

Google hat auf der Cloud Next ’25 einen bedeutenden Schritt nach vorne gemacht und seine neueste Generation von KI-Beschleunigern vorgestellt: den Ironwood Tensor Processing Unit (TPU). Dies ist bereits die siebte Generation der hauseigenen TPUs, aber Ironwood markiert eine Zäsur. Er ist der erste TPU, der von Grund auf speziell für das Zeitalter der Inferenz entwickelt wurde – eine Ära, in der Künstliche Intelligenz nicht mehr nur reagiert, sondern proaktiv denkt, analysiert und Erkenntnisse generiert.
Seit über einem Jahrzehnt treiben TPUs die anspruchsvollsten KI-Trainings- und Bereitstellungs-Workloads bei Google selbst an und ermöglichen dies auch für Cloud-Kunden. Ironwood ist nun der bisher leistungsstärkste, fähigste und energieeffizienteste Chip aus dieser Reihe. Sein erklärtes Ziel: die „denkenden“, inferenziellen KI-Modelle der Zukunft in großem Maßstab zu betreiben. Dieser Artikel taucht tief ein in die Technologie hinter Ironwood, erklärt, was das „Zeitalter der Inferenz“ bedeutet und warum dieser neue Chip so entscheidend für die nächste Welle der KI-Entwicklung ist.

Das musst Du wissen – Google Ironwood TPU im Überblick
- Ironwood ist Googles neueste TPU-Generation (7.), speziell für KI-Inferenz im großen Maßstab optimiert.
- Er soll das „Zeitalter der Inferenz“ einläuten, in dem KI-Modelle proaktiv Erkenntnisse generieren, statt nur Informationen bereitzustellen.
- Bietet beispiellose Skalierbarkeit mit bis zu 9.216 flüssigkeitsgekühlten Chips pro Pod und enorme Rechenleistung (42,5 Exaflops FP8 Peak).
- Zeigt eine deutliche Steigerung der Energieeffizienz (doppelt so effizient wie der Vorgänger Trillium) und massive Verbesserungen bei Speicherkapazität und -bandbreite.
- Ist eine Schlüsselkomponente der Google Cloud AI Hypercomputer Architektur und nutzt die Pathways Software für effiziente verteilte Berechnungen.
Willkommen im Zeitalter der Inferenz: Warum Ironwood jetzt kommt
Der Begriff „Zeitalter der Inferenz“ beschreibt einen fundamentalen Wandel in der Art und Weise, wie wir mit Künstlicher Intelligenz interagieren und was wir von ihr erwarten. Bisher waren viele KI-Anwendungen primär reaktiv. Du stellst eine Frage, die KI sucht und liefert Informationen. Du gibst einen Befehl, die KI führt ihn aus. Das ist zweifellos nützlich, aber es ist nur der Anfang.
Das Zeitalter der Inferenz zielt auf proaktive KI-Modelle ab – Systeme, die wir als „denkend“ bezeichnen könnten. Stell Dir KI-Agenten vor, die nicht nur auf Anfragen warten, sondern selbstständig Daten abrufen, analysieren, interpretieren und dir dann proaktiv maßgeschneiderte Einsichten oder Lösungsvorschläge präsentieren. Diese Modelle gehen über die reine Informationsbereitstellung hinaus; sie generieren neues Wissen und unterstützen bei komplexen Entscheidungsprozessen. Beispiele hierfür sind fortschrittliche Große Sprachmodelle (LLMs), Mixture-of-Experts-Modelle (MoEs), die verschiedene spezialisierte „Experten“-Netzwerke kombinieren, und komplexe Reasoning-Aufgaben, bei denen die KI logische Schlussfolgerungen ziehen muss.
Diese neue Generation von „denkenden“ Modellen stellt jedoch enorme Anforderungen an die zugrundeliegende Infrastruktur. Sie benötigen nicht nur massive parallele Rechenleistung, sondern auch extrem schnellen Zugriff auf riesige Mengen an Speicher und eine hocheffiziente Kommunikation zwischen den Recheneinheiten. Daten müssen blitzschnell bewegt und verarbeitet werden, Latenzen müssen minimiert werden, um die komplexen, oft synchronisierten Operationen dieser Modelle zu bewältigen. Genau hier setzt Ironwood an. Google hat diesen Chip gezielt entwickelt, um diese gewaltigen Rechen- und Kommunikationsanforderungen der Inferenz-Ära zu meistern.

Ironwood Architektur: Gebaut für Skalierung und Spitzenleistung
Um den Anforderungen der „denkenden“ KI gerecht zu werden, wurde Ironwood von Grund auf für massive Parallelverarbeitung und Skalierbarkeit konzipiert. Im Kern steht ein System, das darauf ausgelegt ist, Datenbewegungen und Latenzen auf dem Chip selbst zu minimieren, während gleichzeitig riesige Tensor-Operationen (die mathematische Grundlage vieler KI-Berechnungen) durchgeführt werden.
Da die Rechenanforderungen moderner Modelle die Kapazität eines einzelnen Chips bei weitem übersteigen, hat Google bei Ironwood besonderen Wert auf die Vernetzung gelegt. Die Chips sind über ein bahnbrechendes Inter-Chip Interconnect (ICI) Netzwerk miteinander verbunden. Dieses Netzwerk zeichnet sich durch extrem niedrige Latenz und hohe Bandbreite aus und ermöglicht eine koordinierte, synchrone Kommunikation über das gesamte TPU-Pod hinweg.
Für Google Cloud-Kunden wird Ironwood in zwei Hauptkonfigurationen angeboten, je nach den spezifischen Anforderungen des KI-Workloads:
- Ein Pod mit 256 Chips.
- Ein massives Pod mit 9.216 Chips.
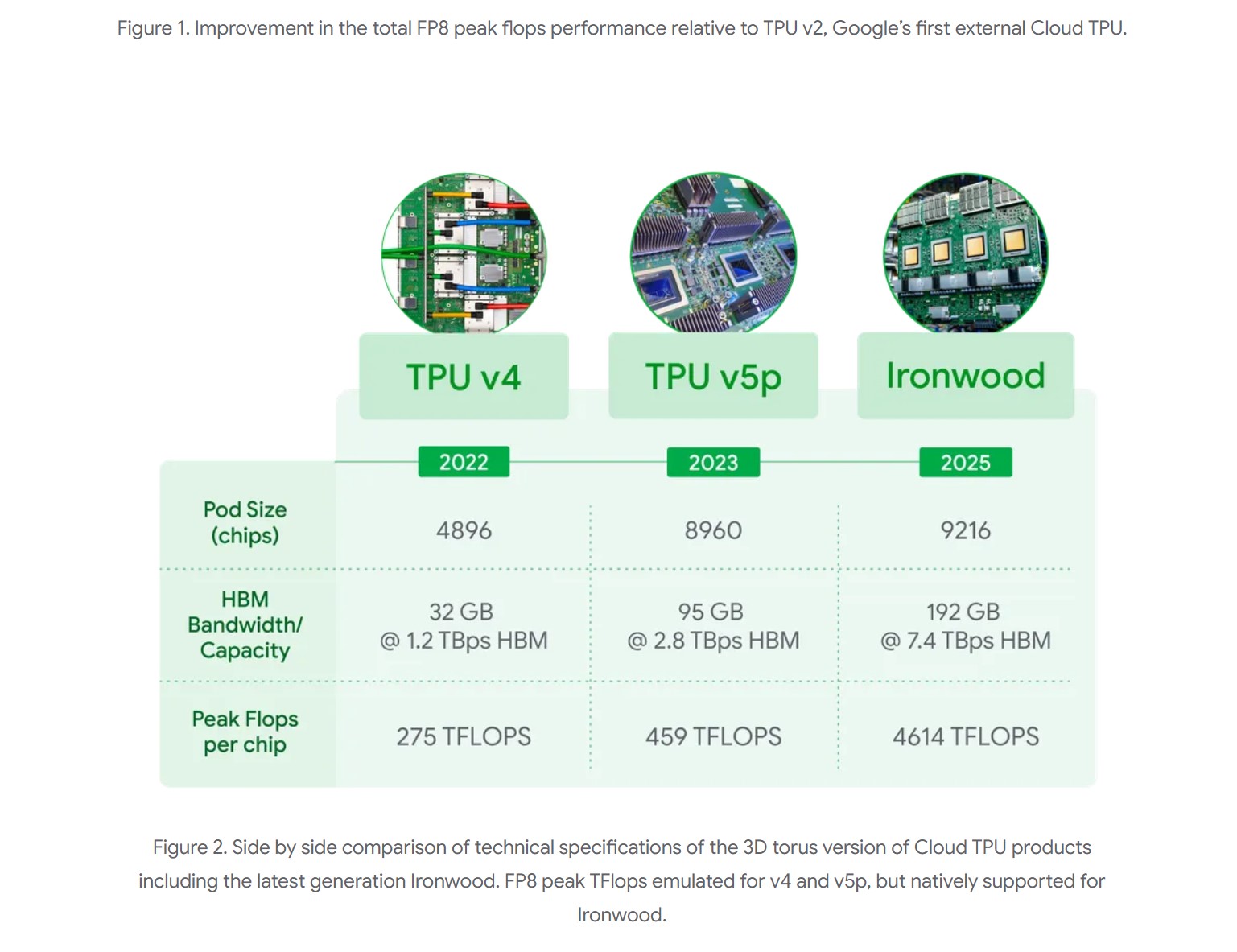
Die größere Konfiguration mit 9.216 Chips ist ein wahres Rechenmonster. Sie erreicht eine Spitzenleistung von 42,5 Exaflops (im FP8-Format, einem für KI optimierten Zahlenformat) und verfügt über eine Gesamtleistung von fast 10 Megawatt, die durch eine fortschrittliche Flüssigkeitskühlung im Zaum gehalten wird. Um diese Zahl in Perspektive zu setzen: Das ist mehr als die 24-fache Rechenleistung des aktuell (Stand Ankündigung) weltgrößten Supercomputers „El Capitan“, der „nur“ 1,7 Exaflops pro Pod bietet. Diese immense Leistung ist notwendig, um die anspruchsvollsten KI-Aufgaben zu bewältigen, wie das Training und die Inferenz von extrem großen, dichten LLMs oder komplexen MoE-Modellen mit „Denkfähigkeiten“. Jeder einzelne Ironwood-Chip trägt dazu mit einer Spitzenleistung von 4.614 TFLOPs (Tera Floating Point Operations per Second) bei.
Doch rohe Rechenleistung allein reicht nicht aus. Die Architektur von Ironwood stellt sicher, dass auch Speicher und Netzwerk mithalten können, damit die Chips stets mit den benötigten Daten versorgt werden und ihre Spitzenleistung auch bei dieser enormen Skalierung aufrechterhalten können.
Ein weiterer wichtiger Bestandteil ist die Integration in die Google Cloud AI Hypercomputer Architektur. Dies ist kein einzelnes Produkt, sondern ein ganzheitlicher Ansatz, der Hardware (wie Ironwood) und Software optimiert zusammenbringt, um die anspruchsvollsten KI-Workloads zu meistern. Ein Schlüsselelement der Softwareseite ist Pathways, der von Google DeepMind entwickelte ML-Runtime-Stack. Pathways ermöglicht effizientes verteiltes Rechnen über Tausende von TPU-Chips hinweg. Für Cloud-Kunden bedeutet dies, dass sie dank Pathways auf Google Cloud relativ einfach über die Grenzen eines einzelnen Ironwood-Pods hinausgehen können. Es wird möglich, die Rechenleistung von Hunderttausenden von Ironwood-Chips zu bündeln, um die Grenzen dessen, was im Bereich generativer KI rechentechnisch möglich ist, weiter zu verschieben.
Technische Sprünge: Was Ironwood unter der Haube hat
Google bringt mehr als ein Jahrzehnt Erfahrung in der Entwicklung und dem Betrieb von KI-Hardware in Ironwood ein – Expertise, die aus dem Betrieb von Diensten wie der Google Suche, Gmail und YouTube für Milliarden von Nutzern gewonnen wurde. Diese Erfahrung spiegelt sich in den Kernmerkmalen von Ironwood wider:
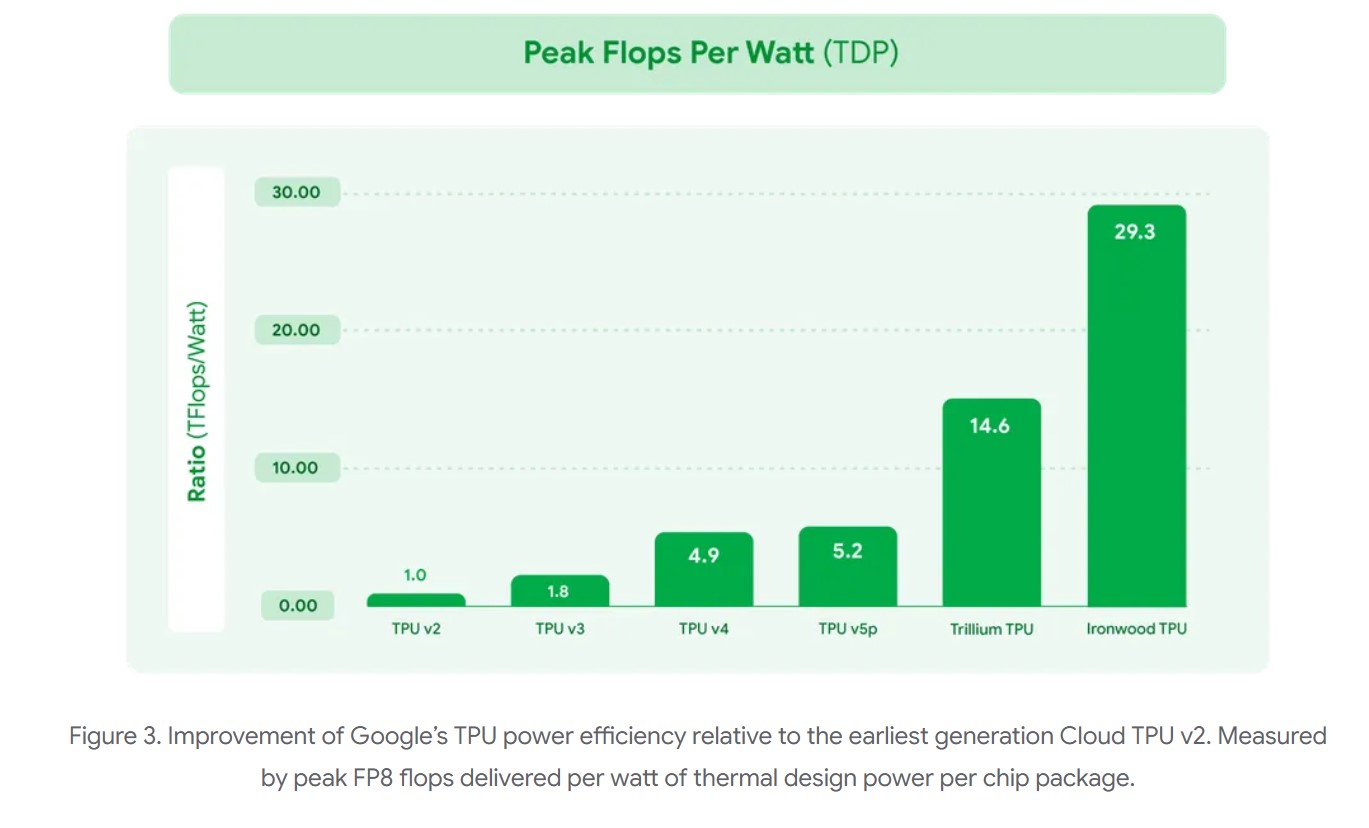
- Leistung und Energieeffizienz: Ironwood erzielt nicht nur signifikante Leistungssteigerungen, sondern legt auch einen starken Fokus auf Energieeffizienz. Das Performance-pro-Watt-Verhältnis (Leistung pro verbrauchtem Watt) ist doppelt so hoch wie beim Vorgänger Trillium (der 6. TPU-Generation, letztes Jahr angekündigt). In einer Zeit, in der die verfügbare Energie zunehmend zu einem limitierenden Faktor für KI-Fortschritte wird, liefert Google hier also deutlich mehr Rechenkapazität pro Watt. Dies macht den Betrieb von KI-Workloads kosteneffektiver und nachhaltiger. Tatsächlich ist Ironwood fast 30-mal energieeffizienter als der erste Cloud TPU (TPU v2) aus dem Jahr 2018.
- Fortschrittliche Flüssigkeitskühlung: Um die hohe Leistungsdichte zu bewältigen und eine zuverlässige Performance zu gewährleisten, setzt Google auf eine fortschrittliche Flüssigkeitskühlung. Diese kann laut Google selbst unter kontinuierlicher, hoher KI-Last bis zu doppelt so viel Leistung zuverlässig aufrechterhalten wie eine Standard-Luftkühlung.
- Massiv erhöhte Speicherkapazität (HBM): Jeder Ironwood-Chip verfügt über 192 Gigabyte High Bandwidth Memory (HBM). Das ist sechsmal mehr als beim Vorgänger Trillium. Diese gewaltige Kapazität ermöglicht die Verarbeitung wesentlich größerer KI-Modelle und Datensätze direkt im schnellen Speicher des Chips. Dadurch werden häufige, zeitaufwändige Datentransfers zwischen dem Chip und externem Speicher reduziert, was die Gesamtleistung erheblich verbessert.
- Drastisch verbesserte Speicherbandbreite (HBM): Nicht nur die Kapazität, auch die Geschwindigkeit des Speicherzugriffs wurde massiv erhöht. Die HBM-Bandbreite erreicht 7,2 Terabyte pro Sekunde (TBps) pro Chip – das ist 4,5-mal mehr als bei Trillium. Diese extrem hohe Bandbreite stellt sicher, dass die Rechenkerne blitzschnell auf die benötigten Daten zugreifen können, was besonders für speicherintensive Workloads moderner KI-Modelle entscheidend ist.
- Verbesserte Inter-Chip Interconnect (ICI) Bandbreite: Die Bandbreite für die direkte Kommunikation zwischen den Chips wurde auf 1,2 Terabit pro Sekunde (Tbps) bidirektional erhöht. Das entspricht einer Steigerung um das 1,5-fache gegenüber Trillium. Diese schnelle Chip-zu-Chip-Verbindung ist essentiell für effizientes verteiltes Training und Inferenz über Tausende von Chips hinweg, da sie die Latenz bei der Synchronisation und dem Datenaustausch minimiert.
- Erweiterter SparseCore: Ironwood verfügt über einen verbesserten „SparseCore“. Dies ist ein spezialisierter Beschleuniger für die Verarbeitung von ultra-großen Embeddings. Embeddings sind numerische Repräsentationen von Daten (wie Wörtern, Produkten oder Nutzern) und spielen eine zentrale Rolle in modernen Empfehlungs- und Ranking-Systemen. Die Erweiterungen im SparseCore von Ironwood erlauben es, ein breiteres Spektrum von Workloads zu beschleunigen, auch über den traditionellen KI-Bereich hinaus, beispielsweise in Finanz- oder wissenschaftlichen Anwendungen.
Diese technischen Fortschritte, zusammenfassend dargestellt in den (im Originalartikel gezeigten) Vergleichsgrafiken zur Leistung und Energieeffizienz über die TPU-Generationen hinweg, unterstreichen Googles kontinuierliches Engagement, die Grenzen der KI-Hardware zu verschieben.
Fazit: Ironwood als Motor für die nächste KI-Revolution
Google Ironwood ist weit mehr als nur ein inkrementelles Upgrade einer bestehenden Hardwarelinie. Es repräsentiert einen gezielten und bedeutenden Schritt in die Zukunft der Künstlichen Intelligenz – eine Zukunft, die maßgeblich vom Konzept der Inferenz geprägt sein wird. Mit seiner speziell für „denkende“ Modelle entwickelten Architektur, der beispiellosen Skalierbarkeit und den massiven Verbesserungen bei Rechenleistung, Speicher und Energieeffizienz adressiert Ironwood die Kernherausforderungen, die mit der nächsten Generation von KI-Anwendungen einhergehen.
Die Fähigkeit, riesige Modelle wie fortschrittliche LLMs und MoEs nicht nur effizient zu trainieren, sondern vor allem auch im großen Maßstab für die Inferenz – also die Anwendung des gelernten Wissens – bereitzustellen, ist der Schlüssel für den Übergang von reaktiven zu proaktiven KI-Systemen. Ironwood liefert die dafür notwendige Infrastruktur. Die Kombination aus roher Rechenleistung (bis zu 42,5 Exaflops pro Pod), extrem hoher Speicherbandbreite (7,2 TBps pro Chip) und Kapazität (192 GB HBM pro Chip) sowie schneller Chip-zu-Chip-Kommunikation (1,2 Tbps ICI) schafft eine Plattform, die darauf ausgelegt ist, die komplexen und datenintensiven Anforderungen dieser neuen Modellklasse zu bewältigen.
Besonders hervorzuheben ist der Sprung in der Energieeffizienz. Die Verdopplung der Leistung pro Watt im Vergleich zum Vorgänger Trillium und die fast 30-fache Verbesserung gegenüber der ersten Cloud-TPU-Generation sind nicht nur aus Kostensicht relevant. Sie sind entscheidend, um dem exponentiell steigenden Energiebedarf von KI-Systemen entgegenzuwirken und KI-Fortschritte nachhaltiger zu gestalten. Die fortschrittliche Flüssigkeitskühlung trägt ebenfalls dazu bei, indem sie eine höhere und zuverlässigere Leistung bei geringerem Energieaufwand ermöglicht als traditionelle Kühlmethoden.
Durch die Integration in die Google Cloud AI Hypercomputer Architektur und die Nutzung der Pathways Software wird Ironwood zu einem mächtigen Werkzeug für Entwickler und Forscher. Die Möglichkeit, Zehn- oder sogar Hunderttausende dieser leistungsstarken Chips nahtlos zu orchestrieren, eröffnet neue Horizonte für die Komplexität und Leistungsfähigkeit von KI-Modellen. Führende Modelle wie Googles eigenes Gemini 2.5 oder das bahnbrechende AlphaFold, das die Proteinfaltung vorhersagt und bereits Nobelpreis-würdige Forschung ermöglicht hat, laufen heute schon auf TPUs. Mit Ironwood wird die Tür für noch weitreichendere Durchbrüche aufgestoßen.
Zusammenfassend lässt sich sagen, dass Ironwood ein klares Bekenntnis von Google zur Zukunft der Inferenz-basierten KI ist. Der Chip löst nicht nur die technischen Herausforderungen von heute, sondern legt das Fundament für die KI-Anwendungen von morgen. Wenn Ironwood später in diesem Jahr (2025) für Google Cloud-Kunden verfügbar wird, dürfen wir gespannt sein, welche neuen Innovationen und KI-Durchbrüche sowohl von Googles eigenen Entwicklern als auch von der breiteren Nutzergemeinschaft damit entfacht werden. Das Zeitalter der denkenden KI hat mit Ironwood einen kraftvollen neuen Motor erhalten.
www.KINEWS24-academy.de – KI. Direkt. Verständlich. Anwendbar.
Quellen
- Google Cloud Blog: Ironwood: The first Google TPU for the age of inference (URL: https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference)
#KI #AI #ArtificialIntelligence #KuenstlicheIntelligenz #IronwoodTPU #GoogleCloud #Inference #AIHardware, Google Ironwood TPU






