

WebThinker 2025: Große Schlussfolgerungsmodelle (Large Reasoning Models, LRMs) wie OpenAI-o1 und DeepSeek-R1 haben beeindruckende Fortschritte in Bereichen wie Mathematik, Programmierung und wissenschaftlichem Denken erzielt. Doch stoßen sie an Grenzen, wenn es um komplexe Informationsrecherchen geht, die über ihr internes, statisches Wissen hinausgehen. Die Fähigkeit, tiefgreifende Webinformationen zu explorieren und präzise wissenschaftliche Berichte durch mehrstufige Denkprozesse zu erstellen, ist für diese Modelle eine Herausforderung.
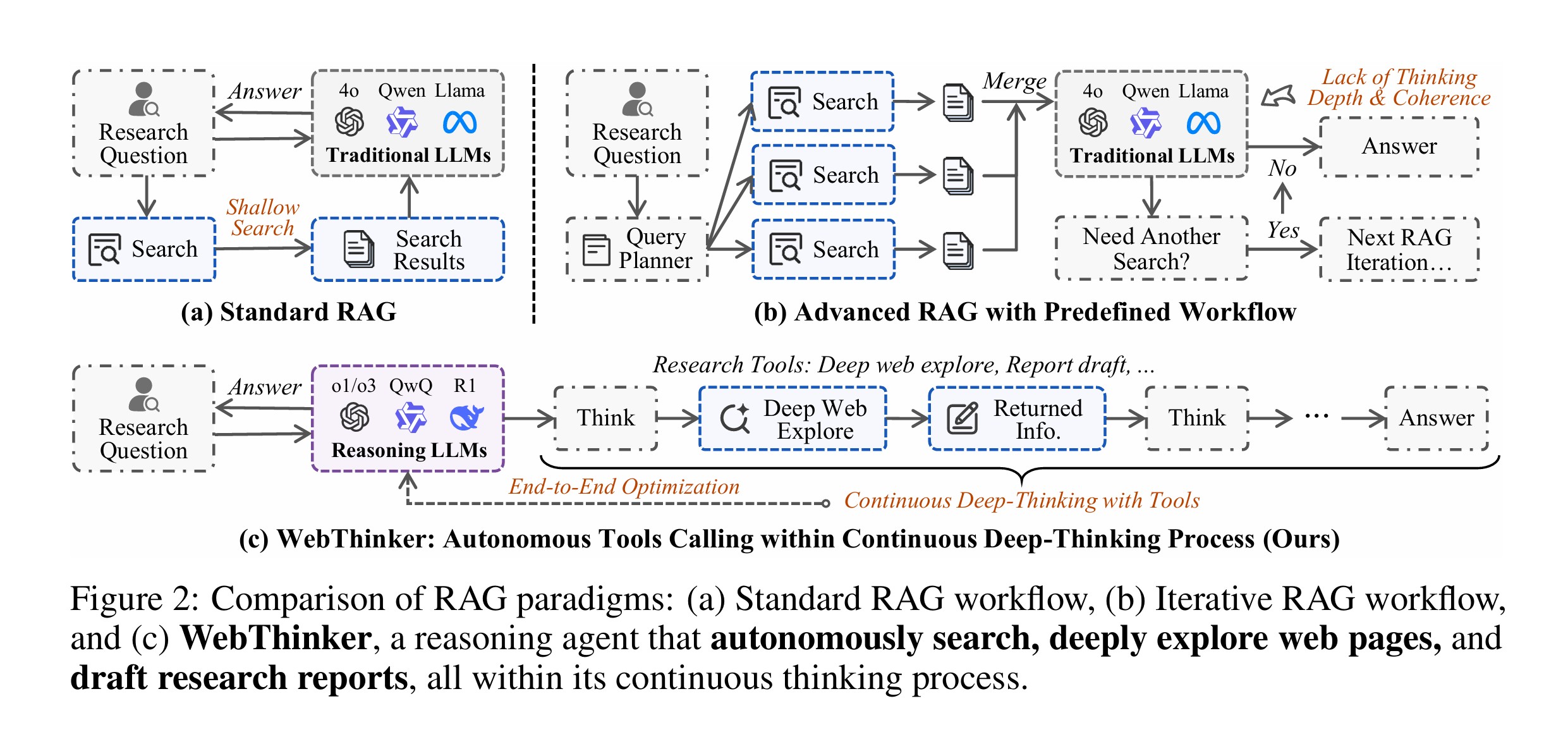
Die Notwendigkeit einer tiefen Integration der Schlussfolgerungsfähigkeiten von LRMs mit der Webexploration ist offensichtlich und hat eine Welle von Forschungsinitiativen ausgelöst. Bestehende Open-Source-Agenten für die Tiefensuche nutzen oft Retrieval-Augmented Generation (RAG)-Techniken mit starren, vordefinierten Arbeitsabläufen.
Dies schränkt die Fähigkeit von LRMs ein, tiefergehende Webinformationen zu erschließen, und behindert eine effektive Interaktion zwischen den LRMs und Suchmaschinen. Forscher der Renmin University of China, des Beijing Academy of Artificial Intelligence (BAAI) und des Huawei Poisson Lab stellen nun mit WebThinker einen Deep Research Agent vor, der LRMs befähigt, autonom im Web zu suchen, Webseiten zu navigieren und Forschungsberichte direkt im Denkprozess zu entwerfen.
Die Entwicklung von LRMs schreitet rasant voran, wobei Modelle wie das genannte OpenAI-o1, Qwen-QwQ und DeepSeek-R1 ihre Leistungsfähigkeit durch erweiterte Schlussfolgerungsfähigkeiten stetig verbessern. Verschiedene Strategien wurden vorgeschlagen, um diese fortgeschrittenen Denkfähigkeiten zu erreichen, darunter das gezielte Training mit fehlerhaften Schlussfolgerungen, die Verwendung destillierter Trainingsdaten und Ansätze des Reinforcement Learnings zur Entwicklung langer „Chain-of-Thought“-Fähigkeiten.
Ein fundamentales Problem bleibt jedoch: Diese Methoden sind durch ihre statischen, parametrisierten Architekturen begrenzt und haben keinen Zugriff auf externes Weltwissen. Hier setzt die RAG-Technologie an, die Abrufmechanismen mit generativen Modellen integriert und so den Zugriff auf externes Wissen ermöglicht. Jüngste Fortschritte in diesem Bereich umfassen verschiedene Dimensionen, wie die Notwendigkeit des Abrufs, die Neuformulierung von Anfragen, die Komprimierung von Dokumenten, die Rauschunterdrückung und das Befolgen von Anweisungen. WebThinker geht hier noch einen entscheidenden Schritt weiter.
Das musst Du wissen – WebThinker im Überblick
- Autonome Web-Exploration: WebThinker ermöglicht Large Reasoning Models (LRMs), selbstständig im Internet zu suchen, Webseiten zu navigieren und benötigte Informationen zu extrahieren, wenn Wissenslücken auftreten.
- Dynamische Informationsbeschaffung: Durch das Deep Web Explorer Modul können LRMs dynamisch Informationen abrufen und sind nicht mehr nur auf ihr trainiertes Wissen beschränkt, was die Deep Research Fähigkeiten revolutioniert.
- Integrierter Schreibprozess: Die Autonomous Think-Search-and-Draft Strategie erlaubt es den Modellen, Denkprozesse, Informationsbeschaffung und das Verfassen von Berichten nahtlos und in Echtzeit zu kombinieren.
- Optimierte Werkzeugnutzung: Eine auf Reinforcement Learning (RL) basierende Trainingsstrategie, die iterative Online Direct Preference Optimization (DPO) nutzt, verbessert die Fähigkeit der LRMs, die bereitgestellten Recherchewerkzeuge effektiv einzusetzen.
- Signifikante Leistungssteigerung: WebThinker übertrifft bestehende Methoden und sogar fortschrittliche proprietäre Systeme in komplexen Problemlösungsaufgaben und bei der Generierung wissenschaftlicher Berichte deutlich, wie Benchmarks zeigen.
WebThinkers Kernarchitektur und Funktionsweise: Ein tiefer Einblick
WebThinker wurde entwickelt, um die inhärenten Beschränkungen von Large Reasoning Models (LRMs) bei komplexen, wissensintensiven Aufgaben zu überwinden. Diese Modelle, obwohl leistungsstark in der Verarbeitung und Generierung von Informationen basierend auf ihren Trainingsdaten, kämpfen oft mit der Notwendigkeit, aktuelle oder sehr spezifische Informationen aus dem riesigen Fundus des Internets zu beschaffen und zu synthetisieren. Die Forscher der Renmin University of China, BAAI und des Huawei Poisson Lab adressieren dieses Problem mit einem innovativen Ansatz, der LRMs echte Recherchefähigkeiten verleiht.
Die zwei Modi von WebThinker
Das Framework von WebThinker operiert in zwei primären Modi, um unterschiedlichen Anforderungen gerecht zu werden: dem Problem-Solving Mode und dem Report Generation Mode.
Im Problem-Solving Mode konzentriert sich WebThinker darauf, komplexe Aufgaben zu lösen, indem es das Deep Web Explorer Werkzeug nutzt. Dieses Modul kann vom LRM während des Denkprozesses dynamisch aufgerufen werden, sobald eine Wissenslücke identifiziert wird. Stell Dir vor, das LRM arbeitet an einer komplexen wissenschaftlichen Frage und stößt auf einen Aspekt, zu dem ihm Informationen fehlen. Statt zu scheitern oder ungenaue Angaben zu machen, kann es über den Deep Web Explorer aktiv eine Websuche starten, relevante Seiten analysieren, durch Links navigieren und die benötigten Fakten extrahieren, um seine Schlussfolgerungskette fortzusetzen und eine fundierte Antwort zu generieren.
Der Report Generation Mode geht noch einen Schritt weiter. Hier produziert das LRM autonom detaillierte Berichte. Es nutzt dabei nicht nur den Deep Web Explorer zur Informationsbeschaffung, sondern greift auch auf ein unterstützendes Large Language Model (LLM) zurück, das spezielle Werkzeuge für das Verfassen von Berichten implementiert. Dies ermöglicht einen iterativen Prozess: Das LRM kann einen Abschnitt des Berichts entwerfen, feststellen, dass weitere Informationen für die nächste Sektion benötigt werden, diese über den Deep Web Explorer suchen und dann den Entwurf fortsetzen oder überarbeiten.

Deep Web Explorer: Das Tor zu externem Wissen
Das Herzstück der Recherchefähigkeiten von WebThinker ist das Deep Web Explorer Modul. Es ist weit mehr als eine einfache Suchanfrage-Schnittstelle. Dieses Modul befähigt das LRM, dynamisch zu agieren, wenn es auf Wissensdefizite stößt. Es kann:
- Suchen: Gezielte Suchanfragen an Web-Suchmaschinen stellen.
- Navigieren: Interaktive Elemente auf Webseiten wie Links oder Buttons „klicken“, um tiefer in die Informationshierarchie einer Webseite oder eines Web-Angebots vorzudringen.
- Extrahieren: Relevante Informationen aus den besuchten Webseiten herausfiltern und für den weiteren Denkprozess aufbereiten.
Diese Fähigkeit, nicht nur oberflächliche Suchergebnisse zu nutzen, sondern Webseiten aktiv zu explorieren, ist ein entscheidender Unterschied zu traditionellen RAG-Ansätzen, die oft bei den initialen Suchergebnissen stehen bleiben.
Autonomous Think-Search-and-Draft: Der integrierte Workflow
Ein weiteres Kernmerkmal ist die Autonomous Think-Search-and-Draft Strategie. Sie ermöglicht es den Modellen, die Prozesse des Denkens, der Informationsbeschaffung und des Schreibens von Berichten nahtlos und in Echtzeit miteinander zu verknüpfen. Anstatt erst nach einer abgeschlossenen Recherche mit dem Schreiben zu beginnen, kann das LRM während des Schreibprozesses neue Suchanfragen initiieren oder bestehende Entwürfe basierend auf neu gefundenen Informationen anpassen. Dieser dynamische und iterative Ansatz spiegelt den menschlichen Forschungsprozess wider, bei dem Erkenntnisse oft schrittweise gewonnen und direkt verarbeitet werden.
Um dies zu unterstützen, werden den LRMs spezialisierte Werkzeuge an die Hand gegeben:
- Ein Werkzeug zum Entwerfen von Inhalten für spezifische Kapitel.
- Ein Werkzeug zur Überprüfung des aktuellen Berichts (z.B. auf Vollständigkeit oder Kohärenz).
- Ein Werkzeug zur Bearbeitung des Berichts.
Diese Werkzeuge ermöglichen es dem LRM, die Qualität des Berichts autonom zu verbessern und sicherzustellen, dass er umfassend, kohärent und an neu entdeckte Informationen angepasst ist.

Optimierung durch Reinforcement Learning (RL)
Um die Nutzung dieser leistungsstarken Forschungswerkzeuge weiter zu verfeinern, implementiert WebThinker eine auf Reinforcement Learning (RL) basierende Trainingsstrategie. Konkret wird hierbei iterative Online Direct Preference Optimization (DPO) eingesetzt. Dabei generiert das WebThinker-Framework diverse Schlussfolgerungspfade (Reasoning Trajectories), indem es auf umfangreiche Datensätze komplexer Schlussfolgerungs- und Berichtgenerierungsaufgaben angewendet wird. Zu diesen Datensätzen gehören unter anderem SuperGPQA, WebWalkerQA, OpenThoughts, NaturalReasoning, NuminaMath und Glaive.
Für jede Anfrage produziert das initiale LRM mehrere unterschiedliche Lösungswege. Anhand der Genauigkeit der Schlussfolgerungen, der Werkzeugnutzung und der finalen Ergebnisse werden dann Präferenzpaare erstellt, die dem Modell signalisieren, welche Pfade und Werkzeugnutzungen erfolgreicher oder effizienter waren. Durch dieses iterative On-Policy-Training verbessert das Modell schrittweise seine Fähigkeit, die Forschungswerkzeuge wahrzunehmen, zu interpretieren und effektiv einzusetzen.
Leistungsfähigkeit und Benchmarks: WebThinker im Härtetest
Die wahre Stärke einer neuen Technologie wie WebThinker zeigt sich in ihrer Performance im Vergleich zu etablierten Methoden und in anspruchsvollen Testszenarien. Die Entwickler haben WebThinker umfangreichen Experimenten unterzogen, sowohl bei komplexen, wissensintensiven Schlussfolgerungsaufgaben als auch bei der Generierung wissenschaftlicher Berichte.
Überlegenheit bei komplexen Problemlösungen
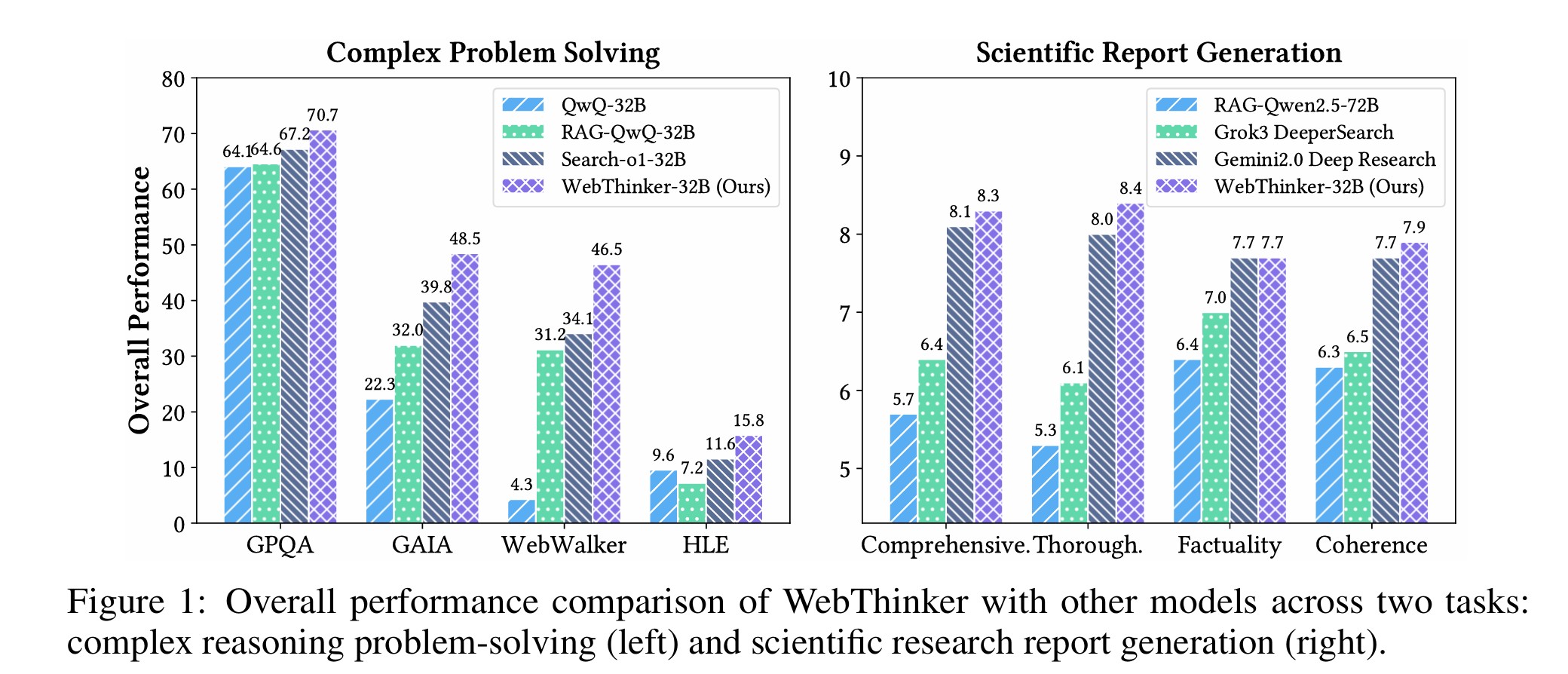
In Benchmarks für komplexe Problemlösungen, darunter GPQA (Fragen auf PhD-Niveau), GAIA (für allgemeine KI-Assistenten), WebWalkerQA (fokussiert auf tiefe Web-Informationsbeschaffung) und HLE (Humanity’s Last Exam – extrem herausfordernde, disziplinübergreifende Probleme), demonstrierte WebThinker eine beeindruckende Leistungsfähigkeit. Das WebThinker-32B-Base Modell übertraf beispielsweise frühere Methoden wie Search-o1 in allen Benchmarks deutlich. So wurde eine Verbesserung von 22,9% auf WebWalkerQA und 20,4% auf HLE erzielt. Diese Zahlen unterstreichen die Effektivität des Deep Web Explorer Moduls, das eine tiefere und präzisere Informationsgewinnung aus dem Web ermöglicht.
Das durch Reinforcement Learning weiter optimierte Modell, WebThinker-32B-RL, erreichte sogar State-of-the-Art-Resultate unter den 32B-Modellen in allen getesteten Benchmarks und zeigte substanzielle Verbesserungen gegenüber der Base-Version (z.B. 8,5% auf GAIA und 21,5% auf HLE). Bemerkenswert ist, dass WebThinker-32B-RL auf dem extrem schwierigen HLE-Benchmark sogar die Leistung stärkerer Modelle wie o3-mini (High) übertraf.
Spitzenleistungen in der wissenschaftlichen Berichterstellung
Auch bei der Generierung wissenschaftlicher Berichte, evaluiert anhand des Glaive-Datensatzes, setzte sich WebThinker an die Spitze. Bewertet wurden die Berichte hinsichtlich Vollständigkeit, Gründlichkeit, Faktizität und Kohärenz. Hier erreichte WebThinker einen Gesamtscore von 8.0, womit es sowohl RAG-Baselines als auch fortschrittliche Deep-Research-Systeme wie Gemini-Deep Research (7.9) übertraf. Besonders hervorgetan hat sich WebThinker in den Kriterien Vollständigkeit (8.4) und Gründlichkeit (8.2). Diese Ergebnisse unterstreichen die Stärke der „Autonomous Think-Search-and-Draft“-Strategie, die es dem LRM erlaubt, Inhalte iterativ zu verfeinern und umfassendere sowie kohärentere Berichte zu erstellen, als es mit vordefinierten RAG-Workflows möglich wäre.
Anpassungsfähigkeit an verschiedene LRM-Backbones
Ein weiterer wichtiger Aspekt ist die Adaptierbarkeit von WebThinker über verschiedene LRM-Architekturen hinweg. Die Experimente zeigten, dass R1-basierte WebThinker-Modelle (mit DeepSeek-R1 als Backbone in verschiedenen Größen – 7B, 14B, 32B) durchweg besser abschnitten als direkte Schlussfolgerungen oder Standard-RAG-Implementierungen. Beispielsweise erreichte WebThinker mit dem DeepSeek-R1-7B Backbone relative Verbesserungen von 174,4% auf GAIA und beeindruckenden 422,6% auf WebWalkerQA im Vergleich zur direkten Generierung ohne WebThinker. Gegenüber Standard-RAG-Implementierungen lagen die Verbesserungen bei 82,9% auf GAIA und 161,3% auf WebWalkerQA. Diese Resultate belegen die generelle Anwendbarkeit und die hohe Effektivität des WebThinker-Frameworks zur Steigerung der Deep-Research-Fähigkeiten verschiedener LRMs.
Die Ablationsstudien bestätigten zudem den signifikanten Beitrag der einzelnen Kernkomponenten: Das iterative Online-RL-Training verbesserte die Problemlösungsleistung, der Deep Web Explorer (insbesondere die Link-Klick-Fähigkeit) erwies sich als kritisch für beide Aufgabenbereiche, und die autonomen Entwurfs- sowie Überarbeitungsfunktionen waren essenziell für die Qualität der Berichtsgenerierung.
Fazit und Ausblick: Die Zukunft der KI-gestützten Forschung mit WebThinker
Die Einführung von WebThinker durch die Forscher der Renmin University of China, BAAI und des Huawei Poisson Lab markiert einen signifikanten Fortschritt im Bereich der Large Reasoning Models (LRMs) und ihrer Fähigkeit, komplexe, wissensintensive Aufgaben zu bewältigen. Indem es LRMs befähigt, autonom das Web zu explorieren, Informationen dynamisch zu beschaffen und umfassende Berichte in einem kontinuierlichen Denkprozess zu erstellen, adressiert WebThinker grundlegende Limitierungen bisheriger Ansätze.
Die Kerninnovationen – der Deep Web Explorer für die dynamische Webnavigation und Informationsextraktion sowie die Autonomous Think-Search-and-Draft Strategie für die nahtlose Integration von Denken, Suchen und Schreiben – haben sich in umfangreichen Tests als äußerst wirkungsvoll erwiesen. Die zusätzliche Verfeinerung durch RL-basierte Trainingsstrategien hebt die Leistungsfähigkeit auf ein neues Niveau. Die Fähigkeit von WebThinker, bestehende Methoden und sogar starke proprietäre Systeme in anspruchsvollen Benchmarks zu übertreffen, unterstreicht sein enormes Potenzial, die Deep-Research-Fähigkeiten von LRMs maßgeblich zu erweitern.
Dies ebnet den Weg für leistungsfähigere und vielseitigere intelligente Systeme, die in der Lage sind, komplexe Herausforderungen der realen Welt anzugehen – von der wissenschaftlichen Forschung über Finanzanalysen bis hin zur Ingenieurskunst. Die Entwickler sehen bereits die nächsten Schritte vor, um WebThinker weiter zu verbessern und seine Anwendungsbereiche zu erweitern:
- Multimodale Schlussfolgerungsfähigkeiten: Zukünftig soll WebThinker auch in der Lage sein, multimodale Informationen wie Bilder und Videos in seine Recherche einzubeziehen und die reichhaltigen nicht-textuellen Inhalte des Webs zu nutzen.
- Fortgeschrittene Mechanismen zum Werkzeuglernen: Geplant ist die Erforschung von Mechanismen, die es WebThinker ermöglichen, seine Strategien zur Werkzeugnutzung durch Selbstverbesserung kontinuierlich zu verfeinern und ein breiteres Spektrum externer Werkzeuge zu integrieren.
- GUI-basierte Web-Exploration: Untersucht werden soll zudem die Interaktion mit grafischen Benutzeroberflächen (GUIs) im Web, um die Fähigkeit des Modells zu verbessern, auch komplexe interaktive Aufgaben auf modernen Webseiten zu meistern.
Die Veröffentlichung des Codes unter https://github.com/RUC-NLPIR/WebThinker fördert Transparenz und ermöglicht es der breiteren Forschungsgemeinschaft, auf dieser vielversprechenden Entwicklung aufzubauen. WebThinker ist somit nicht nur ein leistungsfähiges Werkzeug, sondern auch ein Katalysator für zukünftige Innovationen im Bereich der künstlichen Intelligenz und der automatisierten Wissensakquise. Es verspricht eine Zukunft, in der LRMs zu noch kompetenteren Partnern für Menschen in wissensintensiven Domänen werden.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
- Li, X., Jin, J., Dong, G., Qian, H., Zhu, Y., Wu, Y., Wen, J.-R., & Dou, Z. (2025). WebThinker: Empowering Large Reasoning Models with Deep Research Capability. arXiv:2504.21776 [cs.CL]. https://arxiv.org/abs/2504.21776
- GitHub Repository: https://github.com/RUC-NLPIR/WebThinker (genannt in arXiv:2504.21776)
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #WebThinker #LRM #DeepResearch #AutonomeSysteme








