
Ein Team von Forschern hat SICA entwickelt, einen KI-Agenten, der seinen eigenen Code analysiert, umschreibt und dadurch seine Fähigkeiten autonom verbessert. In einem wegweisenden Experiment steigerte der Agent seine Erfolgsquote bei komplexen Programmieraufgaben von 17 % auf 53 % – ein Sprung von über 300 %. Dieser Durchbruch könnte die Art und Weise, wie wir KI-Systeme entwickeln, revolutionieren und ist ein entscheidender Schritt in Richtung autonomer, sich selbst optimierender künstlicher Intelligenz.
Stell Dir einen Softwareentwickler vor, der nach jedem abgeschlossenen Projekt nicht nur Erfahrung sammelt, sondern seine eigene Arbeitsweise – sein Gehirn und seine Werkzeuge – aktiv umprogrammiert, um beim nächsten Mal schneller, effizienter und fehlerfreier zu sein. Genau das realisiert der „Self-Improving Coding Agent“ (SICA). Anstatt auf manuelle Verbesserungen durch menschliche Entwickler zu warten, tritt SICA in einen Kreislauf aus Testen, Reflektieren und Selbstmodifikation ein.
In diesem Artikel tauchen wir tief in die Architektur dieses faszinierenden Systems ein. Wir analysieren die bahnbrechenden Ergebnisse, erklären den dreistufigen Prozess der Selbstverbesserung und beleuchten, warum dieser Ansatz die Grenzen heutiger KI-Systeme sprengt, aber auch vor neuen Herausforderungen steht.
Das Wichtigste in Kürze: SICA im Überblick
- Autonome Selbstverbesserung: SICA ist ein KI-System, das seinen eigenen Python-Code analysieren und modifizieren kann, um seine Leistung bei Programmieraufgaben zu steigern.
- Messbarer Leistungssprung: Auf einem anspruchsvollen Benchmark für Software-Engineering (SWE-Bench Verified) verbesserte sich SICA von einer anfänglichen Erfolgsquote von 17 % auf 53 %.
- Kein Meta-Agent mehr: Im Gegensatz zu früheren Ansätzen wie ADAS (Automated Design of Agentic Systems) gibt es bei SICA keine Trennung mehr zwischen einem „Ziel-Agenten“, der die Aufgabe löst, und einem „Meta-Agenten“, der ihn verbessert. SICA ist beides in einem.
- Effizienz als Ziel: Der Agent optimiert sich nicht nur auf die reine Lösungsquote, sondern auch auf Geschwindigkeit und Kosten, gemessen in Rechenzeit und API-Aufrufen.
- „Overseer“ zur Überwachung: Ein asynchroner, KI-basierter „Aufseher“ überwacht den Agenten, um Endlosschleifen oder pathologisches Verhalten zu erkennen und notfalls einzugreifen.
- Open Source: Die Forscher haben den Code von SICA der Community zur Verfügung gestellt, um die weitere Entwicklung zu beschleunigen.
Von 17 % auf 53 %: Die beeindruckende Lernkurve von SICA in Zahlen
Die wahre Innovationskraft von SICA zeigt sich in den messbaren Ergebnissen. Über 15 Iterationen der Selbstverbesserung hinweg hat der Agent seine Fähigkeiten signifikant ausgebaut. Die Forscher der University of Bristol und von iGent AI testeten dies auf einer Reihe von Benchmarks.
Besonders eindrucksvoll ist die Entwicklung auf einer zufälligen Auswahl von 50 Aufgaben aus dem SWE-Bench Verified, einem Benchmark, der reale Probleme aus GitHub-Projekten simuliert. Hier kletterte die Erfolgsquote von anfänglich schwachen 17 % auf beachtliche 53 %. Gleichzeitig sanken die durchschnittliche Bearbeitungszeit und die Kosten pro Aufgabe.
Wie hat SICA das geschafft? Der Agent begann mit einer einfachen Fähigkeit: Er konnte Dateien nur komplett überschreiben, was langsam und ineffizient war. In den ersten Iterationen erkannte er dieses Defizit und entwickelte selbstständig neue, „smarte“ Werkzeuge:
- „Smart Edit“ Tool: Eine Funktion, die auf Basis von Diffs und Code-Bereichen arbeitet, anstatt ganze Dateien auszutauschen.
- AST Symbol Locator: Ein Werkzeug, das den Abstract Syntax Tree (AST) von Code analysiert, um Definitionen und Referenzen von Funktionen oder Variablen präzise zu finden – ein Quantensprung für die Navigation in fremden Codebasen.
- Code Context Summarizer: Ein Tool, das relevanten Code-Kontext effizient zusammenfasst, um die Arbeitsgrundlage des Agenten zu verbessern, ohne das Kontextfenster des Sprachmodells zu überlasten.
Diese selbst entwickelten Werkzeuge machten den Agenten nicht nur bei der Code-Bearbeitung, sondern auch bei der Code-Navigation und -analyse schrittweise immer kompetenter.
Detaillierte Leistungsentwicklungvon SICA: Iteration für Iteration
Die folgende Tabelle aus der Originalstudie zeigt die detaillierte Leistungsentwicklung von SICA über 15 Iterationen auf vier verschiedenen Benchmarks. Man erkennt deutlich, wie die Erfolgsquote im SWE-Bench (Spalte „SWE-Bv“) von 0.17 (17 %) auf 0.53 (53 %) ansteigt, während gleichzeitig die durchschnittliche Zeit und die Kosten pro Aufgabe tendenziell sinken.
| Iteration | File Edit | Symbol Loc. | SWE-Bench Verified | LiveCodeBench | Ø Kosten ($) | Ø Zeit (s) | Ø Tokens (Mio.) |
| 0 | 0.82 | 0.35 | 0.17 | 0.65 | 1.91 | 130.2 | 0.24 |
| 1 | 0.87 | 0.32 | 0.14 | 0.62 | 1.71 | 123.8 | 0.24 |
| 2 | 0.92 | 0.31 | 0.17 | 0.58 | 2.45 | 151.4 | 0.26 |
| 3 | 0.82 | 0.33 | 0.22 | 0.64 | 1.84 | 126.9 | 0.29 |
| 4 | 0.88 | 0.31 | 0.38 | 0.54 | 2.70 | 148.3 | 0.26 |
| 5 | 0.89 | 0.31 | 0.30 | 0.59 | 2.17 | 134.8 | 0.23 |
| 6 | 0.96 | 0.31 | 0.37 | 0.64 | 2.21 | 134.1 | 0.25 |
| 7 | 0.92 | 0.35 | 0.33 | 0.58 | 2.15 | 134.9 | 0.23 |
| 8 | 0.93 | 0.33 | 0.27 | 0.64 | 2.03 | 128.5 | 0.26 |
| 9 | 0.88 | 0.40 | 0.47 | 0.61 | 2.03 | 126.3 | 0.27 |
| 10 | 0.87 | 0.41 | 0.46 | 0.66 | 1.77 | 107.0 | 0.22 |
| 11 | 0.89 | 0.43 | 0.44 | 0.70 | 2.25 | 129.6 | 0.27 |
| 12 | 0.91 | 0.38 | 0.44 | 0.64 | 1.58 | 103.9 | 0.26 |
| 13 | 0.86 | 0.40 | 0.27 | 0.61 | 1.66 | 113.3 | 0.29 |
| 14 | 0.94 | 0.34 | 0.53 | 0.67 | 2.20 | 117.1 | 0.25 |
| 15 | 0.91 | 0.40 | 0.51 | 0.71 | 1.70 | 114.5 | 0.30 |
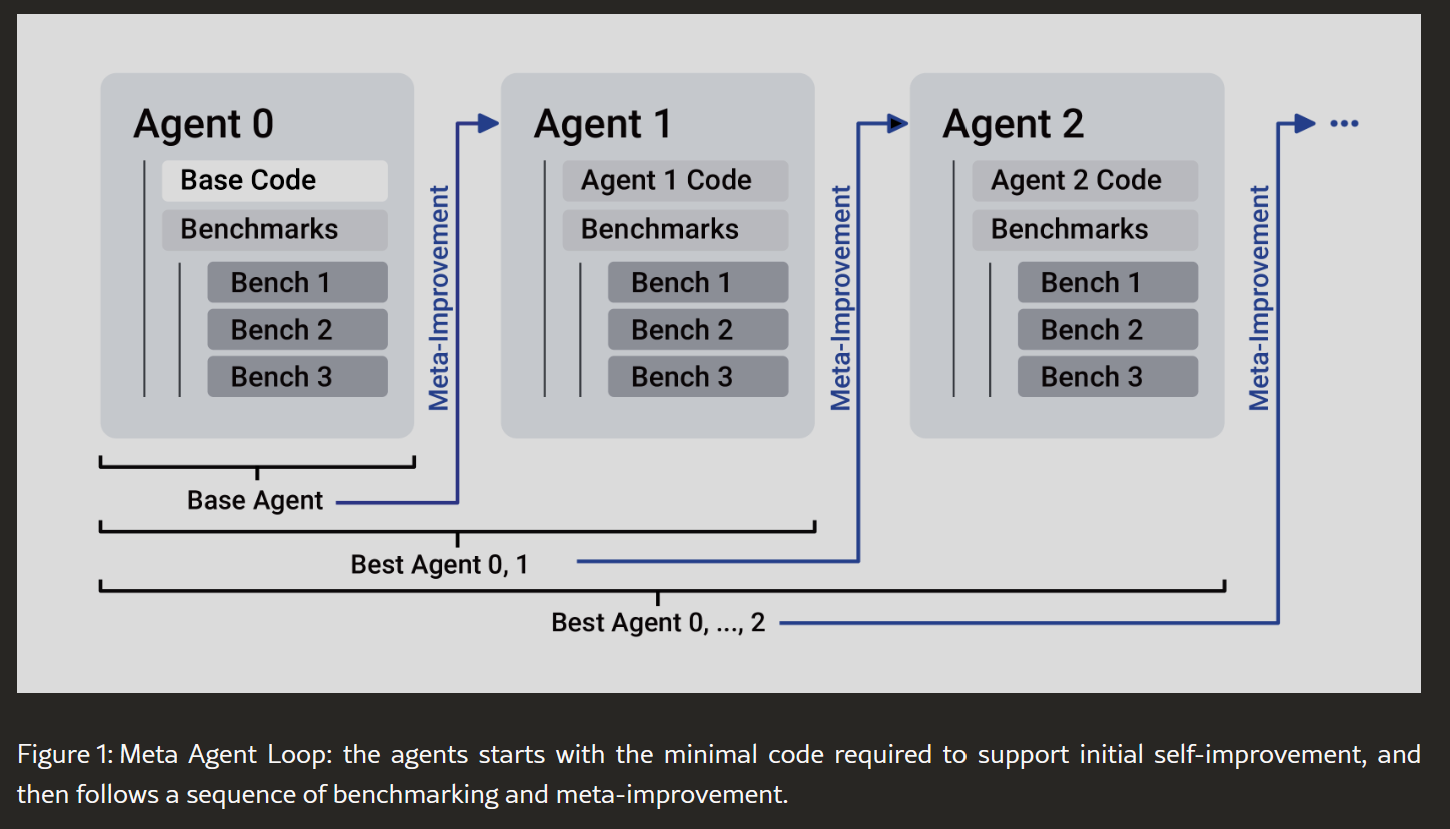
So funktioniert die Selbstverbesserung: Der Meta-Improvement-Loop erklärt
SICAs Lernprozess ist kein Mysterium, sondern ein strukturierter, dreistufiger Kreislauf, der dem Vorgehen eines datengetriebenen menschlichen Entwicklers ähnelt.
Schritt 1: Benchmark (Leistung messen)
Zunächst wird die aktuelle Version des Agenten (z. B. Agent 1) auf einem Set von vordefinierten Aufgaben (Benchmarks) getestet. Seine Leistung wird anhand einer
Utility-Funktion bewertet, die drei Kernmetriken berücksichtigt:
- Erfolgsquote (p_score): Wie viele Aufgaben wurden korrekt gelöst?
- Kosten (p_cost): Wie viele Dollar an API-Gebühren wurden verbraucht?
- Zeit (p_time): Wie lange hat die Bearbeitung gedauert?
Die Ergebnisse aller bisherigen Agenten-Versionen werden in einem Archiv gespeichert.
Schritt 2: Analyse & Reflexion (Archiv auswerten)
Nun erhält der beste bisherige Agent eine neue Aufgabe: sich selbst zu verbessern. Dazu analysiert er das Archiv mit den Leistungsergebnissen. Er identifiziert, bei welchen Aufgaben er gut oder schlecht abgeschnitten hat, wo er zu langsam war oder zu viele Ressourcen verbraucht hat. Wie ein menschlicher Entwickler, der seine Git-Historie und Bug-Reports durchgeht, sucht der Agent nach Mustern und Verbesserungspotenzial.
Schritt 3: Code-Modifikation (Sich selbst umprogrammieren)
Basierend auf seiner Analyse entwickelt der Agent eine Hypothese für eine Verbesserung. Das kann die Entwicklung eines neuen Tools, die Optimierung eines bestehenden Prompts oder die Anpassung seiner internen Logik sein. Anschließend öffnet er seinen eigenen Quellcode, schreibt die notwendigen Änderungen, implementiert eventuell eigene Testfälle und speichert die neue Version als „Agent 2“ ab. Danach beginnt der Kreislauf von vorn mit Schritt 1.
SICA vs. ADAS: Der entscheidende Unterschied
Die Idee, KI-Systeme automatisch zu optimieren, ist nicht völlig neu. Ein kürzlich vorgestellter Ansatz ist ADAS (Automated Design of Agentic Systems). ADAS verwendet jedoch zwei getrennte Agenten: einen
Ziel-Agenten, der die Aufgabe löst, und einen fixen Meta-Agenten, der den Ziel-Agenten verbessert.
SICA eliminiert diese Trennung. Es gibt nur einen Agenten, der seine Rolle wechselt. Der beste Agent aus dem Archiv wird zur Laufzeit zum Meta-Agenten, um die nächste Generation zu erschaffen. Dies ist ein fundamentaler Schritt, denn theoretisch können Verbesserungen an den Programmierfähigkeiten direkt auf die Fähigkeit zur Selbstverbesserung zurückwirken – ein potenziell sich selbst verstärkender Effekt.
Die Grenzen der Selbstverbesserung: Code vs. reines Denken
Ein weiteres spannendes Ergebnis der Studie war die Beobachtung, dass SICA vor allem bei praktischen, werkzeuggestützten Aufgaben wie dem Programmieren glänzt. Die Forscher führten ein zweites Experiment mit reinen Denk- und Logikaufgaben durch (AIME 2024, GPQA Diamond).
Hier waren die Verbesserungen marginal. Oft delegierte der SICA-Agent die Aufgabe einfach an ein leistungsfähiges Basis-Sprachmodell (wie o3-mini von OpenAI) und nutzte sein eigenes komplexes Framework kaum. Die Forscher vermuten, dass die von SICA hinzugefügten „Denkgerüste“ den hochentwickelten, internen Denkprozess eines spezialisierten Logik-Modells eher störten als unterstützten. Dies deutet darauf hin, dass die Architektur des Agenten und das Basis-LLM optimal aufeinander abgestimmt sein müssen.
Die Zukunft ist „jointly trained“: Was nach SICA kommt
Die Arbeit an SICA ist ein Beweis dafür, dass eine nicht-gradientenbasierte Form des Lernens – also Lernen durch Code-Anpassung statt durch Gewichtsaktualisierungen im neuronalen Netz – extrem dateneffizient sein kann. Jeder Zyklus führt zu substanziellen, überlegten Änderungen.
Die Forscher sehen die Zukunft jedoch in einer Kombination beider Welten: einem System, bei dem nicht nur der Code des Agenten-Frameworks, sondern auch die Gewichte des zugrundeliegenden Sprachmodells gemeinsam trainiert und optimiert werden. Ein solcher Ansatz, wie er auch in Projekten wie AlphaEvolve angedeutet wird, könnte sicherstellen, dass das Sprachmodell neue, vom Agenten entwickelte Werkzeuge nativ versteht und optimal nutzt.
Die Kosten der Evolution: Ein $7.000-Experiment
Fortschritt in der KI-Forschung hat seinen Preis. Das hier beschriebene Experiment mit 15 Iterationen kostete die Forscher rund 7.000 US-Dollar an API-Gebühren für die verwendeten Sprachmodelle (hauptsächlich Anthropic’s Sonnet 3.5). Diese Zahl verdeutlicht den enormen Rechenaufwand, der für die Entwicklung und das Benchmarking solch komplexer autonomer Systeme erforderlich ist.
Häufig gestellte Fragen zu SICA
1. Wie unterscheidet sich SICA von anderen KI-Agenten? Der Hauptunterschied ist die Fähigkeit zur echten Selbstmodifikation. Während andere Agenten vordefinierte Werkzeuge nutzen, kann SICA seinen eigenen Code ändern und neue Werkzeuge für sich selbst erstellen, um besser zu werden. Es eliminiert die Trennung zwischen einem ausführenden Agenten und einem verbessernden Meta-Agenten.
2. Ist der SICA-Code Open Source? Ja, die Forscher haben den Code auf GitHub veröffentlicht, um Transparenz zu schaffen und die weitere Forschung in der Community zu ermöglichen.
3. Welche KI-Modelle wurden für SICA verwendet? Das System nutzte hauptsächlich Sonnet 3.5 (v2) von Anthropic für die meisten Agentenfunktionen. Für spezialisierte Logik- und Denkaufgaben wurde zusätzlich
o3 mini von OpenAI eingesetzt.
4. Was ist der „asynchrone Overseer“? Der Overseer ist ein separates LLM, das den Hauptagenten in regelmäßigen Abständen (z.B. alle 30 Sekunden) überwacht. Es prüft auf Endlosschleifen, Abweichungen von der Aufgabe oder andere Probleme und kann den Agenten benachrichtigen oder im Extremfall sogar abbrechen. Er dient als wichtiges Sicherheits- und Effizienz-Feature.
5. Kann SICA auch bei Denk- und Logikaufgaben besser werden? Bisher nur sehr begrenzt. Die Studie zeigte, dass die Verbesserungen bei reinen Logikaufgaben, wo spezialisierte LLMs bereits sehr gut sind, marginal waren. Das Framework schien die Leistung dieser Modelle eher zu behindern als zu fördern.
6. Ist ein sich selbst verbessernder KI-Agent nicht gefährlich? Die Forscher haben dieses Risiko bedacht. SICA arbeitet in einer kontrollierten Umgebung und ohne die Fähigkeit, die Gewichte des Basis-LLMs zu ändern, was das Risiko begrenzt. Zudem sorgen Mechanismen wie der Overseer und die iterative, benchmark-basierte Überprüfung für menschliche Kontrolle und Beobachtbarkeit, die als entscheidende Sicherheitsmaßnahmen gelten.
7. Wie hoch waren die Kosten für das Experiment? Der 15-Iterationen-Lauf des Experiments kostete etwa 7.000 US-Dollar an API-Gebühren für die genutzten Cloud-LLMs.
Fazit SICA: Ein Meilenstein mit klarem Auftrag
SICA ist mehr als nur ein weiteres KI-Experiment. Es ist ein fundamentaler Beweis dafür, dass KI-Systeme in der Lage sind, sich durch eigenständige Programmierung rekursiv selbst zu verbessern. Der Leistungssprung von 17 % auf 53 % im SWE-Bench ist nicht nur eine beeindruckende Zahl, sondern das Ergebnis eines intelligenten, selbstgesteuerten Prozesses der Werkzeugentwicklung und Optimierung.
Die Studie zeigt aber auch klar die aktuellen Grenzen auf: Der Erfolg hängt stark von der Art der Aufgabe ab. Während die Methode für „agentische“ Aufgaben wie das Programmieren prädestiniert ist, stößt sie bei reinen Logikproblemen, bei denen hochspezialisierte LLMs bereits brillieren, an ihre Grenzen.
Die entscheidende nächste Hürde wird sein, das Agenten-Framework und das Sprachmodell nicht mehr als getrennte Einheiten zu betrachten, sondern sie als ein einziges, symbiotisches System zu trainieren. SICA hat die Tür zu dieser Zukunft weit aufgestoßen. Es ist nun an der KI-Forschungsgemeinschaft, hindurchzugehen.
Quellen und weiterführende Literatur
- Originalstudie: Robeyns, M., Aitchison, L., & Szummer, M. (2025). A Self-Improving Coding Agent. arXiv:2504.15228v2. Verfügbar unter: https://arxiv.org/abs/2504.15228






