
KAIST-Forscher präsentieren VSP-LLM: Ein neuartiges Framework für Künstliche Intelligenz zur Maximierung der Kontextmodellierungsfähigkeit durch die überwältigende Leistung von LLMs
Neuartiges KI-Framework verbessert die visuelle Spracherkennung und -übersetzung durch Nutzung der Kontextmodellierung von Large Language Models
KAIST Spracherkennung: In der visuellen Sprachverarbeitung ist die Fähigkeit zur Kontextmodellierung aufgrund der mehrdeutigen Natur von Lippenbewegungen eine der wichtigsten Voraussetzungen. Zum Beispiel können Homophone, also Wörter, die identische Lippenbewegungen aufweisen, aber unterschiedliche Laute erzeugen, durch die Berücksichtigung des Kontexts unterschieden werden. In diesem Paper stellen die Forscher ein neuartiges Framework vor, nämlich die visuelle Sprachverarbeitung in Verbindung mit LLMs (VSP-LLM), um die Fähigkeit zur Kontextmodellierung durch die überwältigende Leistung von LLMs zu maximieren.
VSP-LLM steht für “Visual Speech Processing incorporated with Large Language Models” und bezeichnet ein neuartiges Framework, das die Fähigkeiten von Large Language Models (LLMs) nutzt, um die Kontextmodellierung in der visuellen Sprachverarbeitung zu verbessern. Entwickelt von Forschern des Korea Advanced Institute of Science and Technology (KAIST), zielt VSP-LLM darauf ab, die Herausforderungen bei der Erkennung von Homophonen – Wörtern mit identischen Lippenbewegungen aber unterschiedlichen Lauten – durch die Integration von visuellen Sprachsignalen und dem Kontextverständnis von LLMs zu bewältigen. Das Framework verwendet ein selbstüberwachtes Modell, um visuelle Sprachmerkmale zu extrahieren und diese in den latenten Raum eines LLM abzubilden.
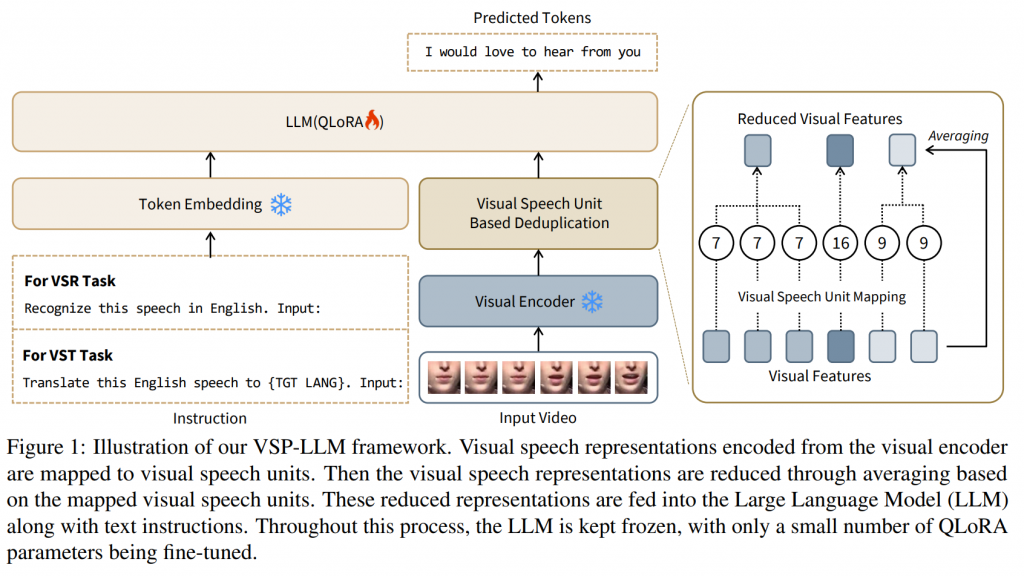
VSP-LLM ist speziell darauf ausgelegt, mit Hilfe von vorgegebenen Anweisungen mehrere Aufgaben der visuellen Spracherkennung und -übersetzung durchzuführen. Das Eingabevideo wird mit Hilfe eines selbstüberwachten visuellen Sprachmodells in den latenten Eingaberaum eines LLM abgebildet. Ausgehend von der Tatsache, dass in den Eingabeframes redundante Informationen vorhanden sind, schlagen wir eine neuartige Deduplizierungsmethode vor, die die eingebetteten visuellen Merkmale unter Verwendung von visuellen Spracheinheiten reduziert.
Durch die vorgeschlagene Deduplizierung und Low Rank Adaptors (LoRA) kann VSP-LLM auf rechnerisch effiziente Weise trainiert werden. Anhand des Übersetzungsdatensatzes MuAViC-Benchmark zeigen wir, dass VSP-LLM Lippenbewegungen mit nur 15 Stunden an gelabelten Daten effektiver erkennen und übersetzen kann als ein kürzlich vorgestelltes Übersetzungsmodell, das mit 433 Stunden gelabelter Daten trainiert wurde.
Lippenbewegungen als entscheidende nonverbale Signale für die Sprachwahrnehmung
Die Sprachwahrnehmung und -interpretation stützt sich stark auf nonverbale Signale wie Lippenbewegungen, die für die menschliche Kommunikation von grundlegender Bedeutung sind. Diese Erkenntnis hat die Entwicklung zahlreicher visuell basierter Sprachverarbeitungsmethoden angestoßen. Zu diesen Technologien gehören die anspruchsvollere visuelle Sprachübersetzung (VST), die Sprache nur anhand visueller Hinweise von einer Sprache in eine andere übersetzt, und die visuelle Spracherkennung (VSR), die gesprochene Wörter nur anhand von Lippenbewegungen interpretiert.
Homophone als Herausforderung für die visuelle Sprachverarbeitung
Die Behandlung von Homophonen, also Wörtern, die unterschiedliche Laute, aber die gleichen Lippenbewegungen haben, ist ein großes Problem in diesem Bereich. Dadurch wird es schwieriger, Wörter nur anhand visueller Hinweise zu unterscheiden und korrekt zu identifizieren. Angesichts ihrer beachtlichen Fähigkeit, Kontexte wahrzunehmen und zu modellieren, haben sich Large Language Models (LLMs) als erfolgreich in einer Reihe von Sektoren erwiesen und ihr Potenzial zur Bewältigung solcher Schwierigkeiten hervorgehoben.
Diese Fähigkeit ist für die visuelle Sprachverarbeitung besonders wichtig, da sie die entscheidende Unterscheidung von Homophonen ermöglicht. Die Kontextmodellierung von LLMs kann die Genauigkeit von Technologien wie VSR und VST verbessern, indem sie die Mehrdeutigkeiten in der visuellen Sprache auflöst.
VSP-LLM: Ein neuartiges Framework zur Integration von LLMs und visueller Sprache
Als Reaktion auf dieses Potenzial hat ein Forscherteam in einer aktuellen Studie ein einzigartiges Framework namens Visual Speech Processing combined with LLM (VSP-LLM) vorgestellt. Dieses Paradigma kombiniert auf kreative Weise das textbasierte Wissen von LLMs mit der visuellen Sprache. Es verwendet ein selbstüberwachtes Modell für visuelle Sprache und übersetzt visuelle Signale in Darstellungen auf Phonemebene. Diese Repräsentationen können dann durch Nutzung der Stärken von LLMs bei der Kontextmodellierung effizient mit Textdaten verknüpft werden.
Um den Rechenanforderungen des Trainings mit LLMs gerecht zu werden, hat diese Arbeit eine Deduplizierungstechnik vorgeschlagen, die darauf abzielt, die Eingabesequenzlängen für LLMs zu verkürzen. Bei diesem Ansatz werden redundante Informationen mit Hilfe von visuellen Spracheinheiten, d. h. diskretisierten Darstellungen von visuellen Spracheigenschaften, erkannt und gemittelt. Dadurch werden die für die Verarbeitung benötigten Sequenzlängen halbiert und die Recheneffizienz verbessert, ohne die Leistung zu beeinträchtigen.
Mit einem gezielten Fokus auf visuelle Spracherkennung und -übersetzung deckt VSP-LLM eine Vielzahl von Anwendungen der visuellen Sprachverarbeitung ab. Aufgrund seiner Anpassungsfähigkeit kann das Framework seine Funktionalität je nach Aufgabenstellung anhand von Anweisungen anpassen. Die Hauptfunktion des Modells besteht darin, eingehende Videodaten mit Hilfe eines selbstüberwachten visuellen Sprachmodells in den latenten Raum eines LLM abzubilden. Durch diese Integration kann VSP-LLM die leistungsstarke Kontextmodellierung von LLMs besser nutzen und so die Gesamtleistung verbessern.
Beeindruckende Ergebnisse auf dem MuAViC Benchmark
Das Team hat mitgeteilt, dass Experimente auf dem Übersetzungsdatensatz MuAViC-Benchmark durchgeführt wurden, die die Wirksamkeit von VSP-LLM gezeigt haben. Das Framework zeigte selbst bei einem Training mit einem kleinen Datensatz von nur 15 Stunden gelabelter Daten eine bessere Leistung als erwartet bei der Erkennung und Übersetzung von Lippenbewegungen. Diese Leistung ist besonders bemerkenswert, wenn man sie mit einem kürzlich vorgestellten Übersetzungsmodell vergleicht, das mit einem etwas größeren Datensatz von 433 Stunden gelabelter Daten trainiert wurde.
5 mögliche Anwendungsszenarien für KAIST:
- Universal Translator: Ein mobiles Gerät, das die Lippenbewegungen des Gesprächspartners in Echtzeit erkennt und in die gewünschte Zielsprache übersetzt. Dies ermöglicht eine reibungslose Kommunikation zwischen Menschen verschiedener Sprachregionen, ohne dass jemand die Fremdsprache beherrschen muss.
- Silent Lectures: Ein System, das in Vorlesungen oder Konferenzen eingesetzt wird, um die Lippenbewegungen des Vortragenden zu erfassen und in Text umzuwandeln. Der generierte Text kann dann für Untertitel, Übersetzungen oder als Zusammenfassung verwendet werden, um die Inhalte einem breiteren Publikum zugänglich zu machen.
- Lip-Reading Assistant: Eine Smartphone-App, die hörgeschädigten Menschen hilft, Gespräche besser zu verstehen, indem sie die Lippenbewegungen des Gesprächspartners in Text umwandelt. Die App könnte auch Echtzeit-Übersetzungen und eine benutzerfreundliche Oberfläche bieten, um die Kommunikation zu erleichtern.
- Covert Communications: Ein System für Sicherheitskräfte oder das Militär, das die Lippenbewegungen aus der Ferne erfasst und in Text umwandelt. Dies ermöglicht eine diskrete Kommunikation in Situationen, in denen Geräusche vermieden werden müssen oder der Einsatz von Audiotechnik nicht möglich ist.
- Virtual Meetings: Eine Videokonferenz-Software, die die Lippenbewegungen der Teilnehmer erkennt und automatisch Untertitel oder Übersetzungen in verschiedene Sprachen generiert. Dies verbessert die Zugänglichkeit und Inklusion in virtuellen Meetings und erleichtert die Zusammenarbeit in internationalen Teams.
Fazit KAIST Spracherkennung
Zusammenfassend lässt sich sagen, dass diese Studie einen wichtigen Fortschritt auf der Suche nach genaueren und integrativeren Kommunikationstechnologien darstellt, die das Potenzial haben, die Zugänglichkeit, die Benutzerinteraktion und das sprachübergreifende Verständnis zu verbessern. Durch die Integration visueller Hinweise und des kontextuellen Verständnisses von LLMs geht VSP-LLM nicht nur die aktuellen Herausforderungen in diesem Bereich an, sondern schafft auch neue Möglichkeiten für Forschung und Anwendung in der Mensch-Computer-Interaktion.
Quelle: ArXiv, Studien-Paper-PDF, GitHub
#KünstlicheIntelligenz #LargeLanguageModels #KontextModellierung #VisuelleSpracherkennung #VisuelleSprachübersetzung #KI #AI #ArtificialIntelligence #KAIST #VSPLLM