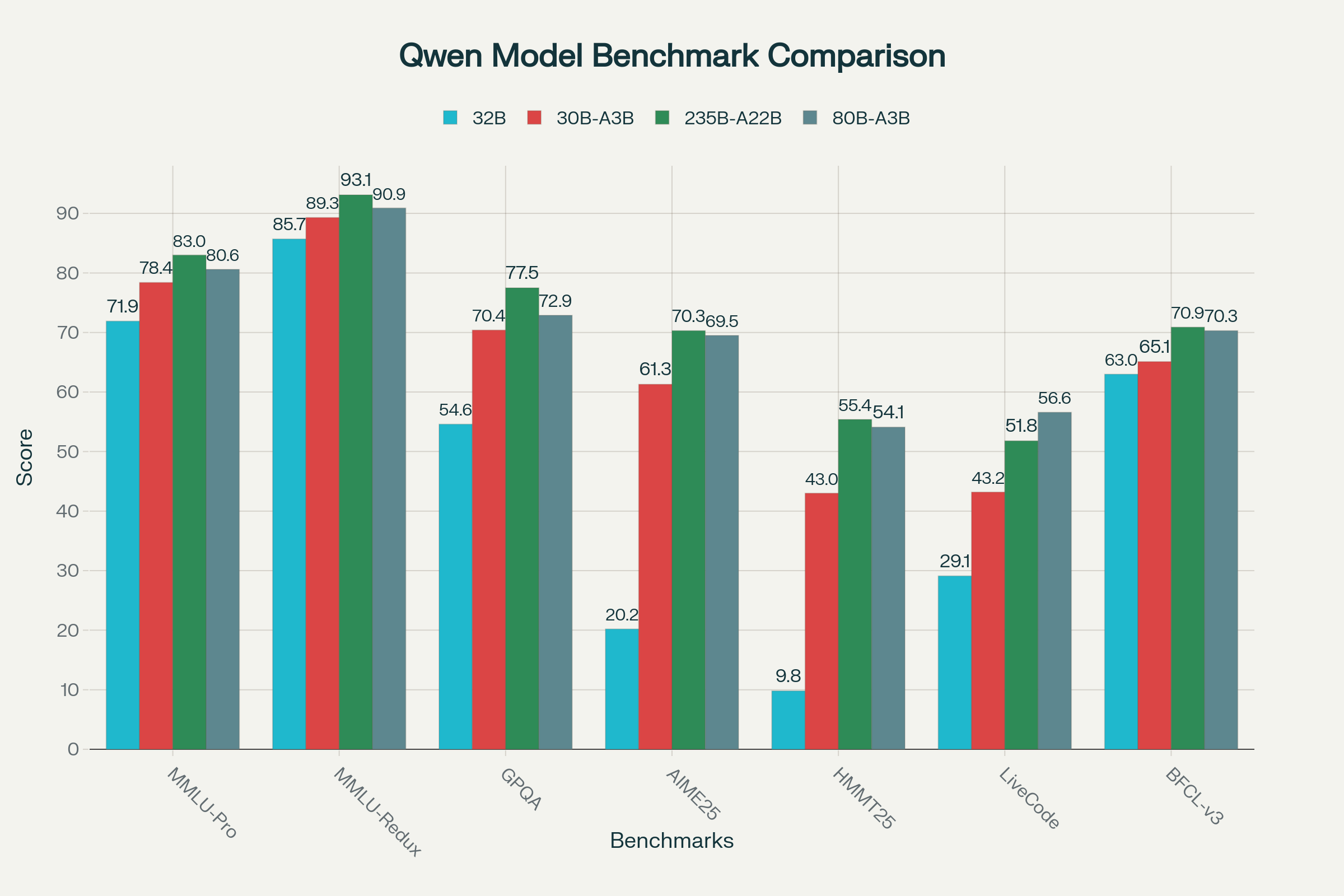
- Überlegene Performance: Trotz seiner Effizienz schlägt Qwen3-Next das 32B-Modell in Benchmarks und konkurriert bei komplexem Schlussfolgern und Langkontext-Aufgaben sogar mit dem 235B-Flaggschiff-Modell. Die „Thinking“-Variante übertrifft Gemini-2.5-Flash.
- Langkontext-Champion: Mit einer nativen Kontextlänge von 262.144 Tokens (erweiterbar auf über 1 Million) ist das Modell ideal für die Analyse umfangreicher Dokumente, Codebasen oder wissenschaftlicher Daten.
- Zwei spezialisierte Varianten: Verfügbar als
Instruct-Version für stabile, anwendungsbereite Antworten und alsThinking-Version für komplexe, mehrstufige Denkprozesse. - Sofort verfügbar: Das Modell ist bereits über Plattformen wie Hugging Face, SGLang, vLLM und die Alibaba Cloud API zugänglich und einsatzbereit.
Deep-Dive: Die Genialität der Qwen3-Next-Architektur
Um die Revolution zu verstehen, müssen wir unter die Haube schauen. Qwen3-Next ist kein gewöhnliches LLM. Seine Leistung beruht auf drei Säulen, die es von allem bisher Dagewesenen abheben.

1. Die Hybrid-Attention: Das Beste aus zwei Welten
Traditionelle Transformer-Modelle nutzen ausschließlich den „Scaled Dot-Product Attention“-Mechanismus. Dieser ist extrem präzise, aber seine Rechenkomplexität steigt quadratisch mit der Länge des Kontexts (O(n2)). Das macht die Verarbeitung langer Texte langsam und teuer.
Qwen3-Next bricht diese Regel mit einer genialen Hybrid-Struktur:
- Gated DeltaNet (75% der Layer): Ein linearer Aufmerksamkeitsmechanismus, dessen Komplexität nur linear wächst (O(n)). Er ist wie ein Sprinter – unglaublich schnell bei der Verarbeitung langer Sequenzen, aber vielleicht nicht in jeder Kurve perfekt.
- Gated Attention (25% der Layer): Der klassische, hochpräzise Mechanismus. Er ist der Chirurg, der an kritischen Stellen für maximale Genauigkeit sorgt.
Durch die Verteilung im Verhältnis 3:1 (drei DeltaNet-Layer gefolgt von einem Gated-Attention-Layer) erreicht das Modell eine perfekte Balance. Es verarbeitet riesige Datenmengen in Rekordzeit und sichert die Qualität durch gezielte Präzisions-Checks. Man kann es sich wie eine „architekturelle spekulative Dekodierung“ vorstellen: Die schnellen Layer machen den Hauptteil der Arbeit, die präzisen Layer korrigieren und verfeinern.
2. Ultra-Sparse Mixture-of-Experts (MoE)
Die zweite Säule ist die extreme Sparsamkeit. Stell Dir vor, Du hast 512 Fachexperten, aber für jede einzelne Frage musst Du nur die 11 relevantesten konsultieren. Genau das macht das MoE-System von Qwen3-Next.
- 512 Experten insgesamt: Eine riesige Wissensbasis.
- 11 aktive Experten pro Token: Für jedes Wort im Text wählt ein „Router“ 10 spezialisierte Experten und einen allgemeinen „geteilten“ Experten aus.
- Aktivierungsrate von nur 3,75%: Weniger als 4% des gesamten Modells sind zu einem beliebigen Zeitpunkt aktiv.
Dieses Design reduziert den Rechenaufwand drastisch, ohne die Wissensbreite des 80-Milliarden-Parameter-Modells zu opfern. Es ist der Grund, warum Qwen3-Next so effizient ist.

3. Multi-Token Prediction (MTP) für Turbo-Inferenz
Als wäre das nicht genug, nutzt Qwen3-Next auch Multi-Token Prediction. Anstatt nur das nächste Wort vorherzusagen, versucht das Modell, mehrere zukünftige Wörter gleichzeitig zu erraten. Dies beschleunigt nicht nur das Training, sondern verbessert auch die Inferenzgeschwindigkeit erheblich, insbesondere im Zusammenspiel mit spekulativen Dekodierungstechniken.
Praktische Anleitung: So setzt Du Qwen3-Next in 10 Schritten ein
Theorie ist gut, Praxis ist besser. Wir zeigen Dir, wie Du Qwen3-Next mit dem optimierten Inferenz-Framework SGLang startklar machst.
Voraussetzung: Eine Umgebung mit ausreichend VRAM (z.B. 4x NVIDIA A100 80GB) und installierten NVIDIA-Treibern.
- Installiere SGLang: SGLang ist für die Performance von Qwen3-Next optimiert, insbesondere für MTP.Bash
pip install "sglang[all]" --find-links https://flashinfer.ai/whl/cu121/torch2.4/ - Lade das Modell: Stelle sicher, dass Du Zugriff auf das Modell über Hugging Face hast. Du benötigst einen Hugging Face Account und musst eventuell die Lizenzbedingungen auf der Modellseite akzeptieren.
- Login via CLI: Authentifiziere Dich bei Hugging Face in Deinem Terminal.Bash
huggingface-cli login - Starte den SGLang Server: Dieser Befehl startet den Server für das
Instruct-Modell mit Tensor-Parallelität auf 4 GPUs und einer Kontextlänge von 262K.Bashpython -m sglang.launch_server \ --model-path Qwen/Qwen3-Next-80B-A3B-Instruct \ --tp-size 4 \ --context-length 262144 - Aktiviere MTP (Optional, für mehr Speed): Für einen zusätzlichen Geschwindigkeitsschub kannst Du die Multi-Token Prediction explizit aktivieren.Bash
python -m sglang.launch_server \ --model-path Qwen/Qwen3-Next-80B-A3B-Instruct \ --tp-size 4 \ --enable-mtp - Öffne einen neuen Terminal: Lass den Server im ersten Terminal laufen.
- Installiere OpenAI Client: Die Interaktion mit dem Server erfolgt über eine OpenAI-kompatible API.Bash
pip install openai - Schreibe ein Python-Skript: Erstelle eine Datei
test_qwen.pyund füge folgenden Code ein:Pythonimport openai # Setze den API-Client auf den lokalen SGLang-Server client = openai.OpenAI( base_url="http://localhost:30000/v1", api_key="EMPTY" ) # Definiere Deine Anfrage completion = client.chat.completions.create( model="Qwen/Qwen3-Next-80B-A3B-Instruct", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Erkläre die Kernidee der Hybrid-Attention-Architektur von Qwen3-Next in einfachen Worten."} ] ) # Gib die Antwort aus print(completion.choices[0].message.content) - Führe das Skript aus:Bash
python test_qwen.py - Ergebnis analysieren: Du erhältst eine qualitativ hochwertige Antwort vom Modell, die in Rekordzeit generiert wurde. Herzlichen Glückwunsch, Du nutzt eines der effizientesten LLMs der Welt!
Vergleichsmatrix: Qwen3-Next vs. Traditionelle Architekturen
| Dimension | Traditioneller Transformer (Dense) | Standard MoE-Modell (z.B. Mixtral) | Qwen3-Next (Hybrid & Sparse) |
| Architektur | Rein Attention-basiert | Attention + MoE-Layer | Hybrid (Gated Attention + Gated DeltaNet) + Ultra-Sparse MoE |
| Parameter-Aktivierung | 100% | ca. 15-25% | ~3.75% |
| Rechenkomplexität | O(n2) | O(n2) (in Attention-Layern) | Mix aus O(n) und O(n2), stark optimiert |
| Langkontext-Effizienz | Gering (sehr teuer) | Mittel | Extrem hoch (10x schneller > 32K Tokens) |
| Trainingskosten | Sehr hoch | Hoch | Sehr niedrig (90% Reduktion) |
| Inferenzgeschwindigkeit | Langsam | Mittel bis schnell | Extrem schnell (10x Verbesserung) |
| Ideal für… | Aufgaben mit kurzem Kontext, hohe Präzision | Balance aus Leistung und Effizienz | Lange Dokumentenanalyse, Code-Generierung, Echtzeitanwendungen |
Fallstudien: Wo Qwen3-Next heute schon glänzt
- Rechtskanzlei „LexTech“: Die Kanzlei nutzt Qwen3-Next, um tausende Seiten an Gerichtsakten und Verträgen in Minuten zu analysieren. Dank der riesigen Kontextlänge kann das Modell komplexe Zusammenhänge über ganze Dokumentenstapel hinweg erkennen. Die Inferenzkosten sind im Vergleich zum vorherigen Dense-Modell um 85% gesunken, während die Bearbeitungszeit pro Fall von Stunden auf Minuten reduziert wurde.
- Forschungsinstitut „BioGenomics“: Das Institut setzt die
Thinking-Variante ein, um komplexe Gensequenzdaten zu analysieren und Hypothesen für neue Forschungspfade zu generieren. Die Fähigkeit des Modells, lange, logische Gedankengänge zu verfolgen (<think>-Tags), ermöglicht tiefere Einblicke als je zuvor. Die 10-fache Trainings-Effizienz erlaubt es ihnen, das Modell schneller auf proprietären Daten zu finetunen.
Die 5 häufigsten Fehler bei der Implementierung und wie Du sie vermeidest
- Unzureichende Hardware: Auch wenn nur 3B Parameter aktiv sind, muss das gesamte 80B-Modell in den GPU-Speicher passen. Unterschätze den VRAM-Bedarf nicht! Lösung: Nutze mindestens A100/H100 80GB GPUs oder setze auf Cloud-APIs.
- Falsches Inferenz-Framework: Die Verwendung eines nicht optimierten Frameworks wie Standard-Transformers verschenkt das gesamte Geschwindigkeitspotenzial. Lösung: Setze auf
SGLangodervLLM, die speziell für Architekturen wie Qwen3-Next optimiert sind. - MTP nicht nutzen: Die Multi-Token Prediction ist ein Schlüssel zur maximalen Geschwindigkeit. Sie nicht zu aktivieren ist eine verpasste Chance. Lösung: Nutze den
--enable-mtpFlag in SGLang. - YaRN-Skalierung für kurze Texte: Die Erweiterung des Kontexts auf 1 Million Tokens mit YaRN ist mächtig, kann aber die Performance bei kurzen Anfragen leicht beeinträchtigen. Lösung: Aktiviere die YaRN-Konfiguration nur, wenn Du sie wirklich für extrem lange Kontexte benötigst.
- Falsche Modellvariante wählen: Den
Thinking-Build für eine schnelle Chatbot-Antwort zu verwenden, kann zu unnötig langen und komplexen Ausgaben führen. Lösung: NutzeInstructfür die meisten produktiven Anwendungen undThinkinggezielt für komplexe Reasoning-Aufgaben.
Zukunftsausblick Qwen3-Next: Ein neues Zeitalter der KI-Effizienz
Qwen3-Next ist mehr als nur ein neues Modell. Es ist ein starkes Signal, dass die Zukunft der KI nicht allein in immer größeren Modellen liegt, sondern in intelligenteren Architekturen. Alibaba hat hier einen Weg aufgezeigt, wie man Leistung und Effizienz entkoppeln kann – ein Meilenstein, der oft als „DeepSeek-Moment“ bezeichnet wird, in Anlehnung an den ähnlichen Effizienz-Durchbruch von DeepSeek-AI.
Wir können erwarten, dass andere große KI-Labore nachziehen werden. Hybrid-Architekturen, die schnelle lineare und präzise quadratische Mechanismen kombinieren, könnten zum neuen Standard werden. Für Entwickler und Unternehmen bedeutet das: Der Zugang zu KI auf höchstem Niveau wird günstiger, schneller und zugänglicher. Die Ära der KI-Effizienz hat gerade erst begonnen.
Tools & Ressourcen für Deinen Start
- Hugging Face Collection: Der zentrale Hub für alle Modelle und technischen Details.
- Offizieller Qwen Blogpost: Die primäre Quelle mit allen technischen Erklärungen vom Entwicklerteam.
- SGLang auf GitHub: Das empfohlene Inferenz-Framework für maximale Performance.
- vLLM auf GitHub: Eine weitere exzellente, hochperformante Inferenz-Bibliothek.
- Alibaba Cloud Model Studio: Für den direkten API-Zugriff auf das Modell.
- ModelScope: Alibabas eigene Plattform für KI-Modelle.
- Kaggle-Modelle: Qwen3-Next für Experimente in der Kaggle-Umgebung.
- Together.ai API: Eine beliebte Plattform, die Qwen3-Next als API anbietet.
- OpenRouter API: Aggregiert verschiedene LLM-APIs, inklusive Qwen3-Next.
- Flash-Linear-Attention: Die zugrundeliegende Bibliothek für die beschleunigte lineare Attention.
Kosten-Nutzen-Analyse: Wann sich der Umstieg lohnt
| Szenario | Kosten mit traditionellem 32B-Modell | Kosten mit Qwen3-Next-80B | ROI / Nutzen |
| Batch-Analyse von 10.000 Dokumenten (je 40K Tokens) | ca. 20 GPU-Stunden | ca. 2 GPU-Stunden | 90% Kostenersparnis bei Inferenz, schnellerer Projektabschluss |
| Modell-Finetuning auf proprietären Daten | 100% Trainingskosten (Baseline) | 9.3% Trainingskosten | Massive Reduktion der F&E-Kosten, schnellere Iterationszyklen |
| Betrieb eines Echtzeit-Code-Assistenten | Hohe Latenz, hohe Serverkosten | Geringe Latenz, 10x niedrigere Serverkosten | Verbesserte User Experience, signifikant niedrigere Betriebskosten (OPEX) |
Häufig gestellte Fragen zu Qwen3-Next
1. Muss ich wirklich Hardware für ein 80B-Modell vorhalten? Ja, der gesamte Parametersatz von 80 Milliarden muss in den VRAM der GPUs geladen werden, auch wenn nur 3 Milliarden pro Token aktiv sind. Der Router benötigt Zugriff auf alle Experten, um die richtigen auszuwählen.
2. Was ist der Unterschied zwischen der Instruct- und der Thinking-Variante? Die Instruct-Version ist für direkte Anweisungen optimiert und liefert stabile, produktionsreife Antworten. Die Thinking-Version ist für komplexe Denkprozesse konzipiert und gibt ihre „Gedankengänge“ oft in <think>-Tags aus, was ideal für Analyse- und Reasoning-Aufgaben ist.
3. Wie schneidet Qwen3-Next im Vergleich zu GPT-4 oder Claude 3 ab? Direkte Vergleiche sind komplex. In reiner Effizienz (Performance pro Watt/Euro) ist Qwen3-Next bahnbrechend. In Benchmarks für Schlussfolgern und Langkontext nähert es sich der Leistung von Flaggschiff-Modellen wie Qwen3-235B an, was es in die Nähe der Top-Liga rückt, aber zu einem Bruchteil der Betriebskosten.
4. Ist Qwen3-Next Open Source? Ja, das Modell wird unter einer Open-Source-Lizenz veröffentlicht, die kommerzielle Nutzung erlaubt, ähnlich wie frühere Qwen-Modelle. Es ist Teil von Alibabas Strategie, Innovationen mit der Community zu teilen.
5. Kann ich Qwen3-Next für andere Sprachen als Englisch und Chinesisch verwenden? Absolut. Qwen3-Next erbt die starken multilingualen Fähigkeiten der Qwen-Serie und unterstützt eine Vielzahl von gängigen Sprachen und Programmiersprachen.
6. Was ist Gated DeltaNet genau? Gated DeltaNet ist eine fortgeschrittene Form der linearen Attention. Das „Gated“ bezieht sich auf einen Mechanismus, der dem Modell erlaubt zu steuern, welche Informationen durchgelassen werden, was die Qualität im Vergleich zu einfacheren linearen Attention-Varianten verbessert.
7. Wie stabil ist das Training eines solch komplexen Modells? Das Qwen-Team hat erhebliche Anstrengungen unternommen, um die Trainingsstabilität zu gewährleisten. Techniken wie Zero-Centered RMSNorm und optimierte Router-Initialisierung waren entscheidend, um die Herausforderungen eines ultra-sparsamen Hybrid-Modells zu meistern.
Fazit Qwen3-Next: Mehr als nur ein neues Modell – eine neue Philosophie
Qwen3-Next-80B-A3B ist kein lautes Marketing-Versprechen, sondern ein leiser, aber fundamentaler technologischer Durchbruch. Alibaba hat bewiesen, dass der Wettlauf um immer größere KI-Modelle nicht der einzige Weg ist. Intelligente Architektur kann rohe Gewalt nicht nur einholen, sondern übertreffen – zumindest, wenn man die Effizienz als entscheidende Metrik heranzieht. Die Kombination aus Hybrid-Attention und Ultra-Sparse MoE setzt einen neuen Standard, an dem sich zukünftige Modelle messen lassen müssen.
Die Implikationen sind gewaltig. Für Entwickler, Forscher und Unternehmen öffnet sich die Tür zu Anwendungen, die bisher an den horrenden Kosten gescheitert sind. Die Analyse riesiger Datenmengen, die Entwicklung hochreaktiver KI-Agenten und der breite Einsatz von KI in ressourcenbeschränkten Umgebungen rücken in greifbare Nähe. Dieses Modell ist ein Werkzeug, das nicht nur Antworten generiert, sondern auch die ökonomischen Barrieren der KI-Revolution einreißt.
Deine nächsten Schritte sind klar: Wenn Du mit langen Kontexten arbeitest, kostenintensive KI-Workloads betreibst oder einfach nur an der Spitze der technologischen Entwicklung bleiben willst, musst Du Dich mit Qwen3-Next auseinandersetzen. Nutze die bereitgestellten Ressourcen, experimentiere mit den Deployment-Anleitungen und erlebe selbst, wie sich eine 10-fache Effizienzsteigerung anfühlt. Die Zukunft der KI ist nicht nur größer, sie ist vor allem schlauer und effizienter geworden.
Quellen und weiterführende Literatur
- Qwen Team (2025): Offizieller Blogpost zur Veröffentlichung von Qwen3-Next
- Hugging Face (2025): Qwen3-Next Model Collection
- SGLang Project (2025): GitHub Repository für optimierte LLM-Inferenz
- vLLM Project (2025): GitHub Repository für High-Throughput LLM Inference
- ModelScope (2025): Qwen3-Next Collection auf Alibabas Plattform
- Alibaba Cloud (2025): Model Studio API Dokumentation
- qwq32.com (2025): Technische Analyse von Qwen3-Next
- Alibaba Qwen (2025): Offizielle Ankündigung auf X.com
- Shazeer, Noam et al. (2017): „Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer“ – Grundlagenpapier zu MoE.
- Dao, Tri et al. (2022): „FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness“ – Wichtige Forschung zu effizienter Attention.






