
Meta AI – Investition in die GenAI Infrastruktur – Key Facts
- Meta AI kündigt eine bedeutende Investition in die AI-Zukunft von Meta an: zwei 24k GPU-Cluster werden eingeführt. Meta AI teilt Einzelheiten zur Hardware, zum Netzwerk, zur Speicherung, zum Design, zur Leistung und zur Software mit, die dazu beitragen, einen hohen Durchsatz und Zuverlässigkeit für verschiedene AI-Aufgaben zu erzielen. Diese Cluster-Konstruktion wird für das Training von Llama 3 verwendet.
- Meta AI ist stark engagiert in offener Computertechnik und Open-Source-Software. Diese Cluster wurden auf der Basis von Grand Teton, OpenRack und PyTorch aufgebaut, und Meta AI setzt sich weiterhin für offene Innovationen in der gesamten Branche ein. Diese Ankündigung ist ein Schritt auf dem ehrgeizigen Infrastruktur-Fahrplan von Meta AI. Bis Ende 2024 strebt Meta AI an, den Ausbau der Infrastruktur fortzusetzen, der 350.000 NVIDIA H100 GPUs umfassen wird, als Teil eines Portfolios, das eine Rechenleistung äquivalent zu fast 600.000 H100s bieten wird. Führend in der Entwicklung von AI zu sein bedeutet, in Hardware-Infrastruktur zu investieren. Hardware-Infrastruktur spielt eine wichtige Rolle für die Zukunft der KAI.
- Heute teilt Meta AI Einzelheiten über zwei Versionen seines 24.576-GPU-Datenzentrum-Clusters bei Meta mit. Diese Cluster unterstützen die aktuellen und nächsten Generationen von AI-Modellen, einschließlich Llama 3, dem Nachfolger von Llama 2, unserem öffentlich veröffentlichten LLM, sowie AI-Forschung und Entwicklung in Bereichen wie GenAI und anderen.
Ein Einblick in Metas großangelegte KI-Cluster
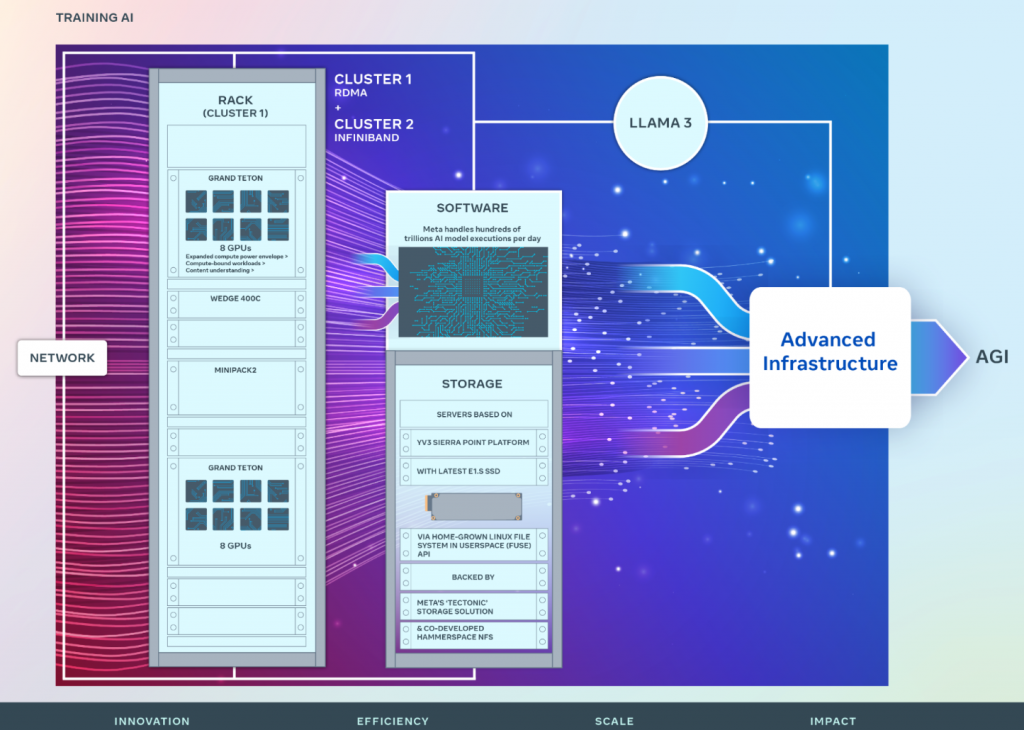
Die langfristige Vision von Meta AI ist es, eine allgemeine künstliche Intelligenz (AGI) zu entwickeln, die offen und verantwortungsvoll aufgebaut ist, sodass sie für jeden weitgehend verfügbar und nutzbar ist. Auf dem Weg zur AGI hat Meta AI auch an der Skalierung seiner Cluster gearbeitet, um diesen Ehrgeiz zu unterstützen. Die Fortschritte, die Meta AI auf dem Weg zur AGI macht, schaffen neue Produkte, neue AI-Funktionen für unsere App-Familie und neue AI-zentrierte Computergeräte.
Obwohl Meta AI eine lange Geschichte im Aufbau von AI-Infrastruktur hat, teilte das Unternehmen erstmals 2022 Einzelheiten über seinen AI Research SuperCluster (RSC) mit, der 16.000 NVIDIA A100 GPUs umfasst. RSC hat die offene und verantwortungsbewusste AI-Forschung von Meta AI beschleunigt, indem es half, die erste Generation fortschrittlicher AI-Modelle zu entwickeln. RSC spielte und spielt weiterhin eine wichtige Rolle in der Entwicklung von Llama und Llama 2 sowie fortgeschrittenen AI-Modellen für Anwendungen, die von Computer Vision, NLP und Spracherkennung bis hin zur Bildgenerierung und sogar zum Codieren reichen.
Unter der Haube
Unter der Haube der neueren AI-Cluster baut Meta auf den Erfolgen und den gelernten Lektionen von RSC auf. Meta AI konzentrierte sich auf den Aufbau von End-to-End-AI-Systemen mit einem großen Schwerpunkt auf Forscher- und Entwicklererfahrung und Produktivität. Die Effizienz der Hochleistungs-Netzwerkgewebe innerhalb dieser Cluster, einige der Schlüsselentscheidungen zur Speicherung, kombiniert mit den 24.576 NVIDIA Tensor Core H100 GPUs in jedem Cluster, ermöglichen es beiden Cluster-Versionen, Modelle zu unterstützen, die größer und komplexer sind als die, die im RSC unterstützt werden konnten, und bereiten den Weg für Fortschritte in der GenAI-Produktentwicklung und AI-Forschung.
Netzwerk
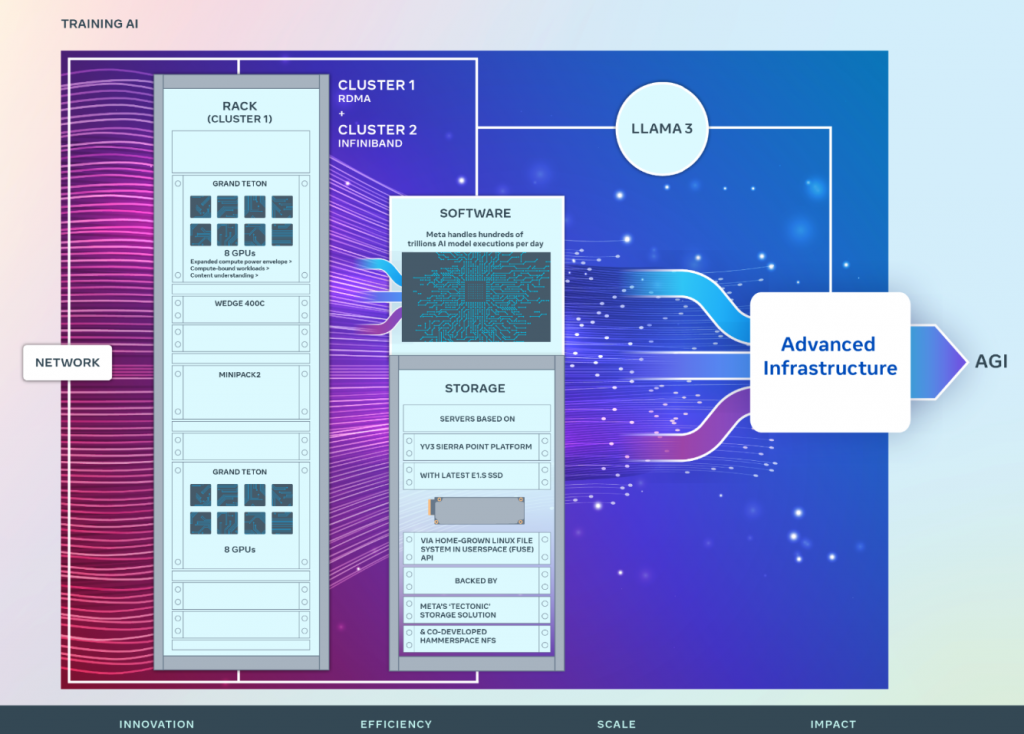
Bei Meta AI werden täglich Hunderte von Billionen von AI-Modellausführungen gehandhabt. Die Bereitstellung dieser Dienste in großem Maßstab erfordert eine hochentwickelte und flexible Infrastruktur. Das eigene Design eines Großteils unserer Hardware, Software und Netzwerkstoffe ermöglicht es Meta AI, das End-to-End-Erlebnis für unsere AI-Forscher zu optimieren und gleichzeitig effizient zu arbeiten. In diesem
Sinne baute Meta AI einen Cluster mit einer Remote Direct Memory Access (RDMA) über Converged Ethernet (RoCE) Netzwerkstofflösung, basierend auf dem Arista 7800 mit Wedge400 und Minipack2 OCP-Rack-Switches. Der andere Cluster verfügt über ein NVIDIA Quantum2 InfiniBand-Gewebe. Beide Lösungen verbinden 400 Gbps-Endpunkte miteinander. Mit diesen beiden kann Meta AI die Eignung und Skalierbarkeit dieser verschiedenen Arten von Verbindungen für großangelegtes Training beurteilen, was mehr Einblicke gibt, die dabei helfen werden, zukünftig noch größere, skalierte Cluster zu entwerfen und zu bauen. Durch sorgfältiges Co-Design des Netzwerks, der Software und der Modellarchitekturen konnte Meta AI sowohl die RoCE- als auch die InfiniBand-Cluster erfolgreich für große GenAI-Workloads einsetzen (einschließlich des laufenden Trainings von Llama 3 auf unserem RoCE-Cluster), ohne jegliche Netzwerkengpässe.
Rechenleistung
Beide Cluster wurden unter Verwendung von Grand Teton gebaut, einer von Meta AI in Eigenregie entworfenen, offenen GPU-Hardwareplattform, die Meta AI zum Open Compute Project (OCP) beigesteuert hat. Grand Teton baut auf vielen Generationen von AI-Systemen auf, die Stromversorgung, Steuerung, Rechenleistung und Stoffinterfaces in einem einzigen Chassis integrieren, um eine bessere Gesamtleistung, Signalintegrität und thermische Leistung zu erzielen. Es bietet schnelle Skalierbarkeit und Flexibilität in einem vereinfachten Design, sodass es schnell in Datenzentrumflotten eingesetzt und leicht gewartet und skaliert werden kann. Kombiniert mit anderen hausinternen Innovationen wie der Open Rack-Stromversorgung und der Rack-Architektur ermöglicht Grand Teton es Meta AI, neue Cluster zu bauen, die speziell für aktuelle und zukünftige Anwendungen bei Meta entwickelt wurden.
Meta AI begann 2015 mit dem offenen Design seiner GPU-Hardwareplattformen, beginnend mit der Big Sur-Plattform.
Speicherung
Speicherung spielt eine wichtige Rolle im AI-Training, ist aber eines der am wenigsten besprochenen Aspekte. Da die GenAI-Trainingsaufgaben mit der Zeit multimodaler werden und große Mengen an Bild-, Video- und Textdaten verbrauchen, wächst der Bedarf an Datenspeicherung schnell. Die Notwendigkeit, all diese Datenspeicherung in einem leistungsstarken, aber dennoch energieeffizienten Fußabdruck unterzubringen, bleibt jedoch bestehen, was das Problem interessanter macht.
Meta AIs Speicherungsbereitstellung adressiert die Daten- und Checkpointing-Anforderungen der AI-Cluster über eine hausinterne Linux Filesystem in Userspace (FUSE) API, die von einer Version von Metas ‘Tectonic’-verteilten Speicherlösung unterstützt wird, die für Flash-Medien optimiert ist. Diese Lösung ermöglicht es Tausenden von GPUs, Checkpoints auf synchronisierte Weise zu speichern und zu laden (eine Herausforderung für jede Speicherlösung), und bietet gleichzeitig eine flexible und hochdurchsatzfähige exabytegroße Speicherung, die für das Datenladen erforderlich ist.
Meta AI hat auch eine Partnerschaft mit Hammerspace eingegangen, um ein paralleles Netzwerkdateisystem (NFS) für diesen AI-Cluster gemeinsam zu entwickeln und zu implementieren. Unter anderem ermöglicht Hammerspace Ingenieuren, interaktives Debugging für Jobs durchzuführen, die Tausende von GPUs nutzen, da Codeänderungen sofort allen Knoten innerhalb der Umgebung zugänglich sind. Zusammen bieten die Kombination aus Metas Tectonic verteilter Speicherlösung und Hammerspace eine schnelle Iterationsgeschwindigkeit, ohne dabei auf Maßstab zu verzichten.
Die Speicherungsbereitstellungen in Metas GenAI-Clustern, sowohl Tectonic- als auch Hammerspace-gestützt, basieren auf der YV3 Sierra Point-Serverplattform, die mit den neuesten hochkapazitiven E1.S-SSDs, die derzeit auf dem Markt erhältlich sind, aufgerüstet wurde. Neben der höheren SSD-Kapazität wurde die Anzahl der Server pro Rack angepasst, um das richtige Gleichgewicht zwischen Durchsatzkapazität pro Server, Reduzierung der Rackanzahl und zugehöriger Energieeffizienz zu erreichen. Indem OCP-Server als Lego-ähnliche Bausteine verwendet werden, kann die Speicherschicht von Meta AI flexibel auf zukünftige Anforderungen in diesem Cluster sowie in zukünftigen, größeren AI-Clustern skalieren, während sie fehlertolerant gegenüber alltäglichen Infrastrukturwartungsarbeiten bleibt.
Leistung
Eines der Prinzipien beim Bau unserer groß angelegten AI-Cluster ist es, gleichzeitig maximale Leistung und Benutzerfreundlichkeit zu maximieren, ohne das eine für das andere zu opfern. Dies ist ein wichtiges Prinzip bei der Erstellung von erstklassigen AI-Modellen.
Während Meta AI die Grenzen von AI-Systemen auslotet, besteht der beste Weg, Metas Fähigkeit zum Skalieren der Designs zu testen, darin, einfach ein System zu bauen, es zu optimieren und dann tatsächlich zu testen (obwohl Simulatoren helfen, reichen sie nur so weit). Auf dieser Designreise verglich Meta AI die Leistung in kleinen Clustern mit der in großen Clustern, um Engpässe zu identifizieren. Im untenstehenden Diagramm wird die AllGather-Kollektivleistung dargestellt (als normalisierte Bandbreite auf einer Skala von 0-100), wenn eine große Anzahl von GPUs miteinander bei Nachrichtengrößen kommuniziert, bei denen eine Dachleistungsleistung erwartet wird.
Die Out-of-Box-Leistung für große Cluster war anfangs schlecht und inkonsistent im Vergleich zur optimierten Leistung kleiner Cluster. Um dies zu adressieren, nahm Meta AI mehrere Änderungen an der Art und Weise vor, wie der interne Job-Scheduler Jobs mit Netzwerktopologiebewusstsein plant – dies führte zu Latenzvorteilen und minimierte die Menge des Verkehrs, der in die oberen Schichten des Netzwerks gelangt. Meta AI optimierte auch seine Netzwerk-Routing-Strategie in Kombination mit Änderungen an der NVIDIA Collective Communications Library (NCCL), um eine optimale Netzwerkauslastung zu erreichen. Dies half, die großen Cluster von Meta AI dazu zu bringen, eine großartige und erwartete Leistung zu erreichen, genauso wie die kleinen Cluster.
Neben Softwareänderungen, die auf unsere interne Infrastruktur abzielen, arbeitete Meta AI eng mit Teams zusammen, die Trainingsframeworks und -modelle entwickeln, um sich an unsere sich entwickelnde Infrastruktur anzupassen. Beispielsweise eröffnen NVIDIA H100 GPUs die Möglichkeit, neue Datentypen wie 8-Bit-Gleitkommazahl (FP8) für das Training zu nutzen. Die vollständige Nutzung größerer Cluster erforderte Investitionen in zusätzliche Parallelisierungstechniken, und neue Speicherlösungen boten die Möglichkeit, Checkpointing über Tausende von Rängen hochgradig zu optimieren, um in Hunderten von Millisekunden abzulaufen.
Meta AI erkennt auch die Debuggbarkeit als eine der größten Herausforderungen beim Training in großem Maßstab. Die Identifizierung einer problematischen GPU, die einen gesamten Trainingsjob zum Stillstand bringt, wird in großem Umfang sehr schwierig. Meta AI entwickelt Tools wie Desync-Debug oder einen verteilten kollektiven Flugdatenschreiber, um Einzelheiten des verteilten Trainings offenzulegen und Probleme auf viel schnellere und einfachere Weise zu identifizieren.
Schließlich entwickelt Meta AI PyTorch, das grundlegende AI-Framework, das unsere AI-Workloads antreibt, weiter, um es für das Training mit Zehntausenden oder sogar Hunderttausenden von GPUs bereit zu machen. Meta AI hat mehrere Engpässe bei der Initialisierung von Prozessgruppen identifiziert und die Startzeit von manchmal Stunden auf Minuten reduziert.
Verpflichtung zu offener KI-Innovation
Meta AI bleibt seinem Engagement für offene Innovationen in AI-Software und -Hardware treu. Meta AI glaubt, dass offene Hardware und Software immer ein wertvolles Werkzeug sein werden, um der Branche zu helfen, Probleme in großem Maßstab zu lösen.
Heute unterstützt Meta AI weiterhin offene Hardware-Innovationen als Gründungsmitglied des OCP, wo Designs wie Grand Teton und Open Rack der OCP-Gemeinschaft zur Verfügung gestellt werden. Meta AI bleibt auch der größte und primäre Beitragende zu PyTorch, dem AI-Software-Framework, das einen großen Teil der Branche antreibt.
Meta AI bleibt auch der offenen Innovation in der AI-Forschungsgemeinschaft verpflichtet. Meta AI hat die Open Innovation AI Research Community gestartet, ein Partnerschaftsprogramm für akademische Forscher, um unser Verständnis davon zu vertiefen, wie man AI-Technologien verantwortungsbewusst entwickelt und teilt – mit einem besonderen Fokus auf LLMs.
Ein offener Ansatz für AI ist für Meta AI nicht neu. Meta AI hat auch die AI Alliance ins Leben gerufen, eine Gruppe führender Organisationen in der AI-Branche, die sich darauf konzentriert, verantwortungsvolle Innovationen in AI innerhalb einer offenen Gemeinschaft zu beschleunigen. Die AI-Bemühungen von Meta AI basieren auf einer Philosophie der offenen Wissenschaft und der Zusammenarbeit über verschiedene Bereiche hinweg. Ein offenes Ökosystem bringt Transparenz, Prüfung und Vertrauen in die Entwicklung von AI und führt zu Innovationen, von denen jeder profitieren kann und die mit Sicherheit und Verantwortung im Vordergrund gebaut werden.
Die Zukunft der KI-Infrastruktur von Meta
Diese beiden AI-Trainingscluster-Designs sind Teil des größeren Fahrplans von Meta AI für die Zukunft der AI. Bis Ende 2024 zielt Meta AI darauf ab, den Ausbau seiner Infrastruktur fortzusetzen, der 350.000 NVIDIA H100s als Teil eines Portfolios umfassen wird, das eine Rechenleistung äquivalent zu fast 600.000 H100s bieten wird.
Wenn Meta AI in die Zukunft blickt, erkennt das Unternehmen, dass das, was gestern oder heute funktioniert hat, möglicherweise nicht ausreichend für die Bedürfnisse von morgen ist. Deshalb bewertet und verbessert Meta AI ständig jeden Aspekt seiner Infrastruktur, von den physischen und virtuellen Schichten bis hin zur Softwareebene und darüber hinaus. Ziel ist es, flexible und zuverlässige Systeme zu schaffen, die die schnell fortschreitenden neuen Modelle und Forschungen unterstützen.
Fazit Meta AI – Investition in die GenAI Infrastruktur
Meta AI setzt mit seinen zwei neuen 24k GPU-Trainingsclustern einen Meilenstein in der Entwicklung fortschrittlicher AI-Technologien. Die Integration von Grand Teton, Open Rack und PyTorch in diese Infrastruktur spiegelt das Engagement von Meta AI für offene Compute- und Open-Source-Lösungen wider. Mit dem Ziel, bis Ende 2024 über 350.000 NVIDIA H100 GPUs zu verfügen, demonstriert Meta AI seine führende Rolle in der AI-Industrie. Die Innovationen in den Bereichen Rechenleistung, Speicherung und Netzwerkoptimierung stellen sicher, dass Meta AI an der Spitze der Entwicklung allgemeiner künstlicher Intelligenz und der Erforschung von LLMs bleibt. Dieser Weg ebnet den Weg für eine Zukunft, in der AI noch leistungsfähiger, zugänglicher und vernetzter ist, um innovative Lösungen für komplexe Herausforderungen anzubieten.
Quelle: Meta
#KuenstlicheIntelligenz #artificialintelligence #KI #AI #Technology #Innovation #METAAI