Hast du dich jemals gewundert, warum ein Sprachmodell unterschiedliche Antworten liefert, selbst wenn du die „Temperatur“ auf null stellst? Es ist ein bekanntes Problem in der KI-Entwicklung: Identische Eingaben führen zu unterschiedlichen Ausgaben, was der Idee der deterministischen Berechnung widerspricht. Lange Zeit wurde dies als unvermeidbare Folge von Fließkomma-Ungenauigkeiten bei massiv-parallelen GPU-Berechnungen angesehen. Eine detaillierte Forschungsarbeit von Thinking Machines Lab vom September 2025 widerlegt diese Annahme nun als unvollständig und identifiziert die eigentliche Ursache.
Dieser Artikel beleuchtet die Ergebnisse der Studie. Du wirst verstehen, warum die gängigen Erklärungen zu kurz greifen und was der wirkliche technische Grund ist: die fehlende „Batch-Invarianz“ von GPU-Operationen. Wir analysieren die von den Forschern vorgeschlagene Lösung, untersuchen ihre experimentellen Belege und erklären, welche weitreichenden Folgen dieser Durchbruch für die KI-Forschung, insbesondere für das Reinforcement Learning, hat.
Thinking Machine Labs und der LLM-Determinismus – Das Wichtigste in Kürze
- Das Kernproblem: LLM-Inferenz ist entgegen der Annahme auch bei
temperature=0(greedy sampling) oft nicht deterministisch. Das untergräbt die Reproduzierbarkeit von Ergebnissen. - Die wahre Ursache: Die Studie von Thinking Machines Lab zeigt, dass nicht die Fließkomma-Arithmetik allein, sondern die fehlende Batch-Invarianz der GPU-Kernel das Problem ist. Das Ergebnis deiner Anfrage wird von der Anzahl der gleichzeitig verarbeiteten Anfragen beeinflusst.
- Der Mechanismus: Die Auslastung eines Inferenz-Servers bestimmt die Größe des Verarbeitungs-Batches. Unterschiedliche Batch-Größen zwingen die GPU-Kernel, ihre interne Berechnungsreihenfolge zu ändern, was in Kombination mit Fließkomma-Ungenauigkeiten zu abweichenden Ergebnissen führt.
- Die Lösung: Die Forscher haben batch-invariante Kernel entwickelt. Diese stellen sicher, dass die Berechnung für eine einzelne Anfrage bitweise identisch abläuft, unabhängig von der Gesamt-Batch-Größe.
- Die Implikation: Echter Determinismus ermöglicht wahres On-Policy Reinforcement Learning (RL), da die numerischen Abweichungen zwischen der Datensammlungs- (Inferenz) und der Lernphase eliminiert werden.
- Praktische Umsetzung: Eine Open-Source-Bibliothek (
batch-invariant-ops) wird bereitgestellt, die sich in Frameworks wie vLLM integrieren lässt, um deterministische Inferenz zu realisieren. - Der Kompromiss: Die aktuelle Implementierung der deterministischen Methode führt zu einem Performance-Verlust. In den Tests der Forscher war sie etwa 1,6- bis 2,1-mal langsamer als die Standardkonfiguration.
Der Trugschluss des Zufalls: Warum temperature=0 nicht ausreicht
In der Theorie sollte die Einstellung temperature=0 in einem LLM für absolute Vorhersehbarkeit sorgen. Dieser „greedy sampling“-Modus weist das Modell an, bei jedem Schritt das Token mit der höchsten Wahrscheinlichkeit auszuwählen. In der Praxis beobachten Entwickler jedoch seit Langem, dass wiederholte, identische Anfragen an LLM-APIs oder lokale Inferenz-Engines wie vLLM unterschiedliche Ergebnisse liefern.
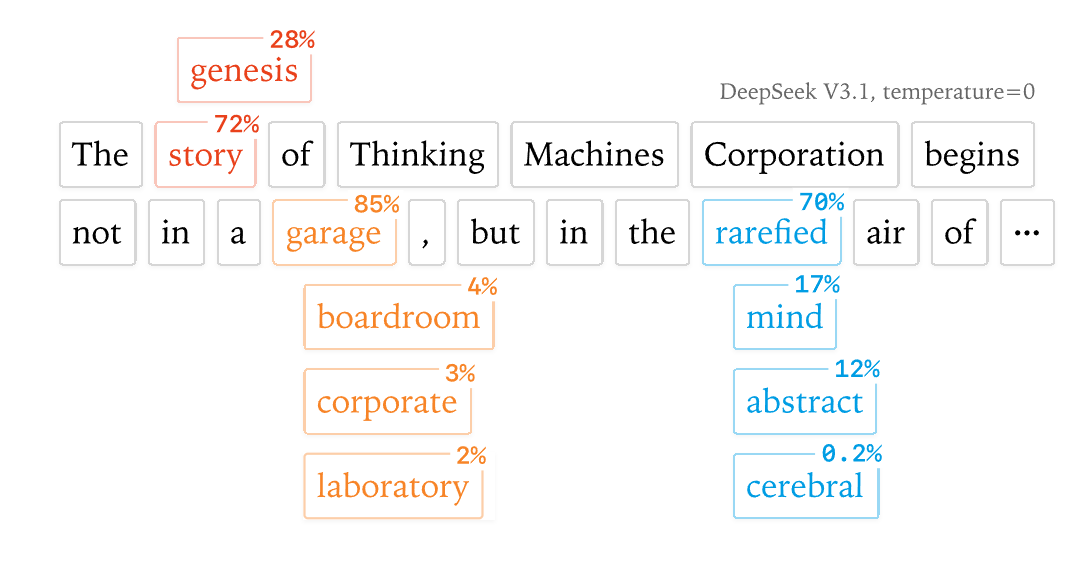
Die verbreitetste Erklärung dafür war die „Concurrency + Floating Point“-Hypothese. Sie besagt, dass die nicht-deterministische Reihenfolge, in der parallele GPU-Kerne ihre Berechnungen abschließen, in Verbindung mit der Nicht-Assoziativität von Fließkommazahlen ((a+b)+c ≠ a+(b+c)) zwangsläufig zu unterschiedlichen Endergebnissen führt.
Die Analyse von Thinking Machines Lab zeigt jedoch, dass diese Hypothese unvollständig ist. Ein einfaches Experiment in PyTorch demonstriert dies:
Python
# Führt eine Matrixmultiplikation 1000x aus
import torch
A = torch.randn(2048, 2048, device='cuda', dtype=torch.bfloat16)
B = torch.randn(2048, 2048, device='cuda', dtype=torch.bfloat16)
ref = torch.mm(A, B)
for _ in range(1000):
# Das Ergebnis ist bei jeder Ausführung bitweise identisch
assert (torch.mm(A, B) - ref).abs().max().item() == 0
Obwohl bei dieser Matrixmultiplikation Parallelität und Fließkommazahlen genutzt werden, ist das Ergebnis bei identischen Eingaben perfekt reproduzierbar. Der Nondeterminismus bei LLMs muss also eine andere, zusätzliche Ursache haben.
Die wahre Ursache aufgedeckt: Der Mechanismus der „Batch-Invarianz“
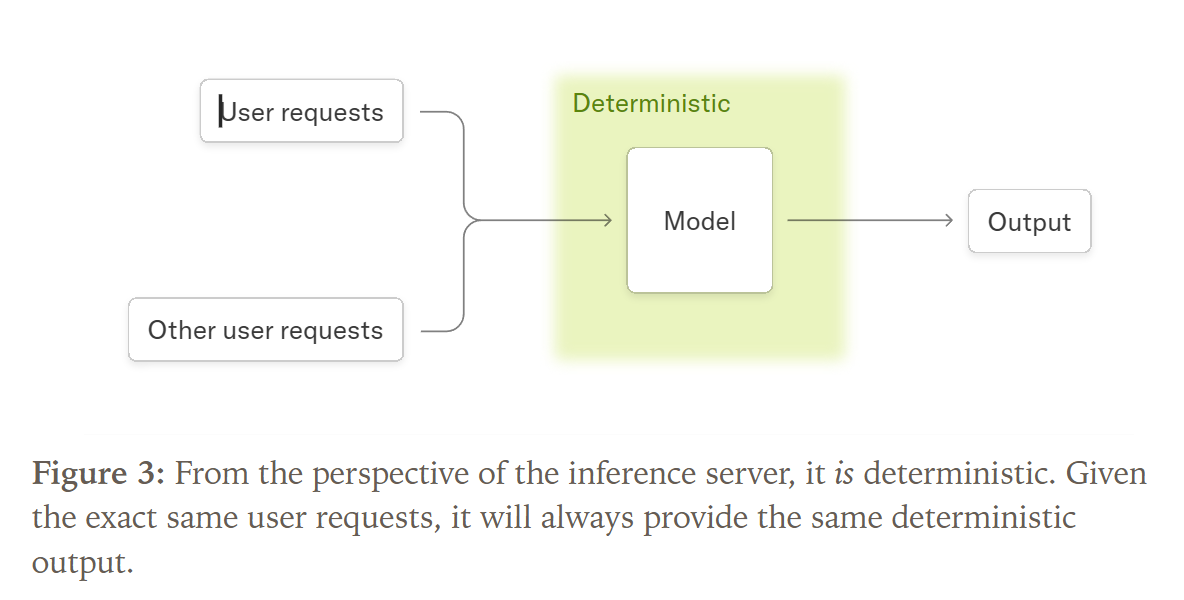
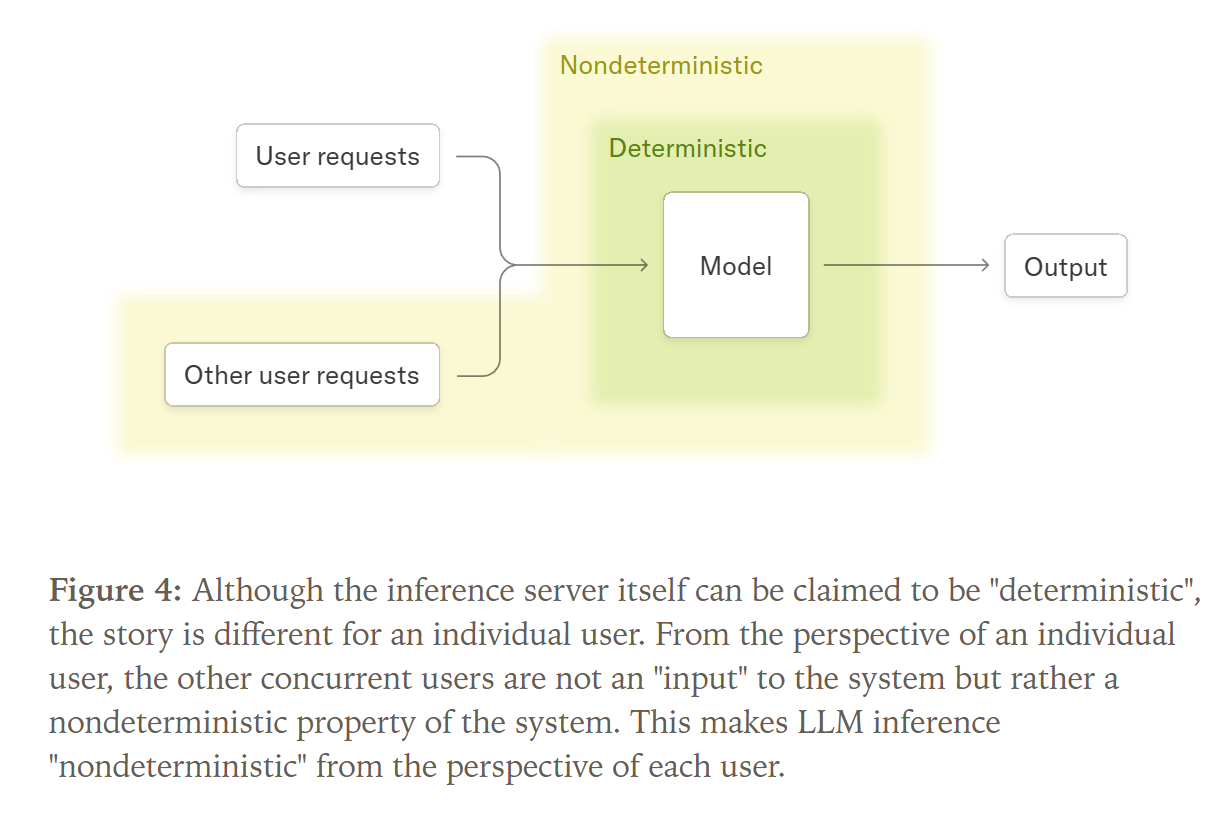
Die Forschung von Thinking Machines Lab identifiziert die dynamische Batch-Verarbeitung als den entscheidenden, bisher übersehenen Faktor. Um GPU-Ressourcen effizient zu nutzen, fassen Inferenz-Server wie vLLM deine Anfrage mit den Anfragen anderer Nutzer zu einem „Batch“ zusammen, der gemeinsam verarbeitet wird.
Die Größe dieses Batches ist aus der Perspektive deiner Anfrage unvorhersehbar und hängt von der aktuellen Serverauslastung ab. Hier kommt das Kernproblem ins Spiel: Die Standard-GPU-Kernel sind nicht batch-invariant.
Batch-Invarianz ist eine Eigenschaft, bei der das Berechnungsergebnis für einen einzelnen Datenpunkt (deine Anfrage) identisch bleibt, unabhängig davon, mit wie vielen anderen Datenpunkten er zusammen in einem Batch verarbeitet wird.
Stell dir vor, das Ergebnis von 2+2 auf deinem Taschenrechner würde sich ändern, je nachdem, ob 10 oder 100 andere Personen im Raum ebenfalls gerade rechnen. Genau dieses Verhalten zeigen viele GPU-Operationen. Die Forscher demonstrieren das empirisch:
Python
# Berechnung mit Batch-Größe 1
out1 = torch.mm(a[:1], b)
# Berechnung mit Batch-Größe 2048, danach das erste Element selektiert
out2 = torch.mm(a, b)[:1]
# Die Ergebnisse weichen voneinander ab!
print((out1 - out2).abs().max()) # tensor(1669.2500, device='cuda:0')
Der Nondeterminismus in LLM-Systemen entsteht also durch folgende Kausalkette:
- Variable Serverauslastung führt zu…
- Variabler Batch-Größe, was aufgrund von…
- Fehlender Batch-Invarianz der Kernel zu…
- Unterschiedlichen numerischen Ergebnissen für die exakt gleiche Anfrage führt.
Technischer Deep Dive: Die Implementierung deterministischer Kernel
Um vollständigen Determinismus zu erreichen, muss jede rechenintensive Operation innerhalb des Transformer-Modells batch-invariant gestaltet werden. Die Studie konzentriert sich auf die drei kritischsten Komponenten: RMSNorm, Matrixmultiplikation und Attention.
1. Batch-invariantes RMSNorm
Die RMS-Normalisierung ist eine Reduktionsoperation über die Hidden-Dimensionen.
- Standard-Ansatz: Bei großen Batches wird jede Sequenz einem GPU-Kern zugewiesen (Data-Parallel), was batch-invariant ist.
- Problem: Bei kleinen Batches wird die Berechnung für eine Sequenz auf mehrere Kerne aufgeteilt (Split-Reduction), um die GPU auszulasten. Dies ändert die Reihenfolge der Additionen und bricht die Invarianz.
- Lösung der Forscher: Eine konsistente Reduktionsstrategie wird erzwungen, die für alle Batch-Größen gilt, auch wenn sie nicht für jede Größe die maximale Performance bietet.
2. Batch-invariante Matrixmultiplikation (Matmul)
Hier ist die Herausforderung aufgrund der komplexen Tensor Cores der GPUs größer.
- Standard-Ansatz: Die Ausgabe-Matrix wird in Kacheln zerlegt und auf die GPU-Kerne verteilt.
- Problem: Bei kleinen Eingabedimensionen wird eine „Split-K Matmul“-Strategie verwendet, die die Reduktion aufteilt und die Invarianz bricht. Zudem wählen Kernel-Bibliotheken oft je nach Matrixgröße unterschiedliche, numerisch nicht identische Tensor-Core-Instruktionen aus.
- Lösung der Forscher: Es wird eine einzige Kernel-Konfiguration mit einer festen Tensor-Core-Instruktion für alle Matrixgrößen verwendet. Der Performance-Verlust wird als moderat (ca. 20%) eingeschätzt, da in LLMs meist mindestens eine Dimension groß genug ist.
3. Batch-invariante Attention
Dies ist die komplexeste Aufgabe. Die Invarianz muss nicht nur über die Batch-Größe, sondern auch über die Sequenzlänge (z.B. Prefill vs. Decoding) gewährleistet sein.
- Problem: Bestehende Implementierungen behandeln Tokens aus dem KV-Cache anders als neue Tokens, was die Reduktionsreihenfolge fundamental ändert.
- Lösung der Forscher: Der KV-Cache wird vor dem Aufruf des Attention-Kernels aktualisiert, sodass der Kernel immer eine konsistente, zusammenhängende Sequenz verarbeitet. Bei Strategien zur Aufteilung langer Kontexte („Split-KV“) wird eine „Fixed Size Split-KV“-Methode genutzt, bei der die Größe der Berechnungs-Chunks fix ist, nicht deren Anzahl.
Die Lösung in der Praxis: Determinismus für vLLM & PyTorch
Thinking Machines Lab stellt die Ergebnisse nicht nur theoretisch vor, sondern liefert eine praktische Implementierung in der Bibliothek batch-invariant-ops. Hier ist das konzeptionelle Vorgehen zur Integration in ein System wie vLLM:
- Installation: Die Bibliothek
thinking-machines-lab/batch-invariant-opswird von GitHub geklont und installiert. - Operator-Patching: Mithilfe der
torch.Library-API werden die standardmäßigen PyTorch-Operatoren (z.B.aten::rms_norm,aten::bmm) zur Laufzeit durch die neuen, batch-invarianten Implementierungen ausgetauscht. - vLLM-Konfiguration: Der vLLM-Server wird mit den ausgetauschten Operatoren gestartet. Das FlexAttention-Backend von vLLM dient dabei als flexible Grundlage für die neuen Attention-Kernel.
- Verifizierung: Wiederholte Anfragen mit
temperature=0an den so konfigurierten Server sollten nun bitweise identische Ausgaben produzieren.
Zitat des Forschers: „Wir lehnen diesen Defätismus ab. Mit ein wenig Arbeit können wir die Ursachen unseres Nondeterminismus verstehen und sogar beheben!“, schreibt Horace He, der Hauptautor der Studie, in dem begleitenden Blogbeitrag [Thinking Machines, 2025].
Ergebnisse aus den Experimenten der Studie
Die Thesen werden durch zwei zentrale Experimente untermauert.
Fallstudie 1: Der multiple Richard Feynman
Das Team stellte dem Modell Qwen/Qwen3-235B-A22B-Instruct-2507 1000-mal dieselbe Frage („Tell me about Richard Feynman“) bei temperature=0.
- Standard-vLLM: Das System generierte 80 unterschiedliche Texte. Die ersten 102 Tokens waren identisch, doch am 103. Token kam es zur Divergenz: 992-mal folgte „Queens, New York“, 8-mal jedoch „New York City“.
- Mit batch-invarianten Kerneln: Alle 1000 Ausgaben waren bitweise identisch.
Dieses Ergebnis zeigt eindrücklich, wie minimale numerische Abweichungen im Verlauf der Textgenerierung zu signifikant unterschiedlichen Inhalten führen können.
Kosten-Nutzen-Analyse: Performance vs. Reproduzierbarkeit
Der garantierte Determinismus geht mit einem Performance-Overhead einher, da die Kernel noch nicht hochoptimiert sind und teils suboptimale Berechnungsstrategien erzwingen.
| Konfiguration | Zeit für 1000 Anfragen (Qwen-3-8B) |
| Standard vLLM | 26 Sekunden |
| Unoptimierter Determinismus | 55 Sekunden |
| Determinismus + Verbesserter Attention Kernel | 42 Sekunden |
Analyse: Der aktuelle Overhead liegt bei einem Faktor von ca. 1,6 bis 2,1. Für Anwendungsfälle, in denen Zuverlässigkeit, Debugging und wissenschaftliche Genauigkeit Priorität haben, kann dies ein vertretbarer Kompromiss sein.
Weitreichende Folgen für die KI-Forschung: Echtes On-Policy Reinforcement Learning
Die vielleicht wichtigste Konsequenz dieser Forschung betrifft das Reinforcement Learning (RL). Beim On-Policy-RL muss der Trainings-Datensatz von exakt der gleichen Modellversion („Policy“) generiert werden, die gerade trainiert wird.
Bisher war dies mit LLMs praktisch unmöglich. Da die Inferenz (Datensammlung) und das Training numerisch voneinander abwichen, befand man sich implizit immer in einem Off-Policy-Szenario. Dies erforderte instabile Korrekturverfahren wie Importance Weighting.
Die Studie demonstriert:
- Ohne Korrektur: Der Lernprozess des Modells bricht zusammen, da die numerische Abweichung (gemessen als KL-Divergenz) zwischen dem datensammelnden und dem lernenden Modell zu groß wird.
- Mit deterministischer Inferenz: Die KL-Divergenz bleibt konstant bei null. Der Trainingsprozess ist somit echtes On-Policy-RL und verläuft stabil, ohne dass Korrekturen notwendig sind.
Dies ist ein bedeutender Schritt für die Stabilität und Effektivität von Reinforcement Learning mit großen Sprachmodellen.
Häufig gestellte Fragen (FAQ)
Was genau versteht man unter LLM-Determinismus? Determinismus bedeutet, dass ein Algorithmus für eine gegebene Eingabe immer exakt dieselbe Ausgabe erzeugt. Für ein LLM heißt das, dass ein bestimmter Prompt bei temperature=0 jedes Mal zu einem bitweise identischen Text führen muss.
Warum ist temperature=0 nicht automatisch deterministisch? Die Hauptursache ist die fehlende „Batch-Invarianz“ der GPU-Kernel. Inferenz-Server bündeln Anfragen dynamisch zu Batches. Standard-Kernel ändern ihre Berechnungslogik je nach Batch-Größe, was durch Fließkomma-Arithmetik zu abweichenden Ergebnissen führt.
Was ist Batch-Invarianz? Batch-Invarianz ist die Eigenschaft eines GPU-Kernels, für einen einzelnen Datenpunkt (z.B. deine Anfrage) immer das exakt gleiche Ergebnis zu berechnen, unabhängig davon, mit wie vielen anderen Datenpunkten er im selben Batch verarbeitet wird.
Macht deterministische Inferenz meine LLM-Anwendung langsamer? Ja, die aktuelle Implementierung hat einen Performance-Overhead. Die Studie von Thinking Machines Lab zeigt eine Verlangsamung um den Faktor 1,6 bis 2,1. Für Anwendungen, die hohe Zuverlässigkeit erfordern, kann dieser Kompromiss sinnvoll sein.
Für wen ist deterministische LLM-Inferenz besonders wichtig? Sie ist entscheidend für Forscher (für reproduzierbare Experimente), Entwickler von RL-Systemen (für echtes On-Policy-Lernen), Unternehmen in regulierten Branchen (z.B. Finanzen, Medizin) und für alle, die komplexe KI-Systeme zuverlässig debuggen und testen müssen.
Kann ich diese deterministischen Methoden selbst nutzen? Ja, die Forscher haben die Kernkomponenten als Open-Source-Bibliothek (batch-invariant-ops) auf GitHub veröffentlicht. Sie erfordert technisches Wissen zur Integration in Systeme wie vLLM.
Fazit: Ein wichtiger Beitrag zur Zuverlässigkeit von KI-Systemen
Die Forschungsarbeit von Thinking Machines Lab ist eine wichtige Korrektur einer lange Zeit hingenommenen technischen Unzulänglichkeit. Der Nondeterminismus in LLMs ist kein unvermeidbares Schicksal der GPU-Architektur, sondern eine direkte Folge von Kernel-Implementierungen, die für maximale Effizienz auf Kosten der Invarianz optimiert wurden.
Die zentrale Erkenntnis ist, dass die Auslastung eines Systems das Ergebnis einer einzelnen Berechnung beeinflussen kann. Die vorgestellte Lösung in Form von batch-invarianten Kerneln ist ein konkreter und wichtiger Schritt hin zu robusteren, zuverlässigeren und vor allem wissenschaftlich reproduzierbaren KI-Modellen. Insbesondere die neuen Möglichkeiten für stabiles On-Policy Reinforcement Learning könnten die Forschung in diesem Bereich nachhaltig beeinflussen.
Die Arbeit ist ein Aufruf, numerische Instabilitäten nicht als gegeben zu akzeptieren, sondern ihre Ursachen zu ergründen. Der erreichte Determinismus erhöht die Vertrauenswürdigkeit und wissenschaftliche Fundierung von KI-Systemen maßgeblich.
Quellen und weiterführende Literatur
- He, H. & Thinking Machines Lab (2025). Defeating Nondeterminism in LLM Inference. Thinking Machines Lab: Connectionism. https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
- GitHub Repository (2025). batch-invariant-ops. Thinking Machines Lab.
- vLLM Project Documentation. An open-source library for fast LLM inference and serving. https://github.com/vllm-project/vllm
- PyTorch Documentation. torch.Library API for custom operators. https://pytorch.org/docs/stable/library.html
- Dao, T. (2023). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. https://arxiv.org/abs/2307.08691
- NVIDIA CUDA Documentation. Floating-Point and IEEE 754 Compliance. https://docs.nvidia.com/cuda/floating-point/












