
TriForce : Wer hätte gedacht, dass die Welt der großen Sprachmodelle – von GPT-4 über Gemini bis hin zu LWM – so anspruchsvoll sein könnte? Diese digitalen Sprachtalente finden von Chatbots, die uns alltägliche Fragen beantworten, bis hin zur Finanzanalyse, wo sie komplexeste Daten durchforsten, überall Einsatz. Doch je länger die Texte, desto größer die Kopfschmerzen… zumindest bisher! Denn je umfangreicher die gewünschten Texte, desto mehr Daten müssen gespeichert werden, was bisher oft zu einem digitalen Verkehrsstau im sogenannten Key-Value (KV) Cache führte.
Aber keine Sorge, Hilfe naht! Forscher von der Carnegie Mellon University und Meta AI (FAIR) präsentieren stolz: TriForce. Dieses schlaue System nutzt eine Art „hierarchische Zauberei“, die es ermöglicht, langatmige Texte schneller als je zuvor zu generieren, ohne dabei ins digitale Stolpern zu kommen. TriForce könnte bald die Art und Weise, wie wir mit KI reden und schreiben, revolutionieren – schneller, effizienter und smarter. Also, anschnallen und Text-Turbo zünden, TriForce nimmt uns mit auf die Überholspur der Textgenerierung!
TriForce – Das musst Du wissen:
Stell dir vor, TriForce ist wie der Turbo-Schalter für deine KI-Textabenteuer. Hier sind ein paar knackige Fakten, warum TriForce das Zeug hat, die KI-Welt zu rocken:
- Turbo-Gedächtnis: TriForce pimpt die bestehenden Tricks (also die Modellgewichte) der KI auf und bringt dynamische, also super anpassungsfähige, sparsame KV-Caches ins Spiel. Das ist wie ein Gedächtnis-Upgrade für die KI, damit sie sich nicht ständig wiederholen muss und schneller wird.
- Doppelt hält besser: Das System ist ein Meister der Effizienz. Es kombiniert flinke, leichte Modelle mit sogenannten StreamingLLM-Caches, die schnell mal eine Vermutung anstellen, was als Nächstes kommt. Das senkt die Wartezeit drastisch, quasi wie wenn du zwei Kassen öffnest, weil sich eine lange Schlange gebildet hat.
- Technomagie mit Transformers und Co.: Dank der smarten Nutzung von Transformers, FlashAttention und PyTorch CUDA-Graphen bleibt unser System voll auf der Höhe, ohne dass die KI ins Schwitzen kommt. Stell dir vor, es ist wie ein Dirigent, der ein riesiges Orchester (die Daten) mit leichter Hand führt und dabei keine Note (Datenbit) verschwendet.
- Speed-Demon im Test: Bei Testläufen hat TriForce gezeigt, was es kann: Eine Beschleunigung um das 2,31-Fache auf A100 GPUs und um atemberaubende 7,78-Fache auf RTX 4090 GPUs. Das ist, als würdest du in einem Sportwagen statt in einem Stadtbus zur Arbeit fahren!
Mit TriForce wird also alles schneller, effizienter und schlauer – bereit, die KI-Texterstellung auf die Überholspur zu bringen!
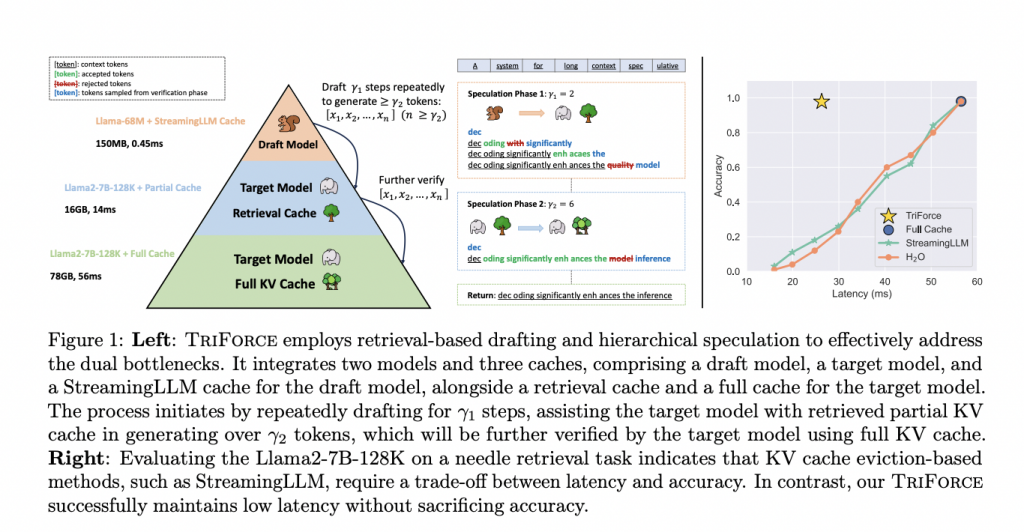
Warum ist diese Forschung herausragend?
Die Entwicklung von TriForce durch das Team der Carnegie Mellon University und Meta AI repräsentiert einen bedeutenden Durchbruch in der Welt der Künstlichen Intelligenz, speziell in der Anwendung und Effizienz großer Sprachmodelle (LLMs). Diese Forschung hebt sich aus mehreren Gründen als herausragend hervor:
- Effizienzsteigerung bei der Textgenerierung: Bisherige Methoden zur Textgenerierung mit LLMs, wie GPT-4 und ähnliche Modelle, leiden unter hohen Latenzzeiten, wenn es um die Generierung längerer Textsequenzen geht. TriForce ermöglicht durch sein innovatives, hierarchisches spekulatives Decodierungssystem eine erheblich schnellere Textgenerierung, ohne dass die Qualität der Ausgabe leidet. Dies wird besonders bei der Verwendung großer Modelle auf Standard-GPUs deutlich, wo TriForce Geschwindigkeitssteigerungen von bis zu 7,94x gegenüber optimierten Basissystemen erreicht.
- Reduktion von Speicheranforderungen: Ein wesentliches Hindernis bei der Skalierung von LLMs ist der enorme Speicherbedarf, der mit längeren Eingaben exponentiell wächst. TriForce adressiert dieses Problem durch eine effiziente Nutzung und dynamische Anpassung des KV-Caches, was den Speicherbedarf drastisch reduziert und so die Anwendung großer Modelle auf herkömmlicher Hardware ermöglicht.
- Erhaltung der Output-Qualität: Viele bisherige Ansätze zur Beschleunigung der Inferenz kompromittieren oft die Qualität der Modelleoutputs. Die spekulative Decodierungsmethode von TriForce, die eine vorläufige, schnelle Generierung durch ein leichteres Modell und eine anschließende Überprüfung durch das Zielmodell nutzt, stellt sicher, dass die Genauigkeit und Kohärenz der Texte erhalten bleibt.
Zukünftiger Einfluss auf Sprachmodelle
Die Implikationen dieser Forschung für zukünftige Sprachmodelle sind vielfältig und signifikant:
- Skalierbarkeit: Mit der Fähigkeit, effizient mit langen Textsequenzen umzugehen, ohne dabei an Geschwindigkeit oder Qualität einzubüßen, setzt TriForce einen neuen Standard für die nächste Generation von LLMs. Dies wird die Türen für breitere Anwendungen in Bereichen öffnen, in denen lange, kohärente und qualitativ hochwertige Texte benötigt werden, wie z.B. in der Literaturerzeugung, im akademischen Schreiben oder in der automatisierten Content-Erstellung.
- Demokratisierung der AI-Nutzung: Durch die Verringerung des erforderlichen Rechenaufwands und Speicherplatzes macht TriForce fortschrittliche LLMs zugänglicher für Einrichtungen und Individuen mit begrenzter Hardware-Kapazität. Dies könnte die Demokratisierung der Nutzung von AI-Technologien fördern, indem es kleineren Unternehmen oder weniger ressourcenstarken Forschern ermöglicht wird, auf diese leistungsstarken Tools zuzugreifen.
- Förderung neuer Forschung: Die Methodik und die Erkenntnisse von TriForce bieten eine neue Grundlage für die akademische Forschung in der Künstlichen Intelligenz, insbesondere im Bereich der effizienten Algorithmenentwicklung und der Optimierung von Rechenprozessen. Dies wird voraussichtlich eine Welle von Innovationen in der AI-Gemeinschaft auslösen, mit dem Ziel, noch schnellere und effizientere Modelle zu entwickeln.
Insgesamt nicht nur verbessert TriForce die technische Leistungsfähigkeit von Sprachmodellen, sondern es erweitert auch deren praktische Anwendbarkeit, was weitreichende Auswirkungen auf Industrie, Forschung und Gesellschaft haben wird. Die Ergebnisse dieser Studie stellen daher einen bedeutenden Schritt nach vorne in der Evolution künstlicher Intelligenz dar.
Effiziente KV-Cache Nutzung ohne Qualitätseinbußen
Die Forschung hat gezeigt, dass bisherige Methoden zur Reduzierung des KV-Cache-Speicherbedarfs oft zu einem Verlust an Generierungsqualität führten. TriForce löst dieses Problem durch eine hierarchische spekulative Decodierung, bei der durch den Einsatz von Retrieval-basierten Draft-Modellen (Entwurfsmodellen) relevante Informationen im KV-Cache effizient segmentiert und genutzt werden. Dies ermöglicht es, den vollen Cache zu erhalten und gleichzeitig die Spekulationseffizienz zu verbessern, was insbesondere bei langen Textsequenzen von Vorteil ist.
Geschwindigkeit trifft Präzision
Das Herzstück von TriForce bildet eine Kombination aus leichten Modellen und einem StreamingLLM-Cache, die zusammen initial spekulieren und so die Latenzzeit drastisch reduzieren. Die vollständige Integration in vorhandene PyTorch-Strukturen mit Unterstützung durch FlashAttention-Technologie und CUDA-Graphen maximiert die Ausführungsgeschwindigkeit, während die Sparsamkeit der Modelle erhalten bleibt. Die herausragende Leistungsfähigkeit zeigt sich besonders beim Offloading auf handelsübliche GPUs wie die RTX 4090, auf denen TriForce eine bis zu 7,94-fache Geschwindigkeitssteigerung gegenüber herkömmlich optimierten Systemen erreicht.
TriForce in Kürze
Blitzschnelle KI mit modernster Technologie:
FlashAttention und CUDA Graphen: TriForce nutzt fortschrittliche Technologien wie FlashAttention und CUDA Graphen, die helfen, die Berechnungen schneller und effizienter zu machen. Diese Techniken reduzieren die notwendige Rechenzeit und verbessern die Nutzung des Speichers, was zu schnelleren Antworten der KI führt.
Hierarchisches Spekulatives Decoding:
Effiziente Struktur: Durch ein clever aufgebautes System aus verschiedenen Modellen kann TriForce sowohl Speicherplatz sparen als auch schneller arbeiten. Es nutzt ein einfacheres „Draft-Modell“ für erste Vorhersagen und ein komplexeres „Zielmodell“ für endgültige Ergebnisse, um präzise und effizient lange Texte zu generieren.
Beeindruckende Leistung in Tests:
Überlegene Geschwindigkeit: Auf modernen RTX 4090 GPUs erreicht TriForce Geschwindigkeiten, die fast acht Mal schneller sind als bei herkömmlichen Systemen, wie z.B. DeepSpeed-Zero-Inference.
Großes Volumen leicht gemacht: Selbst bei der Verarbeitung großer Datenmengen (Batches) bleibt TriForce effizient und erzielt Geschwindigkeitssteigerungen von bis zu 1,9x, insbesondere bei der Bearbeitung von großen Textmengen mit bis zu 19K Kontexten pro Batch.
Robustheit und Skalierbarkeit:
Zuverlässig auch unter Last: TriForce zeigt auch unter hohen Belastungen und bei umfangreichen Datensätzen eine stabile Leistung – ein Beleg für seine Robustheit und Zuverlässigkeit.
Zukunftssicher und anpassungsfähig: Die Technologie ist so gestaltet, dass sie auch bei sehr langen Texten effizient bleibt, mit der theoretischen Möglichkeit, die Geschwindigkeit um mehr als das Dreizehnfache zu steigern.
Überwindung technischer Herausforderungen:
Intelligente Cache-Nutzung: Die geschickte Verwaltung des KV-Caches, eine Art Zwischenspeicher für wichtige Daten, ist entscheidend für die Geschwindigkeit. TriForce aktualisiert diesen Cache geschickt und regelmäßig, was die Antwortzeiten weiter verbessert.
Optimierte Datenblöcke: Durch die Nutzung kleinerer Datenblöcke (“Chunks”) im KV-Cache kann TriForce effizienter wichtige von unwichtigen Informationen trennen, was die Genauigkeit und Schnelligkeit der Textgenerierung erhöht.
Fazit TriForce: Ein großer Sprung nach vorne in der KI-basierten Langtext-Generierung
TriForce stellt einen bedeutenden Fortschritt in der Effizienz und Qualität der Langtext-Generierung durch LLMs dar. Mit signifikanten Geschwindigkeitssteigerungen und einer effizienten Nutzung des KV-Caches setzt es neue Maßstäbe in der KI-basierten Inhaltsproduktion. Die Zukunft könnte weitere Verbesserungen in der Spekulationsgenauigkeit und der Reduktion von Latenzzeiten bringen, womit TriForce das Potenzial hat, die Landschaft der automatisierten Inhaltsproduktion nachhaltig zu prägen.
#KuenstlicheIntelligenz #artificialintelligence #KI #AI #TriForce #LLM #TechInnovation #FutureOfAI #DeepLearning #MachineLearning