
Einleitung – Was ist LongLoRA?
LongLoRA steht für “Long Context Large Language Models Fine-Tuning Approach”. Es ist ein innovativer Ansatz, der entwickelt wurde, um große Sprachmodelle (Large Language Models, kurz LLMs) effizient mit der Fähigkeit auszustatten, lange Kontexte zu verarbeiten. In der Welt der künstlichen Intelligenz ist die Fähigkeit, Kontext zu verstehen, entscheidend für die Leistung von Modellen in zahlreichen Anwendungen, von der Textverarbeitung bis zur automatischen Übersetzung.
Im Kern ist LongLoRA eine Technik, die die bereits vorhandene Architektur von LLMs nutzt und sie durch eine Reihe von Optimierungen und speziellen Algorithmen erweitert. Diese Optimierungen ermöglichen es dem Modell, mehr Informationen aus dem gegebenen Kontext zu extrahieren, ohne die Rechenleistung erheblich zu steigern. Das ist besonders wichtig, da die Verarbeitung langer Texte oft eine Herausforderung für herkömmliche LLMs darstellt, vor allem wenn nur begrenzte Rechenressourcen zur Verfügung stehen.
Warum ist es wichtig?
Die Bedeutung von LongLoRA kann nicht hoch genug eingeschätzt werden, vor allem im Zeitalter der Big Data und komplexen Algorithmen. Zwei Hauptgründe machen diesen Ansatz besonders relevant:
- Effizienzsteigerung: Traditionelle Methoden zur Feinabstimmung von LLMs können sehr rechenintensiv sein. LongLoRA bietet eine Lösung, die nicht nur die Leistung des Modells verbessert, sondern dies auch auf eine ressourceneffiziente Weise tut. Das macht es für Organisationen mit begrenzten Rechenressourcen attraktiv.
- Verbesserte Modellleistung: Durch die Fähigkeit, längere Kontexte zu verarbeiten, kann ein durch LongLoRA optimiertes LLM präzisere und nuanciertere Vorhersagen treffen. Das ist besonders nützlich in komplexen Anwendungen wie der maschinellen Übersetzung, der Textzusammenfassung und der Sentiment-Analyse.
Mit diesen Eigenschaften hat LongLoRA das Potenzial, die Art und Weise, wie wir LLMs einsetzen und entwickeln, grundlegend zu verändern. Es eröffnet neue Möglichkeiten für Forscher und Ingenieure, anspruchsvolle Probleme in der künstlichen Intelligenz effizienter und effektiver zu lösen.
Grundlagen
Was sind Large Language Models (LLMs)?
Large Language Models (LLMs), oder große Sprachmodelle, sind ein Typ von künstlichen Intelligenzmodellen, die darauf spezialisiert sind, menschliche Sprache zu verstehen und zu generieren. Sie sind in der Lage, eine Vielzahl von Aufgaben im Bereich der natürlichen Sprachverarbeitung (NLP) zu bewältigen, darunter Textklassifikation, Textgenerierung, Übersetzung und viele andere. LLMs sind gewöhnlich mit Millionen oder sogar Milliarden von Parametern ausgestattet, was ihnen die Fähigkeit verleiht, komplexe Muster in Daten zu erkennen und daraus zu lernen.
Diese Modelle werden in der Regel auf großen Datensätzen trainiert, die aus Texten unterschiedlichster Art bestehen können, von Nachrichtenartikeln und wissenschaftlichen Abhandlungen bis hin zu sozialen Medien und Konversationsdaten. Das Training eines LLMs ist ein aufwendiger und rechenintensiver Prozess, der spezialisierte Hardware und eine große Menge an Rechenleistung erfordert.
Was bedeutet Feinabstimmung?
Nachdem ein LLM auf einem umfangreichen Datensatz vortrainiert wurde, ist es oft notwendig, das Modell für eine spezielle Aufgabe oder einen speziellen Anwendungsfall weiter zu “tunen”. Dieser Prozess wird als “Feinabstimmung” bezeichnet. Im Kontext der Feinabstimmung wird das bereits trainierte Modell auf einem kleineren, spezialisierten Datensatz weiter trainiert, um es an die Besonderheiten einer spezifischen Aufgabe anzupassen.
Beispielsweise könnte ein LLM, das ursprünglich für Textklassifikation trainiert wurde, durch Feinabstimmung für die spezifische Aufgabe der Sentiment-Analyse von Produktbewertungen optimiert werden. Durch diesen Prozess lernt das Modell, die Nuancen und spezifischen Anforderungen der neuen Aufgabe besser zu verstehen, was in der Regel zu einer verbesserten Leistung führt.
Die Feinabstimmung ist besonders wichtig, da sie es ermöglicht, ein allgemein trainiertes Modell effizient für spezifische Anwendungen oder Branchen anzupassen, ohne den gesamten, oft sehr teuren und zeitaufwendigen Trainingsprozess erneut durchführen zu müssen.
Der LongLoRA-Ansatz
Das Prinzip
LongLoRA baut auf dem Konzept der Feinabstimmung von Large Language Models (LLMs) auf, geht jedoch einen Schritt weiter, indem es eine Möglichkeit bietet, die Kontextgröße dieser Modelle effizient zu erweitern. In einfachen Worten: Es ermöglicht LLMs, mehr Text auf einmal zu “sehen” und “verstehen”, und das mit begrenzten Rechenressourcen.
Anwendungsbeschränkungen durch vorgegebene Kontextgröße: Traditionelle LLMs wie LLaMA und LLaMA2 haben eine vorgegebene Kontextgröße, etwa 2048 Tokens für LLaMA. Diese Beschränkung limitiert ihre Anwendbarkeit in Szenarien, die längere Kontexte erfordern. LongLoRA bietet eine Lösung für dieses spezifische Problem.
Das Hauptprinzip von LongLoRA ist die sogenannte “effiziente Kontexterweiterung”. Traditionelle LLMs haben oft Schwierigkeiten, lange Textabschnitte zu verarbeiten, da sie durch die Architektur und die Anzahl der Parameter begrenzt sind. LongLoRA löst dieses Problem durch den Einsatz von spezialisierten Algorithmen und Optimierungstechniken, die es dem Modell ermöglichen, mehr Informationen aus dem gegebenen Kontext zu extrahieren.
Die Implementierung
Die Implementierung von LongLoRA ist ein komplexer Prozess, der mehrere Schritte umfasst. Zunächst wird das vortrainierte LLM mit einer speziellen Architektur ausgestattet, die für die effiziente Verarbeitung langer Kontexte optimiert ist. Diese neue Architektur wird dann mit speziellen Optimierungsalgorithmen kombiniert, die darauf abzielen, die Rechenleistung zu minimieren, während die Modellleistung maximiert wird.
Ein wichtiger Bestandteil der Implementierung ist die Verwendung von sogenannten “Ausschnitt-Techniken” (Slicing Techniques), die den langen Kontext in kleinere Segmente unterteilen und diese dann separat verarbeiten. Diese Segmente werden später wieder zusammengesetzt, um eine konsistente und umfassende Analyse des gesamten Kontexts zu ermöglichen:
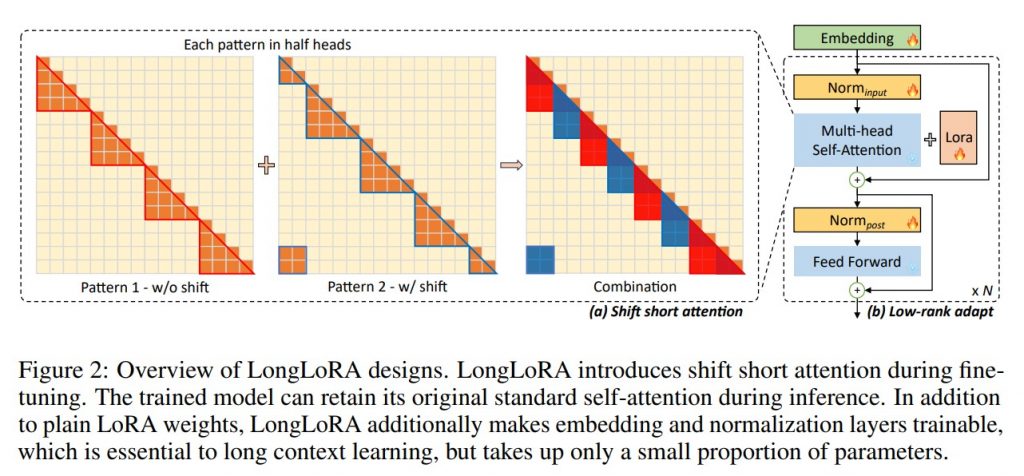
- Shift Short Attention (S²-Attn): Eine der Schlüsseltechniken in LongLoRA ist die sogenannte “Shift Short Attention”, die eine effiziente Kontexterweiterung ermöglicht. Diese Technik führt zu erheblichen Einsparungen bei der Rechenleistung, ohne die Modellperformance wesentlich zu beeinträchtigen.

- Sparse Local vs. Dense Global Attention: Während der Feinabstimmungsphase nutzt LongLoRA “Sparse Local Attention” statt des traditionellen “Dense Global Attention”. Dies trägt zur Effizienz des Modells bei und ermöglicht eine schnellere Anpassung an spezifische Aufgaben.
- Trainable Embedding und Normalization: LongLoRA arbeitet effizient unter der Prämisse von trainierbaren Einbettungen und Normalisierungen, was die Anpassungsfähigkeit und Leistung des Modells weiter verbessert.
- Kompatibilität: LongLoRA ist mit den meisten bestehenden Techniken, wie zum Beispiel FlashAttention-2, kompatibel, was es zu einer vielseitigen Lösung für eine Vielzahl von Anwendungsfällen macht.
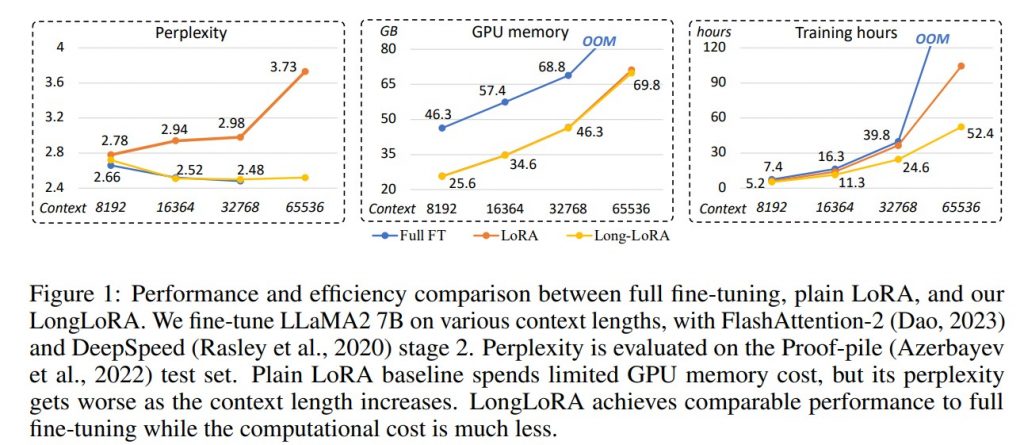
- Perplexity als Evaluationskriterium: Ein weiterer wichtiger Aspekt der Implementierung ist die Evaluation der Modellleistung. LongLoRA wurde hinsichtlich der Perplexität auf dem Proof-pile-Testset bewertet, was als wichtiger Indikator für die Effizienz und Genauigkeit des Modells gilt.
Vorteile und Grenzen
Vorteile
- Effizienz: LongLoRA ermöglicht es, die Leistung von LLMs mit minimaler zusätzlicher Rechenleistung zu steigern.
- Flexibilität: Durch die Fähigkeit, verschiedene Kontextgrößen zu verarbeiten, wird das Modell vielseitiger und kann für eine breitere Palette von Anwendungen eingesetzt werden.
- Vergleich mit anderen Techniken: Im Vergleich zu anderen Feinabstimmungstechniken, die erhebliche Rechenressourcen benötigen, wie z.B. Position Interpolation und FOT, ist LongLoRA wesentlich effizienter. Dies macht es zu einer kostengünstigen Alternative für die Feinabstimmung von LLMs.
Grenzen
- Komplexität: Die Implementierung von LongLoRA erfordert ein tiefes Verständnis der zugrunde liegenden Algorithmen und Optimierungstechniken, was es weniger zugänglich für Einsteiger macht.
- Unbekannte Langzeitwirkungen: Da LongLoRA eine relativ neue Technologie ist, sind die Langzeitwirkungen und -grenzen noch nicht vollständig erforscht.
Anwendungsgebiete
Forschung
In der akademischen Forschung hat LongLoRA das Potenzial, eine Reihe von Disziplinen und Studienfeldern zu revolutionieren. Durch die effiziente Verarbeitung langer Kontexte können Forscher komplexe Probleme in Bereichen wie der natürlichen Sprachverarbeitung, dem maschinellen Lernen und der künstlichen Intelligenz angehen.
Ein konkretes Beispiel wäre die Verbesserung von Textzusammenfassungs-Algorithmen. Traditionelle Modelle stoßen hier oft an ihre Grenzen, da sie nur eine begrenzte Menge an Kontext verarbeiten können. LongLoRA könnte in solchen Szenarien die Fähigkeit des Modells zur Erstellung präziser und informativer Zusammenfassungen erheblich steigern.
Zudem könnte LongLoRA in der Bioinformatik Anwendung finden, wo lange Sequenzen von genetischen Informationen analysiert werden müssen. Die Fähigkeit, lange Kontexte effizient zu verarbeiten, könnte hier zu tieferen Erkenntnissen und schnelleren Forschungsergebnissen führen.
Spezialisierte Datensätze: Für die Feinabstimmung und Evaluierung hat das LongLoRA-Team einen speziellen Datensatz namens “LongQA” erstellt. Dieser Datensatz enthält mehr als 3.000 lange Kontext-Fragen-Antwort-Paare und bietet eine solide Grundlage für die Weiterentwicklung und Beurteilung des Modells.
Vergleich der Rechenressourcen: In der Forschung steht oft nur eine begrenzte Anzahl von Rechenressourcen zur Verfügung. Techniken wie Position Interpolation benötigen beispielsweise bis zu 128 A100 GPUs für die Feinabstimmung. LongLoRA bietet eine effiziente Alternative, die mit weit weniger Ressourcen auskommt.
Industrie
Auch in der Industrie sind die Anwendungsmöglichkeiten von LongLoRA vielfältig. Hier ein paar Beispiele:
- Kundenservice: Chatbots und automatisierte Kundendienstlösungen könnten durch die Verwendung von LongLoRA deutlich verbessert werden. Die Fähigkeit, lange Kundenanfragen oder -gespräche in vollem Umfang zu verstehen, würde die Qualität der automatisierten Antworten erhöhen.
- Content-Erstellung und -Analyse: In der Medienindustrie könnte LongLoRA zur automatischen Erstellung von Artikeln oder zur Analyse von Nutzerkommentaren und -feedback eingesetzt werden. Durch das Verständnis langer Textpassagen könnten nuanciertere und detailliertere Inhalte generiert werden.
- Finanzanalysen: In der Finanzwelt könnten komplexe Berichte und Marktdaten effizienter analysiert werden. LongLoRA könnte dabei helfen, wichtige Informationen aus umfangreichen Dokumenten zu extrahieren und so bessere Investitionsentscheidungen zu ermöglichen.
Potenzielle Stakeholder und Produktinnovationen durch LongLoRA
Für wen ist es wichtig?
Die Forschung rund um LongLoRA ist insbesondere für Unternehmen und Forschungseinrichtungen im Bereich der künstlichen Intelligenz und der natürlichen Sprachverarbeitung von Bedeutung. Da die Technologie eine effizientere und vielseitigere Nutzung von Large Language Models ermöglicht, könnten Organisationen, die bereits in KI und Machine Learning investiert haben, erhebliche Vorteile sehen.
Neue Produktintegrationen
Die Anwendungsmöglichkeiten von LongLoRA sind vielseitig und könnten in einer Reihe von Produkten und Dienstleistungen integriert werden. Zum Beispiel könnten Unternehmen, die Chatbot-Lösungen anbieten, LongLoRA nutzen, um die Effizienz und Genauigkeit ihrer Bots zu steigern. Ebenso könnten Medienunternehmen LongLoRA für die automatische Generierung von Inhalten oder für die Sentiment-Analyse verwenden.
Firmen, die Interesse zeigen könnten
Unternehmen wie Google, OpenAI, und IBM, die bereits stark in den Bereich der künstlichen Intelligenz investiert haben, würden diese Forschung wahrscheinlich sehr interessant finden. Die Möglichkeit, existierende LLMs effizienter und leistungsfähiger zu machen, könnte für diese Unternehmen von strategischer Bedeutung sein, insbesondere im Hinblick auf ihre diversen KI-Anwendungen, von Suchmaschinen bis hin zu Kundenservice-Lösungen.
Fazit
LongLoRA markiert einen wesentlichen Fortschritt in der Entwicklung von Large Language Models, indem es eine effiziente Möglichkeit bietet, die Kontextgröße dieser Modelle zu erweitern. Mit speziellen Techniken wie “Shift Short Attention (S²-Attn)” und “Sparse Local Attention” setzt LongLoRA neue Maßstäbe für die Leistung und Effizienz von LLMs. Insbesondere die Möglichkeit, Modelle im Vergleich zu bestehenden Techniken wie Position Interpolation und FOT effizienter zu tunen, macht LongLoRA zu einer attraktiven Alternative.
In der Forschung und Industrie zeigt LongLoRA sein Potenzial durch die effiziente Verarbeitung komplexer Aufgaben und den Umgang mit spezialisierten Datensätzen wie “LongQA”. Darüber hinaus ermöglicht es die Überwindung der Beschränkungen durch vorgegebene Kontextgrößen, die in traditionellen LLMs wie LLaMA und LLaMA2 existieren.
Während die kurzfristigen Vorteile von LongLoRA offensichtlich sind, erfordert die Technologie weiterhin umfangreiche Forschung, insbesondere im Hinblick auf ihre langfristigen Auswirkungen und Grenzen. Insgesamt stellt LongLoRA jedoch einen vielversprechenden und effizienten Ansatz zur Lösung aktueller Herausforderungen in der Anwendung und Weiterentwicklung von künstlicher Intelligenz dar.
Quelle: ArXiv, Studien-Paper
#LongLoRA #Sprachmodelle #KünstlicheIntelligenz #Feinabstimmung #LLMs #NLP #MachineLearning #Forschung #Industrie #Innovation
Die 10 besten Alternativen zu ChatGPT findest Du hier!
KI im Mittelstand – Jetzt künstliche Intelligenz im Unternehmen nutzen