
Einleitung – Demo Bild erstellt mit Würstchen

Bild erstellt mit Würstchen, Prompt: A hightech sausages which looks like the mixture between a sausage and an AI robot, high detail, high color, impressive, on white ground by WÜRSTCHEN
Würstchen – Schnelle Diffusion für die Bildgenerierung: Zunehmend wird unser Leben von Maschinenlernen und künstlicher Intelligenz durchdrungen: Das Würstchen-Modell ist ein (neuer) Meilenstein in der schnellen und effizienten Generierung von Bildern. Würstchen ist nicht einfach nur ein weiteres Text-zu-Bild-Modell; es revolutioniert die Art und Weise, wie wir über Datenkompression und Rechenkosten nachdenken. Mit einer beispiellosen 42-fachen räumlichen Kompression und reduzierten GPU-Stunden für das Training stellt dieses Modell einen Paradigmenwechsel in der Welt der Bildgenerierung dar.
Im Gegensatz zu seinen Konkurrenten wie Stable Diffusion XL bietet Würstchen eine Reihe von Vorteilen, die sowohl für Forscher als auch für Unternehmen von Nutzen sind. Die Reduzierung der Kosten für Training und Inferenz macht es für eine breitere Masse zugänglich. Zudem ist es vollständig in die Diffusers-Bibliothek integriert und bietet so eine Reihe von Optimierungen “out of the box”.
In diesem Artikel werden wir tief in die technischen Details des Würstchen-Modells eintauchen, seine Architektur erklären und warum es als Durchbruch in der Text-zu-Bild-Generierung angesehen wird. Wir werden die drei Stufen A, B und C des Modells, die als Decoder bezeichnet werden, sowie die spezifischen Optimierungstechniken untersuchen, die es so effizient machen. Dabei werden auch Praxisbeispiele und Leistungsvergleiche nicht fehlen, um das Potenzial von Würstchen in vollem Umfang zu beleuchten.

Inhaltsverzeichnis Würstchen – Schnelle Diffusion
- Was ist Würstchen?
- Stufe A, B und C
- Der Prior
- Warum ein weiteres Text-zu-Bild-Modell?
- Geschwindigkeit und Effizienz
- Kosteneffizienz
- Anwendung von Würstchen
- Demo und Bibliothek
- Technische Implementierung
- Zusätzliche Optimierungstechniken
- Flash Attention
- Torch Compile
- Fazit
- Ausblick auf weitere Forschung und Wirtschaft
1. Was ist Würstchen – Schnelle Diffusion?
Stufe A, B und C
Während die meisten Modelle zur Bildgenerierung sich auf eine einzige Komprimierungsstufe verlassen, geht Würstchen einen Schritt weiter und implementiert eine zweistufige Komprimierung, die in den Stufen A und B bezeichnet wird. Der Grund für diese innovative Herangehensweise liegt in der Effizienz. Durch die Kombination von zwei verschiedenen Technologien, VQGAN für Stufe A und Diffusion Autoencoder für Stufe B, wird eine beispiellose räumliche Komprimierung von 42x erreicht. Im Vergleich zu herkömmlichen Methoden, die eine räumliche Komprimierung im Bereich von 4x – 8x verwenden, erreicht Würstchen eine räumliche Komprimierung von 42x!
Stufe A: VQGAN
VQGAN, kurz für Vector Quantized Generative Adversarial Networks, ist ein bewährtes Modell zur Datenkomprimierung. In Stufe A des Würstchen-Modells dient es als erste Filterebene. Hier werden die ursprünglichen Bilddaten zuerst aufgenommen und einer ersten Reduktion unterzogen. Diese ersten Schritte sind entscheidend für die Vorbereitung der Daten auf die anschließende, intensivere Komprimierung in Stufe B.
Stufe B: Diffusion Autoencoder
Nachdem die Daten durch VQGAN in Stufe A vorbehandelt wurden, kommen sie in Stufe B an, wo ein Diffusion Autoencoder zum Einsatz kommt. Dieser Autoencoder hat die Fähigkeit, den Datensatz weiter zu reduzieren, während er gleichzeitig wichtige Informationen beibehält. Dies ist die entscheidende Phase, in der die maximale räumliche Komprimierung von 42x erreicht wird.
Würstchen – Schnelle Diffusion – Der Prior

Die Rolle von Stufe C
Nachdem die komprimierten Daten durch die Stufen A und B generiert wurden, tritt Stufe C, auch als der Prior bekannt, in Aktion. Dieses dritte Modell hat die Aufgabe, in dem hochkomprimierten latenten Raum zu lernen und die Generierung des Endbildes zu steuern. Die Besonderheit hierbei ist, dass der Prior wesentlich weniger Rechenleistung für das Training benötigt, verglichen mit herkömmlichen Modellen.
Rechenkosten und Effizienz
Der entscheidende Vorteil des Priors in Würstchen liegt in seiner Effizienz. Da es in einem bereits stark komprimierten Raum arbeitet, sind die Rechenanforderungen minimal. Dies eröffnet neue Möglichkeiten für Forscher und Entwickler, die bisher durch hohe Hardwarekosten und Rechenzeiten eingeschränkt waren.
Anpassungsfähigkeit und Skalierbarkeit
Ein weiteres bemerkenswertes Feature von Stufe C ist seine schnelle Anpassungsfähigkeit an neue Auflösungen. Das bedeutet, dass es nicht nur kosteneffizient, sondern auch flexibel ist. Dies ist besonders nützlich in einer Zeit, in der die Anforderungen an Bildauflösungen ständig steigen, aber die verfügbaren Ressourcen begrenzt sind.
Würstchen – Schnelle Diffusion – Warum ein weiteres Text-zu-Bild-Modell?
Marktbedürfnis und Anwendungsbreite
Die rasante Entwicklung im Bereich der KI und insbesondere der Text-zu-Bild-Generierung hat eine Vielzahl von Anwendungsfällen erschlossen, von der Medizin bis zur Unterhaltungsindustrie. In diesem dynamischen Umfeld stellt sich Würstchen als eine Antwort auf den dringenden Bedarf nach schnelleren und kosteneffizienteren Lösungen dar. Es ist nicht nur eine Frage des “Wie”, sondern auch des “Warum” – warum benötigen wir eine leistungsfähigere Lösung, und wie passt Würstchen in dieses größere Bild?
Wettbewerbsvorteile
Während es viele Modelle gibt, die ähnliche Aufgaben erfüllen können, bringt Würstchen eine Reihe von Wettbewerbsvorteilen mit sich. Zum einen die Geschwindigkeit der Bildgenerierung und zum anderen die deutlich reduzierten Trainingskosten. Diese Aspekte könnten es zu einer ersten Wahl für Unternehmen und Entwickler machen, die effektive, aber budgetfreundliche Lösungen suchen.
Technologische Innovation
Die Einführung von Würstchen markiert nicht nur einen Fortschritt in der Effizienz, sondern auch in der Technologie selbst. Durch die Nutzung einer zweistufigen Komprimierung und die Implementierung eines Priors bietet es eine frische Perspektive auf das, was in der Text-zu-Bild-Generierung möglich ist.
Würstchen – Schnelle Diffusion – Geschwindigkeit und Effizienz
Energieverbrauch und Nachhaltigkeit
Die Geschwindigkeit und der niedrige Speicherbedarf von Würstchen tragen auch zu einem weiteren wichtigen Aspekt bei: der Nachhaltigkeit. In einer Welt, in der Energieeffizienz und CO2-Fußabdruck immer mehr an Bedeutung gewinnen, bietet Würstchen eine grüne Alternative zu ressourcenintensiven Modellen wie Stable Diffusion XL.
Anpassbarkeit an unterschiedliche Hardware
Die Effizienz von Würstchen erstreckt sich auch auf seine Anwendbarkeit auf verschiedenen Hardware-Konfigurationen. Dies macht es attraktiv für Entwickler, die vielleicht nicht über die modernsten GPUs verfügen, aber dennoch qualitativ hochwertige Ergebnisse erzielen möchten.
Würstchen – Schnelle Diffusion – Kosteneffizienz
Demokratisierung der KI
Der niedrige Trainingsaufwand von nur 9.000 GPU-Stunden eröffnet die Tür für kleinere Organisationen und sogar Einzelpersonen, die bisher nicht die Möglichkeit hatten, eigene Modelle auszubilden. Das trägt zur Demokratisierung der KI bei, indem es den Zugang zu fortschrittlichen Technologien erweitert.
Skalierbare Wirtschaftlichkeit
Der reduzierte Trainingsaufwand spiegelt sich nicht nur in den direkten Kosten wider, sondern auch in der Möglichkeit der Skalierung. Unternehmen können nun mehr Modelle parallel ausbilden oder das gesparte Budget in andere Innovationsbereiche investieren. Diese Form der wirtschaftlichen Skalierbarkeit könnte Würstchen zu einem wesentlichen Bestandteil der KI-Landschaft machen.
Anwendung von Würstchen – Schnelle Diffusion
User Experience und Zugänglichkeit
Die Integration von Würstchen in die Diffusers-Bibliothek bedeutet, dass Benutzer keinen großen Lernaufwand betreiben müssen, um das Modell in ihre bestehenden Workflows zu integrieren. Das trägt wesentlich zur Benutzerfreundlichkeit und schnellen Akzeptanz bei. Während die Demo zum Zeitpunkt des Schreibens noch nicht verfügbar ist, zeigt ihre geplante Einführung das Engagement für eine interaktive und leicht verständliche Benutzererfahrung.
API- und Framework-Kompatibilität
Dank der einfachen Implementierung über PyTorch ist Würstchen auch gut geeignet für die Einbindung in bestehende Systeme und Anwendungen. Die Kompatibilität mit gängigen Programmierschnittstellen und Frameworks macht es zu einer flexiblen Option für Entwickler unterschiedlicher Kenntnisstufen.
Technische Implementierung
Modularität und Flexibilität
Würstchen ist nicht nur effizient, sondern auch flexibel. Durch die Möglichkeit, verschiedene Voreinstellungen und Anpassungen vorzunehmen, können Benutzer das Modell für eine Vielzahl von Anwendungen optimieren. Diese Modularität erleichtert die Anpassung an spezifische Projektanforderungen und macht Würstchen zu einer vielseitigen Lösung.
Erweiterbarkeit und Community-Beiträge
Da das Modell in Python und PyTorch implementiert ist, eröffnet es Möglichkeiten für die Open-Source-Community, Erweiterungen und Verbesserungen beizutragen. Dies könnte die Entwicklung von Würstchen in verschiedene Richtungen vorantreiben und zu einer dynamischeren und reichhaltigeren Funktionalität führen.
Zusätzliche Optimierungstechniken
Auto-Tuning und Echtzeit-Optimierung
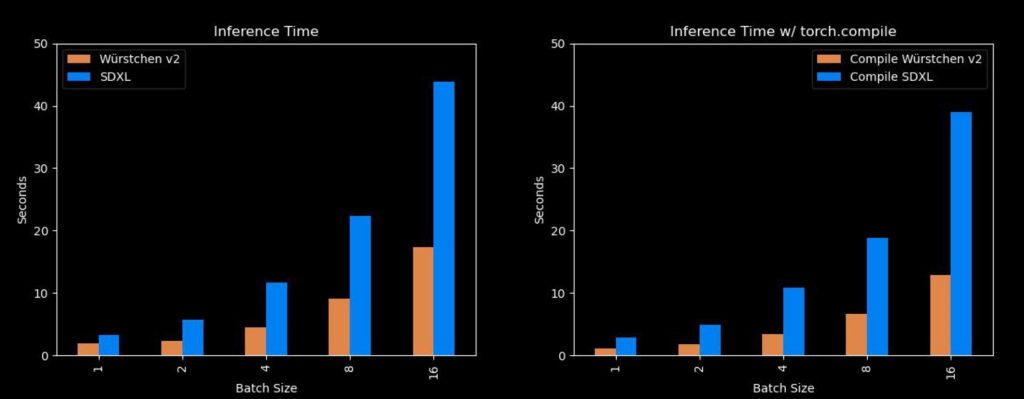
Die Implementierung von Flash Attention in PyTorch 2.0 ist nicht nur ein Upgrade in Bezug auf Effizienz; es erlaubt auch ein gewisses Maß an “Auto-Tuning”. Das heißt, das Modell kann in Echtzeit auf bestimmte Anforderungen reagieren und seine Performance entsprechend anpassen. Dies ist besonders nützlich in Szenarien, in denen die Rechenressourcen variabel sind oder schnelle Anpassungen erforderlich sind.
Kompilierung und Just-in-Time-Optimierung
Die Option, torch.compile zu verwenden, bietet die Möglichkeit für eine Just-in-Time-Kompilierung. Das bedeutet, dass der Code erst zur Laufzeit kompiliert wird, was zu einer optimierten Ausführung führt. Diese Technik ist besonders nützlich in hybriden Umgebungen, in denen sowohl CPU- als auch GPU-Ressourcen verfügbar sind, da sie es dem Modell ermöglicht, die verfügbaren Ressourcen optimal zu nutzen.
Weitere Integrationsmöglichkeiten
Beide Techniken, Flash Attention und torch.compile, sind so konzipiert, dass sie nahtlos mit anderen Optimierungsmethoden und -werkzeugen integriert werden können. Dies ermöglicht eine umfassende Leistungssteigerung, die über das hinausgeht, was durch einzelne Optimierungstechniken erreicht werden kann. So kann beispielsweise Flash Attention mit spezialisierten Hardwarebeschleunigern kombiniert werden, und torch.compile kann mit anderen Laufzeitoptimierungen wie Modell-Pruning kombiniert werden, um noch bessere Ergebnisse zu erzielen.
5. Fazit
Wegbereiter für neue Anwendungsfälle
Würstchen ist nicht nur ein Schritt vorwärts in Bezug auf Effizienz und Schnelligkeit; es könnte als Wegbereiter für ganz neue Anwendungsfälle in der Text-zu-Bild-Generierung dienen. Die geringen Hardware-Anforderungen und die schnelle Inferenz könnten die Tür für Echtzeit-Anwendungen öffnen, die bisher nicht praktikabel waren, wie etwa interaktive Medien oder Augmented-Reality-Erfahrungen.
Demokratisierung der Technologie
Die Kosteneffizienz von Würstchen könnte dazu beitragen, dass Text-zu-Bild-Modelle weit über den Kreis der großen Tech-Unternehmen hinaus verfügbar werden. Dadurch könnten kleinere Entwicklerteams und sogar Einzelpersonen in die Lage versetzt werden, leistungsstarke Modelle zu nutzen und weiterzuentwickeln. Das hat das Potenzial, die Technologie zu demokratisieren und die Innovationsgeschwindigkeit in diesem Bereich zu erhöhen.
Ausblick und Weiterentwicklung
Obwohl Würstchen bereits jetzt beeindruckende Ergebnisse liefert, ist es wahrscheinlich, dass künftige Versionen noch leistungsfähiger und effizienter werden. Die aktive Entwicklergemeinschaft und die Anpassungsfähigkeit des Modells deuten darauf hin, dass wir in den kommenden Jahren mit weiteren Durchbrüchen in der Text-zu-Bild-Technologie rechnen können.
6. Würstchen – Schnelle Diffusion – Ausblick auf weitere Forschung
Würstchen könnte als ein Katalysator für weitere Forschung in den Bereichen Text-zu-Bild-Generierung und Datenkomprimierung fungieren. Die Möglichkeit, qualitativ hochwertige Bilder mit minimaler Rechenleistung zu erzeugen, könnte das Interesse in der wissenschaftlichen Gemeinschaft an Optimierungstechniken für maschinelles Lernen steigern. Außerdem könnten sich aus der Technologie hinter Würstchen neue Forschungsrichtungen im Bereich der Latenzräume oder der Diffusionsmodelle ergeben.
Wirtschaftlicher Ausblick
In der Wirtschaft könnte Würstchen weitreichende Auswirkungen haben. Erstens könnte seine Kosteneffizienz dazu führen, dass Unternehmen mit kleineren Budgets Zugang zu fortschrittlichen Text-zu-Bild-Technologien erhalten. Dies könnte wiederum die Wettbewerbsfähigkeit in verschiedenen Sektoren erhöhen, von der Werbung bis zur Content-Erstellung. Zweitens könnten durch die Erschließung von Echtzeitanwendungen völlig neue Geschäftsmodelle entstehen, beispielsweise in der Spieleindustrie oder im Bereich der virtuellen Realität.
Insgesamt könnte Würstchen nicht nur die Forschung im Bereich des maschinellen Lernens vorantreiben, sondern auch wirtschaftliche Chancen schaffen, die bislang durch die hohen Kosten und die Rechenanforderungen der vorhandenen Modelle begrenzt waren.
Quelle: HugginFace/Würstchen, Würstchen Dokumentation, GitHub, Würstchen Demo
#KI #AI #Würstchen #Diffusionsmodell #Bildgenerierung #VQGAN #Autoencoder #GPU #Effizienz #PyTorch #FlashAttention #TorchCompile #kuenstlicheintelligenz #künstlicheintelligenz
Die 10 besten Alternativen zu ChatGPT findest Du hier!