
Stell dir vor, du könntest aus einem einzigen Foto und einer Sprachaufnahme ein komplettes, kinoreifes Video erstellen. Ein Video, in dem eine Person nicht nur die Lippen synchron bewegt, sondern mit authentischer Mimik, Gestik und Körpersprache agiert – fast wie ein echter Schauspieler. Genau das verspricht Wan-S2V, ein neues, wegweisendes KI-Modell für die Videogenerierung, das vom renommierten Tongyi Lab von Alibaba entwickelt wurde.
Veröffentlicht im August 2025, geht Wan-S2V weit über das hinaus, was wir bisher von Audio-gesteuerten KI-Modellen kannten. Statt starrer „Talking Heads“ erzeugt dieses System dynamische, filmische Szenen mit realistischen Charakteranimationen, die sowohl durch Sprache als auch durch Textanweisungen präzise gesteuert werden können. Wir tauchen tief ein und zeigen dir, wie diese beeindruckende Technologie funktioniert, was sie so besonders macht und wie sie die Erstellung von Videoinhalten verändern könnte.
Das Wichtigste in Kürze – Wan-S2V auf einen Blick
- Kinoreife Qualität: Erzeugt Videos mit realistischen Charakteren, komplexen Körperbewegungen und dynamischer Kameraführung, die weit über einfache sprechende Porträts hinausgehen.
- Duale Steuerung: Nutzt Text-Prompts für die globale Szenenregie (Bewegungen, Kamera) und Audio-Input für feingranulare Mimik, Gestik und lokale Aktionen.
- Lange & konsistente Videos: Eine spezielle Technik namens
FramePacksorgt für eine beeindruckende zeitliche Stabilität und Konsistenz in längeren Videoclips, ein häufiges Problem bei KI-Videos. - SOTA-Leistung: Übertrifft in quantitativen Benchmarks aktuelle Konkurrenzmodelle wie Hunyuan-Avatar deutlich und liefert qualitativ überlegene Ergebnisse.
- Entwickelt von Alibaba: Stammt aus dem Tongyi Lab und ist das erste Modell der neuen „Vida“-Forschungsreihe, die sich auf menschenzentrierte Videosynthese fokussiert.
Mehr als nur sprechende Köpfe: Was ist Wan-S2V?
Bisherige Modelle zur audio-gesteuerten Charakteranimation konzentrierten sich hauptsächlich auf Sprache und Gesang in einfachen Szenarien. Wan-S2V (ein Akronym für Speech-to-Video) bricht aus diesem Korsett aus. Das Ziel des Entwicklerteams bei Alibaba war es, die Lücke zu komplexen Film- und Fernsehproduktionen zu schließen, die nuancierte Interaktionen, realistische Körperbewegungen und professionelle Kameraarbeit erfordern.
Das Modell baut auf der leistungsstarken Wan Text-zu-Video-Grundlagentechnologie auf und erweitert diese um eine anspruchsvolle Audio-Steuerungskomponente. Das Ergebnis ist ein Werkzeug, das nicht nur Lippenbewegungen synchronisiert, sondern einer digitalen Figur Leben einhaucht – mit Emotionen, subtilen Gesten und einer glaubwürdigen Präsenz in einer Szene.
Das Regie-Geheimnis: Wie Wan-S2V Text und Audio kombiniert
Die wahre Stärke von Wan-S2V liegt in einer cleveren Arbeitsteilung, die man sich wie bei einer Filmproduktion vorstellen kann. Das Modell nutzt zwei verschiedene Inputs, um die Kontrolle zu maximieren und gleichzeitig ein harmonisches Ergebnis zu erzielen.
- Text als Drehbuch: Der Text-Prompt gibt die übergeordnete Regieanweisung. Du legst damit die Szene fest, beschreibst die Kameraeinstellungen (z. B. Weitwinkel, Nahaufnahme), die grundlegenden Bewegungsabläufe der Figur und die Interaktion mit der Umgebung.
- Audio als Schauspiel-Performance: Die Audio-Datei diktiert die feinen Nuancen. Sie steuert nicht nur die Lippensynchronität, sondern auch die Mimik, die Kopfhaltung und sogar präzise Handgesten, die zur gesprochenen oder gesungenen Emotion passen.
Die Entwickler im Tongyi Lab betonen, dass genau diese Synergie die Innovation ausmacht. „Wir sehen Text als optimales Werkzeug für die übergeordnete Dynamik eines Videos […], während Audio sich hervorragend eignet, um kleinste Details wie Charakterausdrücke […] zu steuern“, so die Kernaussage des Forschungsteams, die den Ansatz perfekt zusammenfasst.
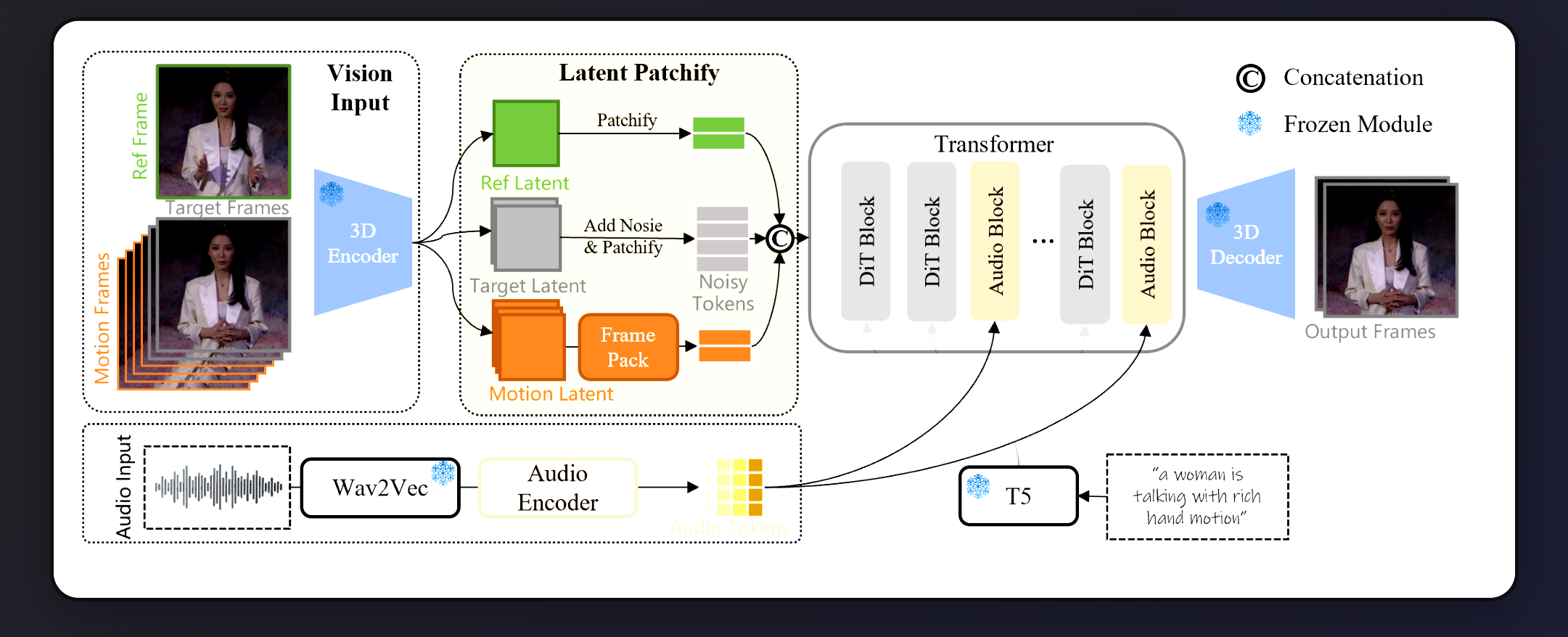
Ein Blick unter die Haube: Die Architektur von Wan-S2V
Ohne zu tief in die technische Materie abzudriften, basiert Wan-S2V auf einer modernen Diffusion-Transformer (DiT)-Architektur, ähnlich wie viele andere aktuelle Top-Modelle zur Bilderzeugung. Die Video-Frames werden zunächst von einem 3D VAE in einen komprimierten „latenten“ Raum umgewandelt.
Der eigentliche Clou ist die Audio-Integration:
- Die rohe Audio-Wellenform wird durch ein
Wav2Vec-Modell analysiert, das sowohl rhythmische und emotionale Hinweise als auch inhaltliche Merkmale erfasst. - Diese Audio-Informationen werden dann durch spezielle „Audio Blocks“ direkt in den Transformer eingespeist, wo sie die verrauschten visuellen Daten während des Denoising-Prozesses gezielt beeinflussen. Dieser Prozess stellt sicher, dass Bild und Ton perfekt aufeinander abgestimmt sind.
Praxis-Block: So erstellst du dein erstes kinoreifes Video mit Wan-S2V
Obwohl die Nutzung spezielle Hardware erfordert, ist der konzeptionelle Ablauf klar und zeigt, wie mächtig die Kombination der Eingaben ist. So entsteht ein Video:
- Das Standbild (Reference Image): Wähle ein klares Foto deines Charakters. Dieses Bild dient als Vorlage für die Identität und das Aussehen der Person im gesamten Video.
- Die Tonspur (Audio Input): Lade die Sprach-, Gesangs- oder sonstige Tonaufnahme hoch. Diese Datei wird die Mimik und die feinen Bewegungen steuern.
- Das Drehbuch (Text Prompt): Beschreibe die Szene, die Handlung und die gewünschte Stimmung in Textform (z. B. „Ein Mann sitzt in einem fahrenden Zug und singt melancholisch, während die Landschaft vorbeizieht“).
- (Optional) Die Choreografie (Pose Video): Für noch präzisere Bewegungssteuerung kannst du ein separates Video mit einer Posen-Sequenz bereitstellen, der die KI folgen soll.
- Generierung starten: Die KI kombiniert all diese Informationen und erzeugt ein Video, das die Identität aus dem Bild, die Performance aus dem Audio und die Szenerie aus dem Text vereint.
Qualität ist kein Zufall: Der Motor hinter der Magie – die Daten
Ein KI-Modell ist immer nur so gut wie die Daten, mit denen es trainiert wird. Das Team hinter Wan-S2V hat deshalb einen enormen Aufwand in die Kuratierung und Filterung des Trainingsdatensatzes investiert. Anstatt einfach nur Millionen von Videos zu verwenden, wurde eine mehrstufige Pipeline entwickelt, um höchste Qualität zu sichern:
- Datensammlung: Videos wurden aus Open-Source-Quellen wie OpenHumanVid und internen Datensätzen gesammelt.
- Posen-Analyse: Mit
VitPosewurde die 2D-Pose von Charakteren in den Videos getrackt, um sicherzustellen, dass nur Videos mit sichtbaren und relevanten menschlichen Aktionen verwendet werden. - Qualitäts-Filter: Spezialisierte KI-Modelle bewerteten jedes Video nach Kriterien wie Bildschärfe, Bewegungsstabilität, Ästhetik und ob Gesichter oder Hände durch Untertitel verdeckt sind.
- Audio-Synchronisation: Ein Modell namens
Light-ASDstellte sicher, dass der Ton auch wirklich zum sprechenden Charakter im Video passt und nicht asynchron ist. - Detaillierte Beschriftung: Das KI-Modell
Qwen-VL 2.5wurde genutzt, um extrem detaillierte Beschreibungen für jedes Video zu erstellen, die Kamerawinkel, Aktionen und Hintergrundmerkmale umfassen.
Dieser akribische Prozess garantiert, dass Wan-S2V auf einem sauberen, hochwertigen und gut beschriebenen Datensatz lernt, was sich direkt in der beeindruckenden Ausgabequalität widerspiegelt.
Die große Herausforderung: Wie Wan-S2V konsistente, lange Videos meistert
Ein bekanntes Problem bei der KI-Videogenerierung ist die Aufrechterhaltung der Konsistenz über längere Zeiträume. Oft verändern sich Details, Charaktere oder sogar die Szenerie von einem Clip zum nächsten. Wan-S2V adressiert dieses Problem mit einer cleveren Technik namens FramePack.
Dabei werden Informationen aus vorherigen Videoframes (sogenannte „Motion Frames“) komprimiert und als Kontext für die Erzeugung der nächsten Frames genutzt. FramePack reduziert dabei die Datenmenge der weiter zurückliegenden Frames stärker, sodass mehr historischer Kontext mit geringerem Rechenaufwand berücksichtigt werden kann. Das Ergebnis: Bewegungen, wie die eines fahrenden Zuges, bleiben über mehrere Clips hinweg flüssig und konsistent. Selbst Objekte, die ein Charakter in die Hand nimmt, behalten ihr Aussehen im nächsten Clip bei.
Technische Metriken im Vergleich: Wan-S2V an der Spitze
Quantitative Vergleiche auf dem EMTD-Benchmark-Datensatz zeigen die Überlegenheit des Modells. Hier eine vereinfachte Übersicht der wichtigsten Metriken:
| Metrik (je besser) | Bedeutung | Wan-S2V | Hunyuan-Avatar (HY-Avatar) | EMO2 | ||
| FID ↓ | Bildqualität (niedriger ist besser) | 15.66 | 18.07 | 27.28 | ||
| FVD ↓ | Video-Kohärenz (niedriger ist besser) | 129.57 | 145.77 | 129.41 | ||
| SSIM ↑ | Strukturelle Ähnlichkeit zum Original | 0.734 | 0.670 | 0.662 | ||
| CSIM ↑ | Identitäts-Konsistenz (Gesicht) | 0.677 | 0.583 | 0.650 | ||
| Quelle: Angelehnt an Tabelle 1 aus dem Wan-S2V Forschungspapier. |
Die Ergebnisse belegen, dass Wan-S2V in den entscheidenden Disziplinen wie Bildqualität (FID), Videoqualität (FVD) und Identitätserhaltung (CSIM) die Konkurrenz übertrifft.
Wan-S2V im Härtetest: Der direkte Vergleich mit der Konkurrenz
Zahlen sind das eine, der visuelle Eindruck das andere. Im direkten Vergleich zeigt Wan-S2V seine Stärken deutlich:
- Gegen Hunyuan-Avatar: Dieses Modell neigt bei großen Bewegungen zu Gesichtsverzerrungen und Identitätsverlusten. Wan-S2V hält die Identität der Person selbst bei sehr dynamischen Aktionen stabil.
- Gegen Ominihuman: Ominihuman erzeugt oft nur sehr eingeschränkte Bewegungen, die nah an der Pose des Ausgangsbildes bleiben. Wan-S2V generiert eine deutlich größere Bandbreite an Bewegungen und wirkt dadurch lebendiger und vielfältiger.
Häufig gestellte Fragen – Wan-S2V
Was ist der Hauptunterschied zwischen Wan-S2V und Modellen wie Sora? Sora ist ein generalistisches Text-zu-Video-Modell, das komplexe Szenen aus Textbeschreibungen erstellt. Wan-S2V ist spezialisiert auf die audio-gesteuerte Animation eines spezifischen Charakters, der durch ein Referenzbild definiert wird. Der Fokus liegt auf menschenzentrierter, filmischer Performance.
Ist Wan-S2V Open Source? Ja, das Team hat den Code für die Inferenz sowie die vortrainierten Modellgewichte (z. B. das Wan2.2-S2V-14B Modell) auf Plattformen wie Hugging Face und GitHub veröffentlicht, was Forschern und Entwicklern den Zugang ermöglicht.
Welche Hardware brauche ich, um Wan-S2V zu nutzen? Die Nutzung des großen 14B-Modells ist anspruchsvoll und erfordert GPUs mit mindestens 80 GB VRAM. Es gibt jedoch auch kleinere, effizientere Modelle der Wan-Reihe, wie ein 5B-Modell, das auf Consumer-Hardware wie einer NVIDIA RTX 4090 laufen kann.
Kann ich Wan-S2V auch für deutsche Sprache verwenden? Das Modell wurde auf einem sehr diversen, internationalen Datensatz trainiert. Es ist daher sehr wahrscheinlich, dass es auch mit deutscher Audio-Eingabe gut funktioniert, auch wenn die Performance bei Englisch, der primären Sprache vieler Trainingsdatensätze, am besten validiert ist.
Was sind die Grenzen des Modells? Die Entwickler selbst nennen Bereiche für zukünftige Forschung: Wirklich nuancierte Interaktionen zwischen mehreren Personen in einer Szene sowie eine präzise Kamerasteuerung, die ausschließlich durch Audio erfolgt, bleiben große Herausforderungen.
Anwendungsfälle und Grenzen: Für wen ist Wan-S2V wirklich geeignet?
Die beeindruckende Technologie von Wan-S2V eröffnet faszinierende Möglichkeiten, doch wie bei jedem spezialisierten Werkzeug ist es entscheidend zu verstehen, wo seine Stärken liegen und wo die aktuellen Grenzen verlaufen. Es ist keine magische Ein-Klick-Lösung für jedermann, sondern ein mächtiges Instrument für spezifische Anwendergruppen.
Konkrete Einsatzgebiete: Wo Wan-S2V glänzen kann
- Für Content Creator & Social Media: Erstelle digitale Avatare oder animiere Charaktere für Storytelling-Formate. Anstatt vor der Kamera zu stehen, kannst du eine statische Figur mit deiner Stimme zum Leben erwecken und so einzigartige, wiedererkennbare Inhalte produzieren.
- Für Unternehmen & E-Learning: Entwickle ansprechende und kosteneffiziente Schulungsvideos. Ein KI-generierter Trainer kann konsistent und unermüdlich komplexe Inhalte in verschiedenen Sprachen vermitteln, basierend auf nur einem Bild und dem entsprechenden Skript-Audio.
- Für die Kreativ- und Games-Industrie: Beschleunige die Produktion von Animationen. Im Gamedesign können NSCs (Nicht-Spieler-Charaktere) schnell mit lebensechten Dialoganimationen versehen werden. Für Filmemacher bietet sich die Technologie zur schnellen Vorvisualisierung (Previz) von Szenen an, bevor teure 3D-Animationen oder Drehs stattfinden.
Eine realistische Einordnung: Chancen vs. Herausforderungen
Um das Potenzial von Wan-S2V voll auszuschöpfen, ist eine ehrliche Betrachtung der aktuellen Vor- und Nachteile unerlässlich. Die folgende Tabelle stellt die größten Chancen den derzeitigen Herausforderungen gegenüber:
| Aspekt | Chancen mit Wan-S2V | Aktuelle Grenzen & Herausforderungen |
| Qualität & Realismus | Erzeugung kinoreifer Charakteranimationen mit exzellenter Lippensynchronität und hoher Identitätskonsistenz über lange Clips hinweg. | Die Gefahr des „Uncanny Valley“ besteht weiterhin. Subtile, nonverbale Nuancen, die über die Audio-Performance hinausgehen, sind schwer perfekt zu steuern. |
| Kreative Kontrolle | Die duale Steuerung über Text (Szene) und Audio (Performance) ermöglicht eine präzise Regie. Optionale Pose-Videos erlauben eine fast vollständige Bewegungs-Choreografie. | Die Ausgabequalität ist extrem stark von der Qualität der Eingabedaten (Bild, Audio, Prompt) abhängig. Komplexe Interaktionen zwischen mehreren Charakteren bleiben eine große Herausforderung. |
| Effizienz & Skalierbarkeit | Enorme Zeit- und Kostenersparnis im Vergleich zu traditioneller 3D-Animation oder Videodrehs. Ermöglicht die skalierbare Produktion von personalisierten Videos (z.B. im Marketing). | Obwohl schneller als manuelle Arbeit, sind die Renderzeiten pro Video signifikant. Es handelt sich nicht um eine Echtzeit-Anwendung. |
| Zugänglichkeit & Hardware | Als Open-Source-Modell fördert es die Forschung und die Entwicklung von Community-Tools. Ein kleineres 5B-Modell ist bereits auf leistungsstarker Consumer-Hardware (z.B. RTX 4090) lauffähig. | Das 14B-Topmodell erfordert extrem teure Profi-Hardware (z.B. 80 GB VRAM). Die Inbetriebnahme erfordert technisches Know-how und ist keine einfache Software-Installation. |
Zusammenfassend lässt sich sagen, dass Wan-S2V vor allem für professionelle und ambitionierte Anwender ein Game-Changer ist, die bereit sind, sich mit den technischen Anforderungen auseinanderzusetzen. Für sie ist es ein Werkzeug, das die Grenzen dessen, was eine einzelne Person oder ein kleines Team kreativ umsetzen kann, dramatisch erweitert.
Fazit: Ein digitaler Schauspieler statt einer sprechenden Puppe
Wan-S2V ist mehr als nur ein weiteres KI-Videomodell. Es markiert einen entscheidenden Schritt weg von einfachen Lip-Sync-Anwendungen hin zu einer echten digitalen Schauspielkunst. Die intelligente Kombination aus textbasierter Regie für die große Leinwand und audiobasierter Performance für die feinen Emotionen setzt einen neuen Standard für die Erstellung glaubwürdiger, menschlicher Charaktere.
Durch die beeindruckende Konsistenz bei langen Videos und die nachweislich überlegene Qualität gegenüber Konkurrenzmodellen positioniert sich Alibabas Tongyi Lab an der Spitze der menschenzentrierten KI-Videogenerierung. Als erstes Modell der „Vida“-Reihe gibt Wan-S2V einen spannenden Ausblick auf eine Zukunft, in der KI-generierte Charaktere in Filmen, Spielen und virtuellen Welten von echten Schauspielern kaum noch zu unterscheiden sein werden. Die Entwicklung bleibt spannend.
Quellen
- Gao, X., Hu, L., Hu, S., et al. (2025). WAN-S2V: AUDIO-DRIVEN CINEMATIC VIDEO GENERATION. Tongyi Lab, Alibaba.
- HumanAIGC Team. (2025). Wan-S2V Project Webpage. GitHub.
- Wan-Video Team. (2025). Wan2.2 GitHub Repository.
- Wan-S2V – Paper
#WanS2V #KIVideo #AIvideo #Alibaba #TongyiLab #S2V #KuenstlicheIntelligenz #Videogenerierung









