
Google Deepmind hat ein extrem krasses Paper veröffentlicht: On the Theoretical Limitations of Embedding-Based Retrieval: Stell dir vor, du investierst Millionen in die fortschrittlichste KI-Suchtechnologie für dein Unternehmen, nur um festzustellen, dass sie eine fundamentale, unüberwindbare Schwäche hat. Eine neue, bahnbrechende Studie von Google DeepMind deckt genau das auf: Die Vektor-Embedding-Modelle, das Herzstück moderner RAG-Systeme und semantischer Suchen, stoßen an eine theoretische Grenze, die weder durch größere Modelle noch durch mehr Trainingsdaten beseitigt werden kann. Eine schockierende Erkenntnis, die die Grundfesten der aktuellen KI-Architektur erschüttert.
Diese Enthüllung ist mehr als nur eine akademische Fußnote; sie ist ein Weckruf für jeden Entwickler, Produktmanager und CIO, der auf KI-gestützte Suche setzt. Das Paper „On the Theoretical Limitations of Embedding-Based Retrieval“ beweist mathematisch, dass selbst die besten Modelle bei bestimmten, oft sehr einfachen Anfragen systematisch versagen müssen. Es zeigt, dass wir eine unsichtbare Mauer erreicht haben, die uns zwingt, die Architektur unserer intelligenten Systeme von Grund auf neu zu denken.
In diesem Artikel schauen wir uns die Ergebnisse von Google DeepMind an. Du erfährst nicht nur, warum deine Vektorsuche möglicherweise schlechter funktioniert als erwartet, sondern auch, wie du die Schwachstellen in deinem eigenen System identifizieren kannst. Wir präsentieren die Alternativen, die diese Grenzen überwinden können, und geben dir eine klare Roadmap für die Zukunft der intelligenten Informationssuche.
Google DeepMind steht bisher immer für revolutionäre Erkenntnissse: Jüngstes Beispiel AlphaEvolve.
Google Deepmind Vektor-Embeddings: Das Wichtigste in Kürze
- Fundamentales Limit: Google DeepMind beweist, dass die Anzahl der Dokumentenkombinationen, die ein Vektor-Modell finden kann, durch seine Embedding-Dimension mathematisch begrenzt ist (via „Sign-Rank“).
- Größer ist nicht besser: Das Problem lässt sich nicht einfach durch Skalierung von Modellen oder Daten lösen. Es ist eine inhärente Einschränkung der Single-Vector-Architektur.
- LIMIT-Dataset enthüllt Schwäche: Ein extrem einfacher Test („Wer mag Äpfel?“) brachte selbst Top-Modelle wie Gemini und E5-Mistral zum Scheitern, mit einer Genauigkeit von unter 20%.
- Alte Schule schlägt KI: Traditionelle Methoden wie BM25 (eine Form der Keyword-Suche) und modernere Multi-Vektor-Modelle übertreffen auf diesem speziellen Testfeld die neuesten Embedding-Modelle deutlich.
- RAG-Systeme in Gefahr: Viele Retrieval-Augmented Generation (RAG) Systeme, die auf reiner Vektorsuche basieren, erben diese Schwäche, was zu unzuverlässigen oder falschen Ergebnissen führen kann.
- Zukunft ist Hybrid: Die Lösung liegt in hybriden Architekturen, die die Stärken von dichten (Vektor) und dünnbesetzten (Sparse) Modellen wie BM25 kombinieren.
- Praktische Implikationen: Unternehmen müssen ihre Such-Architekturen überdenken, insbesondere wenn sie auf komplexe, logikbasierte oder instruktionsfolgende Anfragen angewiesen sind.
Deep-Dive: Der wahre Feind der Vektor-Suche – der „Sign-Rank“
Um das Problem zu verstehen, müssen wir kurz in die Mathematik hinter den Kulissen blicken. Vektor-Embeddings funktionieren, indem sie die Bedeutung von Wörtern, Sätzen oder ganzen Dokumenten in einen mehrdimensionalen Raum übersetzen. Ein Dokument wird zu einem Vektor (einer Liste von Zahlen), und die Ähnlichkeit zwischen Dokumenten wird durch den Abstand oder Winkel zwischen diesen Vektoren gemessen.
Die Google-Forscher zeigen nun, dass die Fähigkeit eines Modells, jede mögliche Gruppe von relevanten Dokumenten für jede mögliche Anfrage korrekt zurückzugeben, von einer Eigenschaft namens Sign-Rank der Relevanzmatrix abhängt.
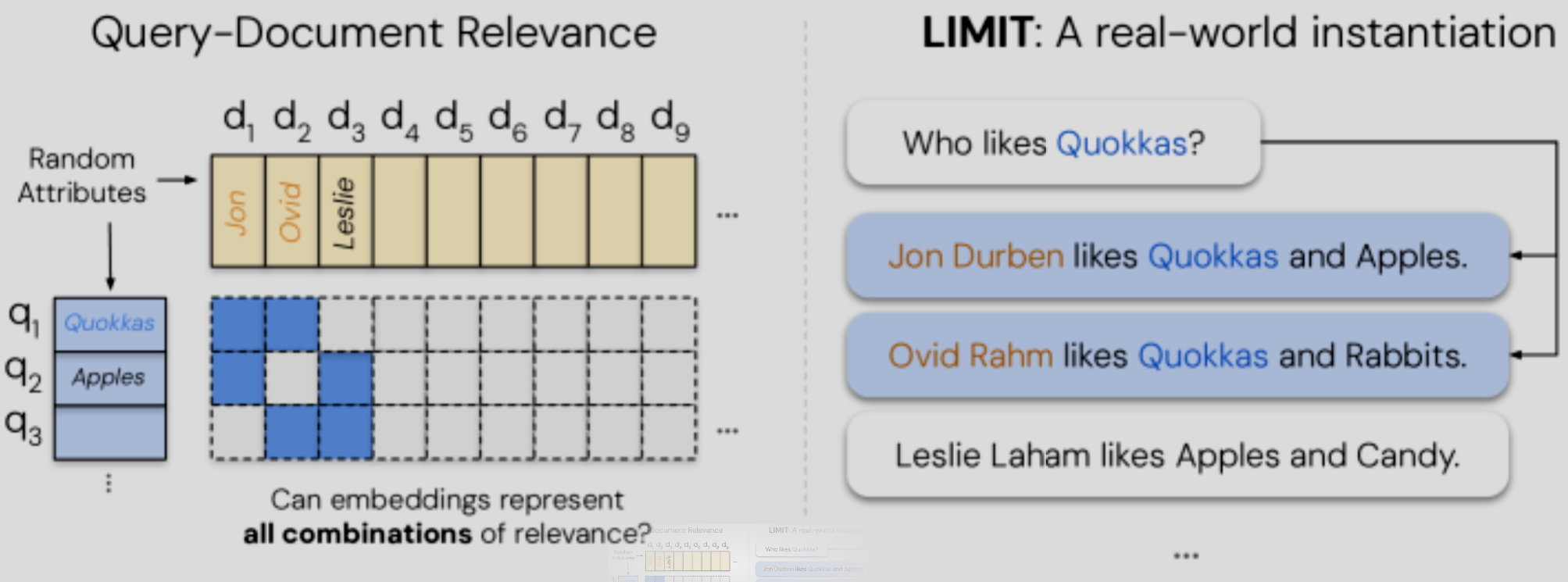
Stell es dir vereinfacht so vor: Du hast eine riesige Tabelle, in der jede Zeile eine mögliche Nutzeranfrage ist und jede Spalte ein Dokument. Eine „1“ bedeutet „relevant“, eine „0“ bedeutet „irrelevant“. Der Sign-Rank ist ein Maß für die Komplexität dieser Tabelle. Die Studie beweist:
rank±(2A−1m×n)−1≤rankrop(A)
- A ist die binäre Relevanzmatrix.
- textrank_textrop(A) ist die minimal benötigte Embedding-Dimension, um alle relevanten Dokumente korrekt zu ordnen.
- textrank_pm ist der Sign-Rank.
Die Kernaussage ist: Die benötigte Embedding-Dimension wächst mit der kombinatorischen Komplexität der Anfragen. Da die Anzahl möglicher Dokumentenkombinationen astronomisch hoch ist, gibt es immer eine Relevanz-Matrix, deren Sign-Rank höher ist als die Dimension deines Embedding-Modells. An diesem Punkt kann das Modell die Aufgabe physikalisch nicht mehr lösen – egal, wie gut es trainiert ist.
Case Study: Das LIMIT-Dataset – Wie die einfachste Frage der Welt die besten KI-Modelle blamiert
Theorie ist das eine, aber die Praxis ist oft schockierender. Um ihre Thesen zu untermauern, entwickelten die Forscher das LIMIT-Dataset.6 Die Aufgabe ist trivial einfach:
- Dokumente: Tausende fiktive Personenprofile, in denen steht, was sie mögen (z.B. „Jonas mag Ananas-Pizza, Sportwagen und Science-Fiction-Filme.“).
- Anfragen: Einfache Fragen wie „Wer mag Ananas-Pizza?“.
Der Clou: Das Dataset wurde so konstruiert, dass es eine sehr hohe Anzahl an unterschiedlichen 2er-Kombinationen von Personen für die verschiedenen Vorlieben testet. Es maximiert also genau die kombinatorische Komplexität, die laut Theorie problematisch ist.
Die Ergebnisse waren verheerend:
- State-of-the-Art Modelle (Gemini, GritLM, E5-Mistral):7 Erreichten einen Recall@100 von unter 20%. Das bedeutet, selbst wenn man die Top 100 Ergebnisse durchsieht, findet man oft nicht beide relevanten Personen.
- BM25 (Sparse-Retrieval): Erreichte nahezu perfekte Ergebnisse.
- Multi-Vektor-Modelle (ColBERT): Deutlich besser als Single-Vector-Modelle, aber immer noch nicht perfekt.
Diese Case Study beweist: Sobald eine Aufgabe eine hohe kombinatorische Vielfalt erfordert, bricht die Leistung der weitverbreiteten Single-Vector-Embedding-Modelle dramatisch ein.8
Single-Vector vs. Alternativen: Der ultimative Vergleich
Die Studie zwingt uns, über den Tellerrand der reinen Vektorsuche hinauszuschauen. Jede Architektur hat ihre spezifischen Stärken und Schwächen, besonders im Hinblick auf dieses neu entdeckte Limit.
| Eigenschaft | Single-Vector-Embedding | Multi-Vector (z.B. ColBERT) | Sparse (z.B. BM25) | Cross-Encoder (Reranker) |
| Grundprinzip | Ein Vektor pro Dokument | Mehrere Vektoren pro Dokument | Vektor pro Wort (hohe Dimension) | Bewertet Paar (Anfrage, Dokument) |
| Geschwindigkeit | Sehr schnell | Mittel | Schnell | Sehr langsam |
| Kosten (Inferenz) | Sehr niedrig | Mittel | Niedrig | Sehr hoch |
| Semantisches Verständnis | Hoch | Hoch | Niedrig (Keyword-basiert) | Sehr hoch |
| Robustheit bei Kombinationen | Sehr niedrig (Kernproblem) | Mittel bis hoch | Sehr hoch | Sehr hoch |
| Ideal für… | Schnelle, semantische Erstfilterung | Detaillierte semantische Suche | Keyword-Suche, exakte Treffer | Finale Neusortierung (Reranking) |
Practical Implementation: Ist Dein RAG-System betroffen? Ein 5-Schritte-Check
Du musst kein Google-Forscher sein, um die Auswirkungen auf dein System zu prüfen. Folge diesem konzeptionellen Leitfaden, um potenzielle Schwachstellen aufzudecken:
- Identifiziere kombinatorische Anfragen: Welche Anfragen in deinem System erfordern die Verknüpfung von Dokumenten, die semantisch nicht unbedingt nahe beieinander liegen? Beispiele: „Finde alle Berichte von Analyst A über Firma X und alle internen Memos von Team B zum selben Thema.“
- Erstelle ein Mini-Testset (A „Mini-LIMIT“): Definiere eine kleine Gruppe von 10-20 Dokumenten. Formuliere nun 15-20 Anfragen, die alle möglichen 2er- oder 3er-Kombinationen dieser Dokumente als korrektes Ergebnis haben sollten.
- Führe den Test durch: Lass dein reines Vektor-Retrieval-System auf diesem Mini-Testset laufen. Miss den Recall: Wie oft werden alle korrekten Dokumente gefunden?
- Vergleiche mit einer Baseline: Führe denselben Test mit einem einfachen BM25- oder Keyword-basierten System durch. Elasticsearch oder OpenSearch bieten dies standardmäßig.
- Analysiere die Lücke: Wenn deine Vektorsuche hier signifikant schlechter abschneidet als die Keyword-Suche (obwohl die Dokumente die Keywords enthalten), ist dein System wahrscheinlich von der theoretischen Limitierung betroffen.
Die 5 häufigsten Fehler bei RAG-Systemen im Licht dieser Studie
Diese Forschung wirft ein neues Licht auf gängige Probleme in RAG-Implementierungen. Hier sind Fehler, die durch dieses fundamentale Limit noch verschlimmert werden:
- Blinder Glaube an die reine Vektorsuche: Sich ausschließlich auf ein Vektor-Retrieval zu verlassen, ist die größte Gefahr.
- Top-k ist zu klein: Ein zu niedriges
k(z.B. nur die Top-3-Dokumente abrufen) kann dazu führen, dass relevante Dokumente, die das Modell nur schwer kombinieren kann, gar nicht erst an den LLM weitergegeben werden. - Vernachlässigung von Metadaten/Keywords: Viele Teams ignorieren strukturierte Daten oder Keywords, weil sie glauben, die semantische Suche löse alles. Die Studie beweist das Gegenteil.
- Fehlende Reranking-Stufe: Ohne einen Cross-Encoder als zweite Stufe zur Neusortierung der Ergebnisse werden die vom Vektor-Retriever falsch priorisierten Dokumente direkt an den Nutzer oder LLM durchgereicht.
- Unzureichende Evaluation: Testen nur auf „glücklichen Pfaden“ oder Standard-Benchmarks, ohne die kombinatorische Komplexität gezielt zu stress-testen.
Die Zukunft der Suche: Hybride Systeme und die nächste Generation von KI-Retrievern
Die Schlussfolgerung ist nicht, dass Vektor-Embeddings nutzlos sind. Im Gegenteil, ihr semantisches Verständnis ist unersetzlich. Die Zukunft liegt jedoch in einer intelligenteren Architektur, die die besten Eigenschaften verschiedener Welten vereint.
Hybride Suche (Hybrid Search) ist der Königsweg. Dieser Ansatz kombiniert:
- Sparse Retrieval (z.B. BM25): Perfekt für Keyword-Übereinstimmungen und die Abdeckung der kombinatorischen Vielfalt.
- Dense Retrieval (Vektor-Embeddings): Unschlagbar im Verständnis von Kontext, Synonymen und semantischer Bedeutung.
Moderne Suchsysteme wie Elasticsearch 8+ oder spezialisierte Vektordatenbanken bieten bereits Funktionen, die Ergebnisse beider Methoden fusionieren (z.B. mittels Reciprocal Rank Fusion, RRF), um eine weitaus robustere und genauere Trefferliste zu erzeugen. Dies ist der pragmatische und empfohlene nächste Schritt für fast jedes RAG-System.
Häufig gestellte Fragen zu den Grenzen der Vektor-Suche
1. Kann man dieses Problem nicht einfach mit größeren Modellen und mehr Dimensionen lösen?
Nein, nicht wirklich. Die Studie zeigt, dass die Anzahl der benötigten Dimensionen mit der Anzahl der Dokumente und der Komplexität der Anfragen extrem schnell wächst. Für eine web-skalierte Suche wären Millionen von Dimensionen erforderlich, was praktisch nicht umsetzbar ist. Das Problem ist fundamentaler Natur.
2. Bedeutet das, meine Vektordatenbank ist jetzt nutzlos?
Absolut nicht. Vektordatenbanken sind extrem effizient für die semantische Ähnlichkeitssuche. Die Erkenntnis ist, dass sie nicht die alleinige Lösung für alle Retrieval-Probleme sind. Die beste Strategie ist, sie als Teil eines hybriden Systems zu nutzen.
3. Was genau ist BM25 und warum ist es hier besser?
BM25 ist ein bewährter Algorithmus aus der „alten“ Welt der Information Retrieval. Er bewertet Dokumente basierend auf der Häufigkeit von Suchbegriffen (TF-IDF), berücksichtigt aber auch die Dokumentenlänge. Da er quasi jedes Wort als eigene „Dimension“ betrachtet, hat er eine extrem hohe implizite Dimensionalität und kann daher mühelos jede beliebige Keyword-Kombination finden, was ihn auf dem LIMIT-Dataset so stark macht.
4. Ist mein Chatbot oder mein internes RAG-System davon betroffen?
Sehr wahrscheinlich, ja. Wenn dein System Anfragen beantworten muss, die Fakten aus mehreren, thematisch unterschiedlichen Dokumenten kombinieren müssen, läufst du Gefahr, in diese Falle zu tappen. Die Relevanz der einzelnen Dokumente mag hoch sein, aber das Modell scheitert daran, sie gemeinsam als Top-Ergebnis zu identifizieren.
5. Was ist die einfachste Lösung, die ich heute implementieren kann?
Die einfachste und effektivste Lösung ist die Implementierung einer hybriden Suche. Wenn dein Suchindex (z.B. Elasticsearch, OpenSearch) es unterstützt, aktiviere die Suche über sowohl Textfelder (mit BM25) als auch Vektorfelder und kombiniere die Ergebnisse mit einer Fusionstechnik wie RRF.
6. Warum haben Benchmarks wie BEIR oder MTEB dieses Problem nicht gezeigt?
Diese Benchmarks enthalten in der Regel nicht genügend Anfragen, die systematisch eine hohe kombinatorische Vielfalt über einen festen Dokumentensatz testen. Sie decken einen breiten, aber nicht tief genug gehenden Bereich von Anfragen ab, sodass diese spezifische Schwäche verborgen blieb.
7. Sind Multi-Vektor-Modelle wie ColBERT die Zukunft?
Sie sind ein vielversprechender Kompromiss. Sie sind ausdrucksstärker als Single-Vector-Modelle und können die kombinatorischen Hürden besser meistern. Allerdings sind sie rechenintensiver und komplexer in der Handhabung. Sie stellen eine starke Alternative dar, aber die hybride Suche aus Sparse und Dense ist oft einfacher zu implementieren.
Kosten, Skalierung, Risiko: Die Business-Perspektive auf die Such-Architektur
Die Wahl der richtigen Retrieval-Architektur ist keine rein technische Feinheit – sie ist eine fundamentale Geschäftsentscheidung mit direkten Auswirkungen auf Kosten, Skalierbarkeit und das unternehmerische Risiko. Die Erkenntnisse aus der Google-Studie erlauben es uns, eine klare Kosten-Nutzen-Analyse für die gängigsten Ansätze zu erstellen.
1. Die Kostenfalle des „einfachen“ Weges (Reine Vektor-Suche)
- Anfängliche Entwicklung: Der Reiz einer reinen Vektor-Lösung liegt in ihrer scheinbaren Einfachheit. Ein Embedding-Modell und eine Vektordatenbank sind schnell aufgesetzt.
- Versteckte Betriebskosten: Hochdimensionale Embeddings und große Datenmengen erfordern oft teure GPU-Ressourcen für die Inferenz, besonders bei hohem Suchaufkommen. Die Skalierung wird schnell zu einem signifikanten Kostenfaktor.
- Das größte Risiko (Opportunity Costs): Hier liegt die wahre Falle. Jede durch die kombinatorische Schwäche fehlgeschlagene Suche kann bedeuten:
- Ein Kunde findet ein Produkt nicht und kauft bei der Konkurrenz.
- Ein Mitarbeiter erhält unvollständige Informationen aus der Wissensdatenbank und trifft eine Fehlentscheidung.
- Ein RAG-System generiert eine mangelhafte oder falsche Antwort, was das Vertrauen in die KI untergräbt.
- Fazit: Der anfänglich günstigste Weg kann langfristig durch entgangene Chancen und Reputationsschäden der teuerste werden.
2. Die Investition in Robustheit (Hybride Suche)
- Höhere Anfangsinvestition: Die Implementierung einer hybriden Suche (z.B. BM25 + Vektor) erfordert mehr Know-how und Konfigurationsaufwand. Man muss zwei Systeme verstehen und deren Ergebnisse intelligent fusionieren (RRF).
- Effizientere Skalierung: BM25 läuft extrem effizient auf Standard-CPUs. Dies kann die teure GPU-Last für einen Großteil der Anfragen reduzieren, da viele Suchen bereits durch die Sparse-Komponente gut abgedeckt werden. Die Gesamtbetriebskosten (TCO) können dadurch auf lange Sicht sinken.
- Risikominimierung: Dies ist der entscheidende Vorteil. Durch die Abdeckung beider Paradigmen (lexikalisch und semantisch) wird das Risiko von „blinden Flecken“ im Retrieval drastisch reduziert. Die Zuverlässigkeit und das Vertrauen in das System steigen, was den ROI maximiert. Fazit: Eine höhere Anfangsinvestition in eine hybride Architektur amortisiert sich durch niedrigere Risikokosten und eine höhere Erfolgsquote.
3. Die „Königsklasse“ für maximale Präzision (Hybrid + Reranker)
- Maximale Kosten: Dieser Ansatz kombiniert die hybride Suche mit einem nachgeschalteten Cross-Encoder, der die Top-Ergebnisse neu sortiert. Cross-Encoder sind extrem rechenintensiv und treiben die Inferenzkosten und Latenz in die Höhe.
- Maximaler Nutzen: In Anwendungsfällen, wo Genauigkeit über allem steht (z.B. juristische Recherchen, medizinische Diagnostik, Compliance), ist dies die beste Wahl. Der Nutzen einer korrekten, präzisen Antwort übersteigt die hohen Betriebskosten bei weitem. Fazit: Nur für kritische Anwendungsfälle geeignet, bei denen die Kosten für einen Fehler die Betriebskosten des Systems um ein Vielfaches übersteigen.
Empfehlungsmatrix für Entscheider
| Ihr Ziel… | Empfohlene Architektur | Begründung |
| Schneller Prototyp / MVP | Reine Vektor-Suche | Schnellste Implementierung, um eine Idee zu validieren. (Sei dir der Limits bewusst!) |
| Robuste Enterprise-Suche / RAG | Hybride Suche (BM25 + Vektor) | Bester Kompromiss aus Kosten, Geschwindigkeit, Skalierbarkeit und Genauigkeit. Der De-facto-Standard für 2025+. |
| Mission-Critical-Anwendungen | Hybride Suche + Cross-Encoder | Wenn jeder Fehler extrem teuer ist und höchste Präzision erfordert wird. |
Die Wahl der Such-Architektur definiert somit direkt die Zuverlässigkeitsgrenzen und das Kostenprofil deiner KI-Anwendung. Ein strategisches Verständnis dieser Trade-Offs ist entscheidend, um Fehlinvestitionen zu vermeiden und den maximalen Wert aus deiner KI-Initiative zu ziehen.
Fazit: Ein Paradigmenwechsel für die KI-gestützte Suche
Die Studie von Google DeepMind ist kein Todesstoß für Vektor-Embeddings, sondern ein dringend benötigter Realitätscheck. Sie beendet die Ära des naiven Glaubens, dass ein einziges, elegantes Modell alle Probleme der Informationssuche lösen kann. Wir haben eine mathematisch beweisbare Grenze der Single-Vector-Architektur erreicht, und das Ignorieren dieser Tatsache führt unweigerlich zu fragilen und unzuverlässigen KI-Systemen.
Die praktische Implikation ist klar und unmissverständlich: Der Bau robuster RAG- und Suchsysteme im Jahr 2025 und darüber hinaus erfordert einen hybriden Ansatz. Die Kombination der rohen, kombinatorischen Stärke von Sparse-Retrieval-Methoden wie BM25 mit der feinen, semantischen Intelligenz von Vektor-Embeddings ist kein „Nice-to-have“ mehr, sondern eine strategische Notwendigkeit. Diejenigen, die ihre Architekturen jetzt anpassen, werden die zuverlässigeren, genaueren und letztendlich nützlicheren KI-Anwendungen der Zukunft bauen.
Der nächste Schritt für dich ist, deine eigene Retrieval-Pipeline kritisch zu hinterfragen. Führe Tests durch, die über einfache semantische Ähnlichkeit hinausgehen. Fordere dein System mit Anfragen, die komplexe Beziehungen und Kombinationen erfordern. Die „unsichtbare Mauer“ ist jetzt sichtbar gemacht worden – es liegt an uns, unsere Systeme so zu bauen, dass sie sie umgehen, anstatt frontal dagegen zu prallen.
Quellen und weiterführende Literatur
- Weller, O., Boratko, M., Naim, I., & Lee, J. (2025). On the Theoretical Limitations of Embedding-Based Retrieval. arXiv preprint arXiv:2508.21038.
- Robertson, S., & Zaragoza, H. (2009). The Probabilistic Relevance Framework: BM25 and Beyond.
- Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT.
- Reciprocal Rank Fusion (RRF) Explained.
- Thakur, N., et al. (2021). BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models.
#KI #AI #VektorSuche #Embeddings #GoogleDeepMind #RAG #KuenstlicheIntelligenz #Tech2025 #InformationRetrieval






