

Forscher von Amazon haben im Juli 2025 eine neue KI-Architektur vorgestellt, die ein fundamentales Problem großer Sprachmodelle (LLMs) löst: ihre enorme Ineffizienz. Inspiriert von der Funktionsweise des menschlichen Gehirns, wählt das System nur die benötigten neuronalen Module für eine Aufgabe aus. Dieses „dynamische Pruning“ reduziert die Inferenzzeit um bis zu 30 Prozent und senkt die Rechenkosten drastisch, ohne die Genauigkeit zu beeinträchtigen. Damit wird der Weg frei für schnellere, günstigere und intelligentere KI-Anwendungen.
Dieser Ansatz behebt eine der größten Hürden für den breiten Einsatz von Foundation Models. Bisher musste für jede Anfrage das gesamte, gigantische neuronale Netz aktiviert werden – ein enormer Rechenaufwand, vergleichbar mit dem Anwerfen eines Kraftwerks, nur um eine einzelne Glühbirne zum Leuchten zu bringen. Amazons Methode ermöglicht es der KI nun, „on the fly“ zu entscheiden, welche Teile ihres „Gehirns“ sie für eine spezifische Aufgabe wirklich braucht.
Seit Alexa Plus wurde es etwas still beu und Amazon – zumindest bei Science. Alle Infos zu Alexa Plus findest Du hier.
Das Wichtigste in Kürze – Amazons Dynamisches Pruning erklärt
- Inspiriert vom Gehirn: Die KI-Architektur ahmt die Fähigkeit des Gehirns nach, nur spezialisierte Neuronen-Gruppen für bestimmte Aufgaben (wie Sehen oder Hören) zu aktivieren.
- Dynamische Auswahl: Statt das gesamte Netzwerk zu nutzen, wählt ein „Gate Predictor“ kontextabhängig die relevanten Rechenmodule aus und schaltet den Rest ab.
- Messbare Effizienz: Experimente zeigten eine Reduktion der Inferenzzeit um ca. 30 % und eine Senkung der benötigten Rechenoperationen (FLOPs) um über 60 %.
- Gleiche Qualität: Trotz des „Abschaltens“ von Teilen des Modells bleibt die Genauigkeit bei Aufgaben wie Spracherkennung oder Übersetzung auf dem Niveau eines voll aktivierten Modells.
- Bessere Interpretierbarkeit: Die Methode macht sichtbar, welche Teile des Modells für welche Aufgaben (z.B. Deutsch-Transkription vs. Englisch-Übersetzung) spezialisiert sind.
Das Problem: Warum herkömmliche KI-Modelle so ineffizient sind
Foundation Models (FMs), zu denen auch große Sprachmodelle wie GPT-4 oder Claude 3 gehören, sind wahre Alleskönner. Sie können Texte verfassen, Code schreiben, Bilder analysieren und Sprachen übersetzen. Diese Flexibilität hat jedoch einen hohen Preis: Ihre Architektur ist von Natur aus verschwenderisch.
Stell dir ein riesiges Expertenteam vor, in dem jeder einzelne Experte für jede noch so kleine Anfrage mobilisiert wird. Ob du nur wissen willst, wie das Wetter wird, oder eine komplexe wissenschaftliche Abhandlung verfassen lässt – immer arbeitet das gesamte Team mit voller Kraft. Genau das passiert in herkömmlichen KI-Modellen. Alle Neuronen und Parameter werden bei jeder Inferenz – also bei jeder Anfrage – durchlaufen. Das führt zu:
- Hohen Rechenkosten: Die Aktivierung des gesamten Netzes verbraucht Unmengen an Energie und GPU-Leistung.
- Langen Latenzzeiten: Es dauert länger, eine Antwort zu erhalten, weil unnötige Berechnungen durchgeführt werden.
- Skalierungsproblemen: Je größer und fähiger die Modelle werden, desto teurer und langsamer wird ihr Betrieb.
Frühere Versuche, Modelle zu „stutzen“ (Pruning), konzentrierten sich darauf, das Netzwerk einmalig während des Trainings zu verkleinern. Das Problem dabei: Ein so beschnittenes Modell verliert seine Flexibilität und kann sich nicht mehr an unterschiedliche Aufgaben anpassen.

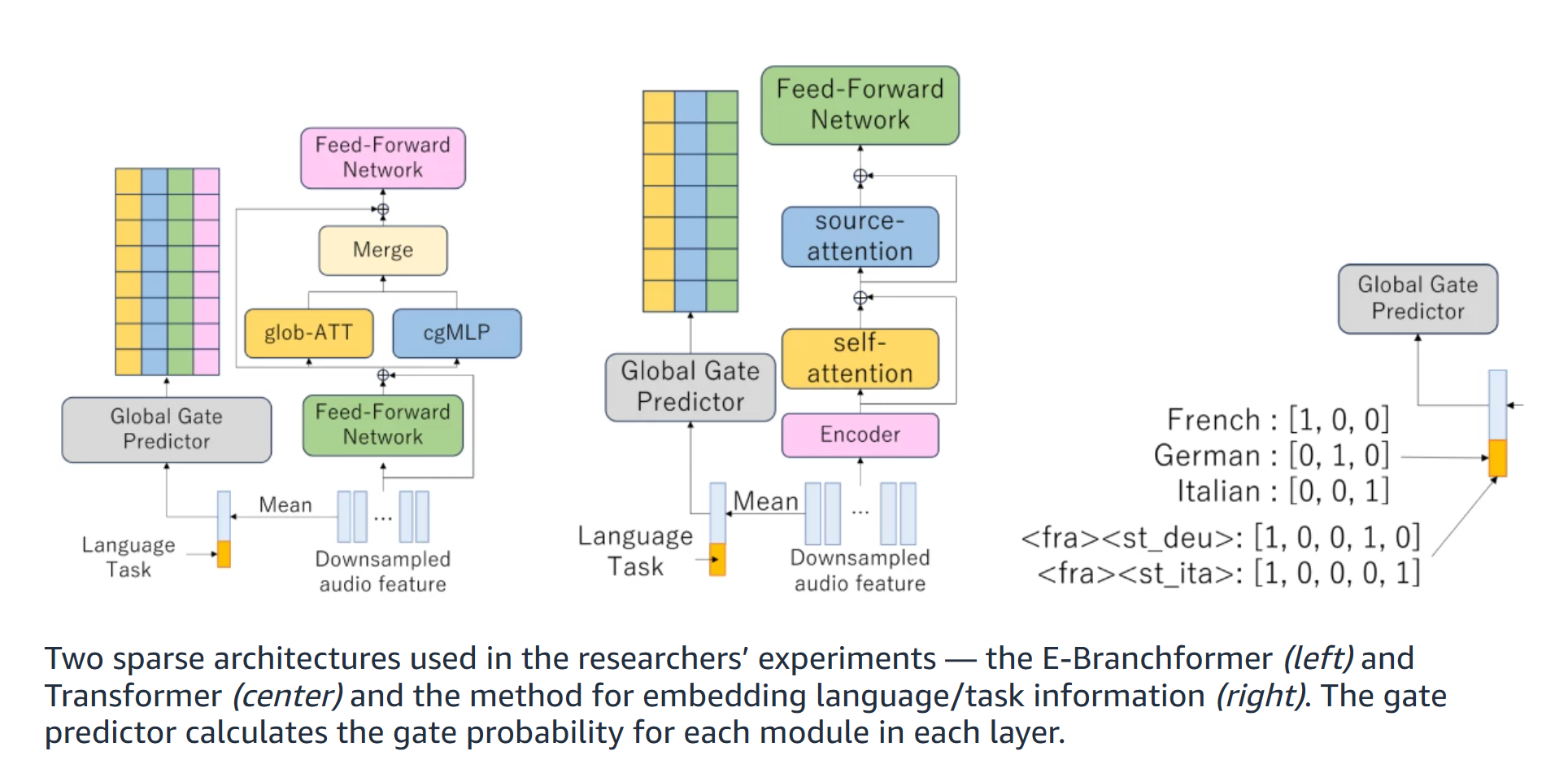
Die Lösung aus der Natur: Dynamisches Pruning nach dem Vorbild des Gehirns
Die Forscher von Amazon wählten einen intelligenteren Weg, inspiriert von der über Jahrmillionen optimierten Effizienz des menschlichen Gehirns. Unser Gehirn aktiviert auch nicht alle Areale gleichzeitig. Wenn du Musik hörst, ist vor allem dein auditorischer Kortex aktiv; wenn du ein Bild betrachtest, der visuelle Kortex.
Genau dieses Prinzip überträgt die neue Architektur auf KI. Das System, vorgestellt auf der renommierten Konferenz ICLR 2025, nutzt ein kontext-abhängiges, dynamisches Pruning.
Anstatt das Modell permanent zu verkleinern, lernt es, für jede einzelne Anfrage in Echtzeit zu entscheiden, welche seiner internen „Module“ (Bündel von Neuronen) für die Lösung relevant sind. Alle anderen Teile bleiben inaktiv. So passt sich das Modell dynamisch an die Sprache (z.B. Deutsch vs. Japanisch), die Aufgabe (Übersetzung vs. Transkription) und andere kontextuelle Hinweise an.
How-To: So funktioniert die intelligente Modulauswahl in 3 Schritten
Der Kern der Innovation ist ein Mechanismus, der wie ein intelligenter Türsteher für die verschiedenen Bereiche des KI-Modells agiert. Der Prozess lässt sich vereinfacht so darstellen:
- Kontext-Analyse: Sobald eine Anfrage eingeht (z.B. ein deutscher Sprachbefehl), analysiert eine kleine, vorgeschaltete Komponente – der „Gate Predictor“ – den Kontext. Er identifiziert Merkmale wie die Sprache („Deutsch“), die Art der Eingabe („Audio“) und die Aufgabe („Transkription“).
- Aktivierungswahrscheinlichkeit berechnen: Basierend auf dem Kontext berechnet der Gate Predictor für jedes einzelne Modul im großen Netzwerk eine „Gate-Wahrscheinlichkeit“. Diese Zahl drückt aus, wie wahrscheinlich es ist, dass dieses spezielle Modul zur Lösung der Aufgabe beiträgt.
- Intelligentes Schalten: Übersteigt die Wahrscheinlichkeit eines Moduls einen vordefinierten Schwellenwert, wird das „Tor“ geöffnet und das Modul aktiviert. Alle Module unterhalb des Schwellenwerts bleiben abgeschaltet. So entsteht ein maßgeschneiderter, hocheffizienter Verarbeitungspfad nur für diese eine Anfrage.
Dieser modulare Ansatz ist entscheidend. Anstatt einzelne, verstreute Neuronen zu entfernen, was für moderne Hardware ineffizient wäre, werden ganze Blöcke (wie Self-Attention- oder Feed-Forward-Netzwerke) übersprungen. Das erhält die strukturelle Integrität des Modells und sorgt für echte Geschwindigkeitsvorteile auf GPUs.
Beeindruckende Ergebnisse: 30 % schneller bei gleicher Qualität
Die von den Forschern Jing Liu, Grant Strimel und ihrem Team durchgeführten Experimente mit mehrsprachigen Sprachmodellen (für Spracherkennung, Übersetzung und Sprachidentifikation) bestätigen die Wirksamkeit des Ansatzes eindrucksvoll.
| Metrik | Herkömmliches Modell (voll aktiviert) | Modell mit dynamischem Pruning | Verbesserung |
| Inferenz-Latenz (Beispiel) | 9,28 Sekunden | 5,22 Sekunden | ~44 % schneller |
| Durchschnittliche Inferenzzeit | 100 % | ~70 % | ~30 % schneller |
| Rechenoperationen (FLOPs) | 100 % | < 40 % | > 60 % weniger |
| Genauigkeit (WER/BLEU) | Kein Abfall | Kein signifikanter Abfall | Vergleichbare Qualität |
Die Ergebnisse zeigen: Es ist möglich, die Rechenlast massiv zu reduzieren, ohne dass der Nutzer einen Qualitätsverlust bemerkt. Laut dem Paper „Context-aware dynamic pruning for speech foundation models“ konnte die Inferenzzeit um rund 30 % reduziert werden, während die Genauigkeit (gemessen in Word Error Rate für Transkription und BLEU-Score für Übersetzung) erhalten blieb.
Willst du tiefer in die Welt der KI-Optimierung eintauchen und erfahren, wie du solche Technologien für deine Projekte nutzen kannst? Unser Newsletter versorgt dich wöchentlich mit den neuesten Praxis-Tipps und Analysen. Melde dich jetzt an und bleibe an der Spitze der Entwicklung!
Einblick ins KI-Gehirn: Was die Methode über das Lernen verrät
Ein faszinierender Nebeneffekt des dynamischen Prunings ist die gewonnene Transparenz. Indem die Forscher beobachten, welche Module bei welchen Aufgaben aktiviert werden, erhalten sie Einblicke in die interne Arbeitsweise und Spezialisierung des KI-Modells.
Sie konnten beispielsweise feststellen, dass für Aufgaben der reinen Spracherkennung (ASR) vor allem Module für die Verarbeitung von lokalem Kontext wichtig sind. Bei der Sprachübersetzung (ST) hingegen werden zusätzlich die Feed-Forward-Netzwerke im Decoder-Teil des Modells entscheidend, da hier komplexere semantische Transformationen stattfinden müssen.
Diese Erkenntnisse sind Gold wert, um KI-Modelle in Zukunft noch gezielter und effizienter zu trainieren und zu verstehen, wie sie „denken“.
Was bedeutet das für dich und die Zukunft der KI?
Auch wenn diese Forschung zunächst im Bereich der Sprach-KI angesiedelt ist, sind die Implikationen weitreichend und betreffen Entwickler, Unternehmen und Endanwender gleichermaßen.
- Für Entwickler & Unternehmen: Geringere Betriebskosten für KI-Anwendungen bedeuten eine niedrigere Eintrittshürde. Komplexe KI-Features werden auch für kleinere Unternehmen und Start-ups erschwinglich.
- Für Endanwender: Du erhältst schnellere Antworten von KI-Assistenten, Chatbots und anderen Diensten. Echtzeitanwendungen wie Simultanübersetzungen werden flüssiger und zuverlässiger.
- Für die Zukunft der KI: Dieser Ansatz ist der Schlüssel zur Skalierung zukünftiger, noch größerer multimodaler Modelle, die gleichzeitig Text, Bild, Audio und Video verarbeiten. Durch dynamisches Pruning können solche gigantischen Modelle überhaupt erst praxistauglich und energieeffizient betrieben werden.
Amazons Architektur zeigt einen Weg auf, wie KI nicht nur leistungsfähiger, sondern auch nachhaltiger und wirtschaftlicher werden kann – ein entscheidender Schritt für die Demokratisierung der Technologie.
Häufig gestellte Fragen – Dynamisches Pruning
Was ist neuronales Pruning bei KI? Neuronales Pruning ist eine Technik zur Optimierung von KI-Modellen, bei der unnötige oder redundante Verbindungen (Neuronen oder ganze Module) aus dem neuronalen Netzwerk entfernt werden. Das Ziel ist es, das Modell kleiner, schneller und effizienter zu machen, ohne seine Leistungsfähigkeit wesentlich zu beeinträchtigen.
Wie kann man die Effizienz von KI-Modellen steigern? Neben dem dynamischen Pruning gibt es weitere Techniken wie die Quantisierung (Reduzierung der Genauigkeit von Zahlen), Wissensdestillation (ein großes Modell trainiert ein kleineres) und die Entwicklung effizienterer Architekturen. Der hier vorgestellte Ansatz von Amazon ist besonders vielversprechend, da er die volle Leistungsfähigkeit des großen Modells erhält und die Effizienz dynamisch zur Laufzeit anpasst.
Was ist die Inferenz bei einer KI? Die Inferenz ist die Phase, in der ein bereits trainiertes KI-Modell genutzt wird, um auf neue Daten oder Anfragen zu reagieren und eine Vorhersage oder Antwort zu generieren. Im Gegensatz zum rechenintensiven Training ist die Effizienz der Inferenz entscheidend für die Praxistauglichkeit und die Kosten einer KI-Anwendung im laufenden Betrieb.
Warum sind LLMs so teuer im Betrieb? Große Sprachmodelle (LLMs) bestehen aus Milliarden von Parametern. Bei jeder Anfrage (Inferenz) müssen traditionell all diese Parameter aktiviert und Berechnungen durchgeführt werden. Dies erfordert extrem leistungsstarke und teure Hardware (GPUs) und verbraucht sehr viel Energie, was die Betriebskosten in die Höhe treibt.
Fazit Amazon Pruning: Intelligente Effizienz als nächster großer Schritt
Amazons Ansatz des kontext-abhängigen, dynamischen Prunings ist mehr als nur eine technische Optimierung; er markiert einen Paradigmenwechsel. Anstatt immer größere und energiehungrigere KI-Modelle zu bauen, liegt der Fokus hier auf intelligenter Ressourcennutzung. Indem wir der KI beibringen, sich wie das Gehirn auf das Wesentliche zu konzentrieren, können wir die KI Effizienz steigern, ohne Kompromisse bei der Leistungsfähigkeit einzugehen.
Die Reduktion der Inferenzzeit um 30 % und der Rechenkosten um über 60 % sind nicht nur beeindruckende Zahlen. Sie sind der Schlüssel, um die nächste Generation von KI-Anwendungen – von blitzschnellen Assistenten bis hin zu komplexen multimodalen Systemen – für alle zugänglich, bezahlbar und nachhaltig zu machen. Dieser vom Gehirn inspirierte „Trick“ könnte sich als eine der wichtigsten Entwicklungen auf dem Weg zu einer wirklich praxistauglichen künstlichen Intelligenz erweisen.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
- Liu, J., & Strimel, G. (2025, Juli 21). Pruning network nodes on the fly to improve LLM efficiency. Amazon Science Blog. https://www.amazon.science/blog/pruning-network-nodes-on-the-fly-to-improve-llm-efficiency
- Someki, M., et al. (2025). Context-aware dynamic pruning for speech foundation models. Amazon Science. https://www.amazon.science/publications/context-aware-dynamic-pruning-for-speech-foundation-models
- Amazon Science
#KIEffizienz #DynamischesPruning #LLM #AmazonAI #FoundationModel #KIArchitektur #KuenstlicheIntelligenz






