
ByteDance MegaScale: ByteDance hat mit der Vorstellung von MegaScale einen neuen Meilenstein erreicht. Entstanden aus einer Zusammenarbeit zwischen ByteDance und der Peking University, ist MegaScale ein innovatives System, das die Schulung von Large Language Models (LLMs) auf einem bisher unerreichbaren Niveau ermöglicht. Doch was genau macht MegaScale so besonders, und warum ist es ein Wendepunkt in der KI-Entwicklung?
ByteDance MegaScale – auf einen Blick:
- ByteDance hat mit MegaScale einen neuen Meilenstein in der KI-Entwicklung erreicht.
- MegaScale ist ein innovatives System, das die Schulung von Large Language Models ermöglicht.
- Das System zeichnet sich durch Effizienz und Stabilität aus.
- MegaScale optimiert das Training von LLMs durch eine innovative Modellarchitektur.
- Es nutzt umfassende Parallelismus-Strategien, um die Leistungsfähigkeit der Hardware auszuschöpfen.
- Diagnose- und Wiederherstellungstools gewährleisten die Systemstabilität.
- Die Implementierung von MegaScale in der Praxis zeigt beeindruckende Ergebnisse.
- MegaScale trägt dazu bei, das LLM-Training auf ein neues Niveau zu heben.
- Die Erfahrungen mit MegaScale liefern wichtige Erkenntnisse für die Zukunft der KI-Entwicklung.
- MegaScale symbolisiert einen Paradigmenwechsel in der KI-Trainingstechnologie.
Das Herzstück von ByteDance MegaScale: Eine Kombination aus Effizienz und Stabilität
MegaScale ist zweifelsohne ein Durchbruch in der Welt der Künstlichen Intelligenz, insbesondere im Training von Large Language Models (LLMs). In enger Zusammenarbeit zwischen ByteDance und der Peking University entstanden , hebt es sich deutlich von früheren Ansätzen ab. Die Herausforderung beim Training von LLMs lag bisher nicht nur in der Bereitstellung enormer Rechenkapazitäten, sondern auch in der effizienten und stabilen Nutzung dieser Ressourcen. Genau hier setzt MegaScale an.
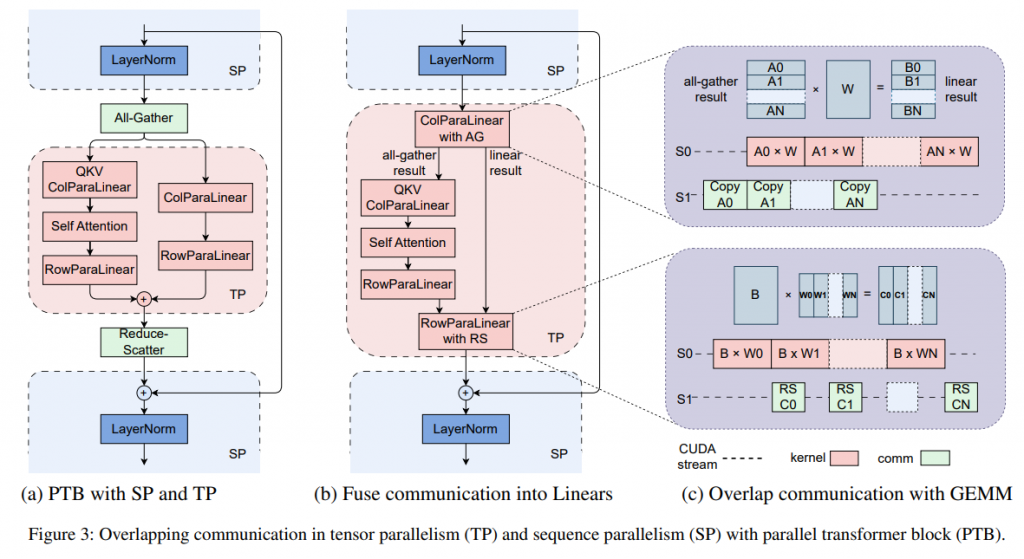
Die Entwickler von ByteDance MegaScale haben das System von Grund auf mit dem Ziel entworfen, die Effizienz und Stabilität des Trainingsprozesses zu maximieren. Dies wurde durch eine ganzheitliche Betrachtung und Optimierung aller Systemkomponenten erreicht. Beginnend bei der Modellarchitektur, über die Datenpipeline bis hin zur Netzwerkleistung, wurde jedes Element sorgfältig darauf abgestimmt, jede verfügbare Rechenleistung optimal zu nutzen.
Ein zentraler Aspekt von ByteDance MegaScale ist die innovative Modellarchitektur. Hier wurden spezielle Transformer-Blöcke und Aufmerksamkeitsmechanismen entwickelt, die darauf abzielen, den Rechenaufwand zu minimieren, ohne die Leistungsfähigkeit des Modells zu beeinträchtigen. Diese Techniken ermöglichen es ByteDance MegaScale, auch bei wachsender Komplexität und Größe der Modelle effizient zu bleiben.
Ein weiterer wichtiger Faktor ist die Optimierung der Datenpipeline. Durch die intelligente Organisation und Verarbeitung der Trainingsdaten minimiert ByteDance MegaScale Verzögerungen und Engpässe, die sonst bei der Skalierung von LLM-Trainings auftreten können. Dies umfasst auch die Verbesserung der Datenübertragung und -verarbeitung zwischen den Tausenden von GPUs, die im ByteDance MegaScale-System zum Einsatz kommen.
Schließlich spielt die Netzwerkleistung eine entscheidende Rolle. ByteDance MegaScale nutzt ein maßgeschneidertes Netzwerkdesign, das speziell auf die Anforderungen von High-Performance-Computing und KI-Training zugeschnitten ist. Dieses Design ermöglicht eine schnelle und effiziente Kommunikation zwischen den GPUs, was essentiell für das Erreichen hoher Trainingsgeschwindigkeiten ist.
ByteDance MegaScale: Optimierungstechniken im Fokus
Bei der Entwicklung von MegaScale wurde ein besonderes Augenmerk auf eine Vielzahl von Optimierungstechniken gelegt, die spezifisch für die Herausforderungen des LLM-Trainings konzipiert sind. Diese Techniken sind entscheidend, um sowohl die Rechenleistung als auch die Effizienz des Systems zu maximieren und gleichzeitig die Komplexität des Trainingsprozesses zu bewältigen.
Fortschrittliche Transformer-Blöcke und Aufmerksamkeitsmechanismen
Eine Schlüsselkomponente von MegaScale sind die parallelen Transformer-Blöcke und Gleitfenster-Aufmerksamkeitsmechanismen. Diese fortschrittlichen Strukturen ermöglichen es dem System, komplexere und größere Modelle effizient zu verarbeiten, indem sie die Notwendigkeit reduzieren, auf alle Teile des Datensatzes gleichzeitig zuzugreifen. Stattdessen konzentrieren sich diese Mechanismen auf relevante Datensegmente, was zu einer deutlichen Verringerung des Rechenaufwands führt.
Umfassende Parallelismus-Strategien
MegaScale nutzt umfassende Parallelismus-Strategien, um die Leistungsfähigkeit der vorhandenen Hardware-Ressourcen voll auszuschöpfen. Dies umfasst Datenparallelismus, bei dem Trainingsdaten auf verschiedene GPUs verteilt werden, Pipeline-Parallelismus, der verschiedene Stufen des Trainingsprozesses auf unterschiedliche Hardware-Einheiten aufteilt, und Tensor-Parallelismus, der die Berechnung großer Tensoren auf mehrere GPUs verteilt. Durch diese Strategien wird sichergestellt, dass jede GPU optimal genutzt wird und Engpässe im Trainingsprozess minimiert werden.
ByteDance MegaScale – Diagnostik und Wiederherstellung als Schlüssel zum Erfolg
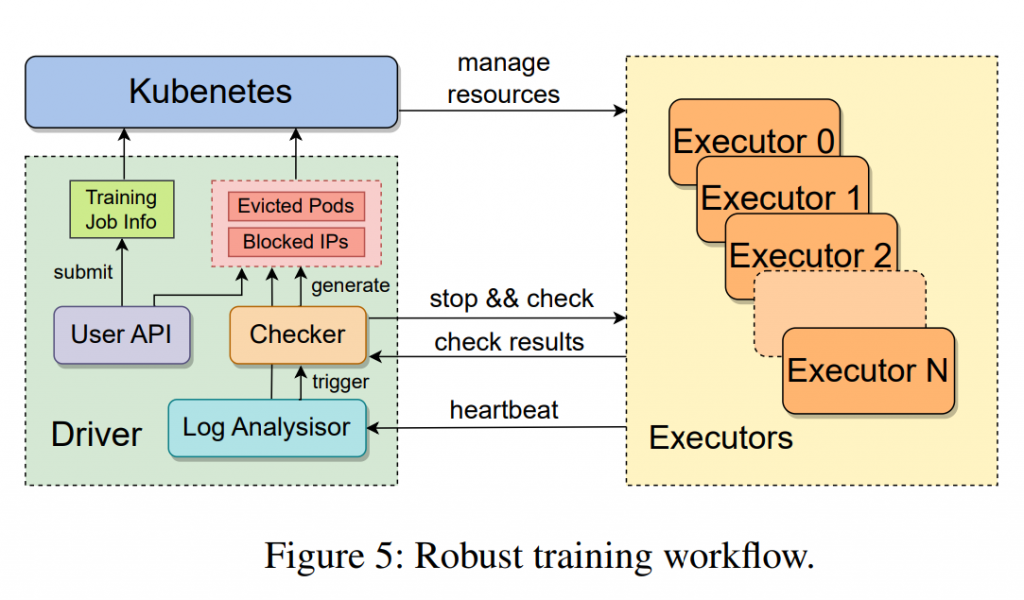
Ein weiterer zentraler Aspekt von ByteDance MegaScale ist das robuste Set an Diagnose- und Wiederherstellungstools. Diese Tools sind entscheidend für die Aufrechterhaltung der Systemstabilität und Effizienz, insbesondere bei der Skalierung auf Tausende von GPUs. Durch die tiefgehende Überwachung der Systemkomponenten und Ereignisse können Fehler schnell identifiziert und behoben werden. Dies beinhaltet auch die Fähigkeit, Systemausfälle und Leistungsabfälle zu erkennen und umgehend Gegenmaßnahmen einzuleiten.
Effizienz und Fehlerbehebung Hand in Hand
Die Kombination aus fortschrittlichen Optimierungstechniken und starken Diagnose- und Wiederherstellungsfähigkeiten macht MegaScale zu einem leistungsstarken Tool für das Training von Large Language Models. Durch die kontinuierliche Überwachung und Anpassung ist das System in der Lage, selbst bei hochkomplexen und datenintensiven Trainingsaufgaben eine hohe Effizienz und Stabilität zu gewährleisten. Diese Fähigkeiten ermöglichen es MegaScale, die Grenzen dessen zu erweitern, was in der Welt des KI-Trainings möglich ist, und legen den Grundstein für die nächste Generation von KI-Anwendungen.
Die Herausforderungen von LLM-Training und ByteDance MegaScale Lösungen
Ungeahnte Skalierungserfordernisse im LLM-Training
Das Training von Large Language Models (LLMs) ist aufgrund seiner Komplexität und des enormen Bedarfs an Rechenkapazität eine gewaltige Herausforderung. Besonders anspruchsvoll wird es, wenn dieses Training auf zehntausende von GPUs skaliert werden muss. Bei einer derartigen Skalierung treten einzigartige Schwierigkeiten auf, die weit über die Anforderungen konventioneller Trainingsmethoden hinausgehen.
Umfassendes Co-Design: Algorithmus trifft Systemarchitektur
Eine der Kernstrategien von MegaScale, um diesen Herausforderungen zu begegnen, ist das algorithmisch-systemische Co-Design. Dieser Ansatz berücksichtigt nicht nur die spezifischen Anforderungen der LLMs, sondern integriert diese Anforderungen tiefgreifend in die Systemarchitektur. Das bedeutet, dass sowohl die algorithmischen Komponenten als auch die Hardware- und Softwareinfrastruktur von Grund auf darauf ausgelegt sind, Hand in Hand zu arbeiten. Diese Symbiose ermöglicht es MegaScale, die Leistungsfähigkeit der GPUs maximal zu nutzen und gleichzeitig die Systemeffizienz zu optimieren.
Tiefgreifende Beobachtbarkeit für fortlaufende Optimierung
Ein weiterer Schlüsselaspekt von MegaScale ist die tiefgreifende Beobachtbarkeit des gesamten Systems. Diese umfasst eine detaillierte Überwachung und Analyse aller Systemkomponenten und -ereignisse. Durch diese intensive Beobachtung können nicht nur Probleme schnell erkannt und behoben, sondern auch Verbesserungspotenziale im Systemlauf identifiziert und ausgeschöpft werden. Diese ständige Überwachung und Anpassung ist entscheidend, um die Stabilität und Effizienz des Trainingsprozesses auch bei der extremen Skalierung aufrechtzuerhalten.
Bewältigung spezifischer Herausforderungen bei der Skalierung
Die Skalierung auf Tausende von GPUs stellt das System vor besondere Herausforderungen wie Netzwerkkongestion, Synchronisationsprobleme und die effiziente Verteilung von Daten und Rechenlasten. MegaScale begegnet diesen Herausforderungen mit innovativen Lösungen, die speziell für solch ein großmaßstäbliches Training entwickelt wurden. Dazu gehören angepasste Netzwerkarchitekturen, fortschrittliche Synchronisationsmechanismen und effiziente Datenverteilungsstrategien, die zusammenarbeiten, um Engpässe zu vermeiden und eine gleichmäßige Lastverteilung zu gewährleisten.
ByteDance MegaScale in der Praxis: Ein Erfahrungsbericht
Umsetzung von MegaScale in realen Trainingsszenarien
Die Implementierung von MegaScale in unseren Rechenzentren stellt einen signifikanten Fortschritt in der Praxis des Trainings von Large Language Models (LLMs) dar. Unsere praktischen Erfahrungen mit MegaScale verdeutlichen die Leistungsfähigkeit und Effizienz dieses Systems, insbesondere beim Training komplexer Modelle.
Beeindruckende Ergebnisse bei der Modell-FLOPs-Nutzung
Ein konkretes Beispiel für die Leistungsfähigkeit von MegaScale ist das Training eines standardmäßigen 175B-Transformator-Modells. Hierbei erreicht das System eine Modell-FLOPs-Nutzung (MFU) von beeindruckenden 55,2%. Diese Zahl ist besonders bemerkenswert, wenn man bedenkt, dass sie eine Steigerung von 1,34× gegenüber dem Open-Source-Trainingsframework Megatron-LM darstellt. Diese Verbesserung in der MFU zeigt deutlich, wie effizient MegaScale die vorhandenen Rechenressourcen nutzt.
Optimierung jenseits der Rechenleistung
Die Verbesserung der MFU ist ein Indikator dafür, dass MegaScale nicht nur die reine Rechenleistung steigert, sondern auch die Effizienz, mit der diese Leistung genutzt wird. Durch die fortschrittlichen Optimierungstechniken und das Co-Design von Algorithmus und Systemarchitektur kann MegaScale die Kapazitäten der GPUs besser ausschöpfen und somit schneller und effektiver trainieren.
Erfahrungen aus dem Einsatz in der Produktumgebung
Der Einsatz von MegaScale in unseren Rechenzentren bietet uns wertvolle Einblicke in die Praxis des LLM-Trainings. Die Erfahrungen zeigen, dass MegaScale nicht nur in der Theorie, sondern auch in der realen Anwendung überzeugt. Die Fähigkeit von MegaScale, komplexe und umfangreiche Modelle effizient zu trainieren, hat direkte Auswirkungen auf die Qualität und Leistungsfähigkeit unserer Produkte.
Zukunftsweisende Impulse für das LLM-Training
Die erfolgreiche Implementierung und die beeindruckenden Ergebnisse von MegaScale in unseren Rechenzentren bestätigen das Potenzial dieses Systems, das LLM-Training auf ein neues Niveau zu heben. Die Erfahrungen mit MegaScale liefern wichtige Erkenntnisse für zukünftige Entwicklungen und Verbesserungen im Bereich des KI-Trainings, was wiederum die Entwicklung innovativer und leistungsfähiger KI-gestützter Produkte vorantreibt.
Fazit: ByteDance MegaScale – Ein Paradigmenwechsel in der KI-Trainingstechnologie
Die Einführung von MegaScale markiert einen entscheidenden Wendepunkt in der Evolution der Künstlichen Intelligenz. Dieses Projekt, entstanden aus der Kooperation zwischen ByteDance und der Peking University, repräsentiert nicht nur einen technologischen Sprung, sondern auch eine neue Denkweise in der Herangehensweise an das Training von Large Language Models (LLMs).
MegaScale hebt sich durch seine ausgeklügelte Kombination aus Effizienz und Stabilität hervor. Diese beiden Elemente sind in der Welt des KI-Trainings nicht nur wünschenswert, sondern absolut essenziell, insbesondere angesichts der wachsenden Komplexität und Größe der Modelle. Durch innovative Modellarchitekturen, die Optimierung der Datenpipeline und ein maßgeschneidertes Netzwerkdesign hat MegaScale bewiesen, dass es möglich ist, die vorhandenen technologischen Ressourcen nicht nur zu nutzen, sondern deren Potenzial vollständig auszuschöpfen.
Die in MegaScale implementierten Optimierungstechniken und Diagnose- sowie Wiederherstellungstools zeigen, dass es durchaus machbar ist, auch unter extremen Bedingungen eine hohe Trainingsleistung aufrechtzuerhalten. Diese technischen Fortschritte unterstreichen die Notwendigkeit, KI-Systeme nicht nur in Bezug auf Rechenleistung, sondern auch in Bezug auf Anpassungsfähigkeit und Resilienz zu entwickeln.
Ein weiterer wichtiger Aspekt von MegaScale ist die Überwindung spezifischer Herausforderungen bei der Skalierung. Die Fähigkeit, große Modelle auf Tausenden von GPUs effizient zu trainieren, ohne dabei an Stabilität zu verlieren, ist ein Meilenstein, der die Tür zu bisher unerreichbaren Möglichkeiten in der KI-Forschung und -Anwendung öffnet.
Die praktische Umsetzung und die daraus resultierenden Erfahrungen mit MegaScale in den Rechenzentren bestätigen nicht nur die theoretischen Überlegungen, sondern zeigen auch, wie solche innovativen Systeme die Entwicklung und Leistungsfähigkeit von KI-Produkten vorantreiben können. Die beeindruckenden Ergebnisse in der Modell-FLOPs-Nutzung demonstrieren, dass MegaScale ein effektives und leistungsfähiges Werkzeug ist, das den Weg für die nächste Generation von KI-Anwendungen ebnet.
Insgesamt symbolisiert MegaScale eine neue Ära in der KI-Trainingslandschaft, in der Effizienz, Skalierbarkeit und Innovation im Mittelpunkt stehen. Die Erkenntnisse und Erfahrungen, die aus MegaScale gewonnen wurden, werden zweifellos die zukünftige Forschung und Entwicklung im Bereich der Künstlichen Intelligenz prägen und inspirieren. MegaScale ist mehr als ein technisches System; es ist ein Leuchtfeuer des Fortschritts in der immer weiter fortschreitenden Welt der Künstlichen Intelligenz.
Quelle: ArXiv, Studien-Paper-PDF
#KuenstlicheIntelligenz #artificialintelligence #KI #AI #ByteDance #MegaScale #LLM #Technologie #Innovation #Forschung #Entwicklung