
Einleitung Meta AI V-JEPA
Meta AI V-JEPA: Stell dir eine Technologie vor, die nicht nur sieht, sondern versteht – eine Künstliche Intelligenz, die die komplexe Dynamik unserer Welt durch einfache Beobachtung begreift. Genau das verspricht Meta AI mit der Einführung von V-JEPA, einem Modell, das die Tür zu einer neuen Ära der Maschinenintelligenz aufstößt. Doch was macht V-JEPA so besonders, und warum könnte es unsere Zukunft maßgeblich beeinflussen?
Hintergrund Meta AI V-JEPA
Um die Bedeutung von V-JEPA zu erfassen, müssen wir zunächst verstehen, was Künstliche Intelligenz eigentlich ist. KI ist das Streben, Maschinen zu erschaffen, die denken, lernen und handeln können wie Menschen. Von den Anfängen in den 1950er Jahren bis heute hat sich das Feld rasant entwickelt, von simplen Programmen bis hin zu Systemen, die komplexe Probleme lösen können. Aktuelle Trends in der KI-Forschung fokussieren sich auf das Verstehen und Interagieren mit der physischen Welt, ein Bereich, in dem V-JEPA eine Pionierrolle einnimmt.
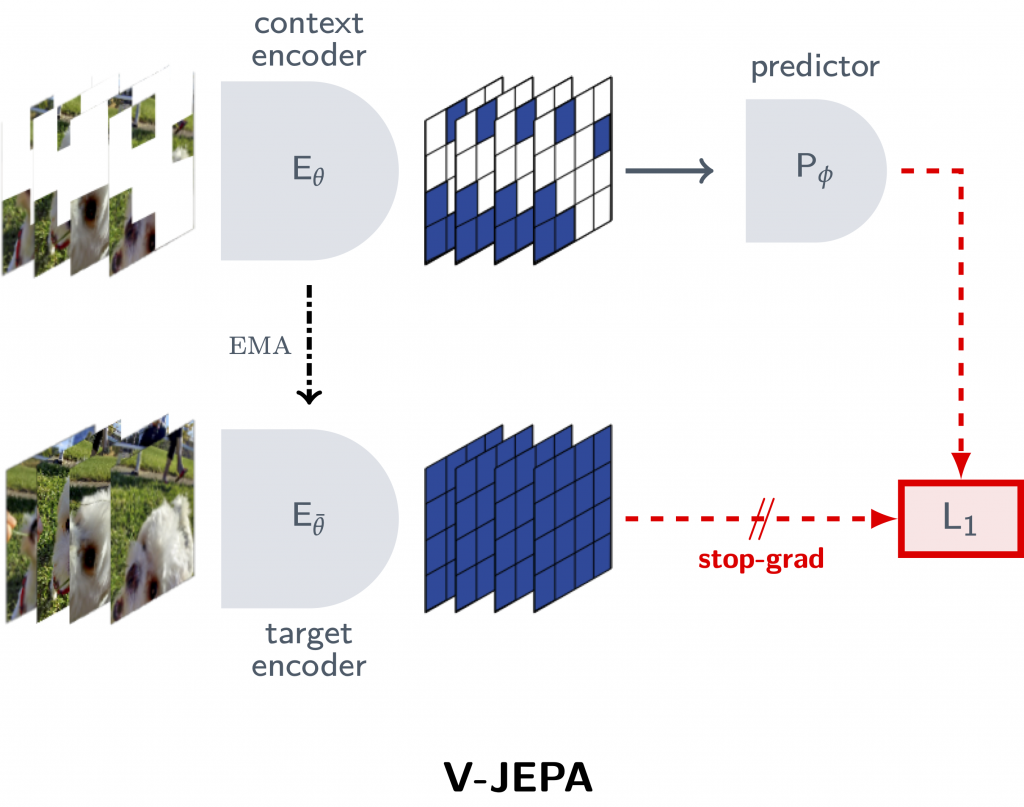
Meta V-JEPA steht für “Video Joint Embedding Predictive Architecture“. Es handelt sich um ein Modell von Meta AI, das darauf abzielt, Künstlicher Intelligenz ein tieferes Verständnis und eine bessere Interaktion mit der physischen Welt zu ermöglichen. V-JEPA lernt durch die Vorhersage von fehlenden oder maskierten Teilen eines Videos in einem abstrakten Repräsentationsraum, was es von generativen Ansätzen unterscheidet. Dieser Ansatz ermöglicht es dem Modell, komplexe Interaktionen und Dynamiken innerhalb von Videos zu verstehen, ohne jede Lücke auf Pixel-Ebene zu füllen, und fokussiert sich stattdessen auf ein höheres, konzeptionelles Verständnis der Videoinhalte.
Hauptteil Meta AI V-JEPA
V-JEPA steht an der Spitze der Bemühungen von Meta AI, Künstliche Intelligenz auf ein neues Niveau des Verständnisses und der Interaktion mit der physischen Welt zu heben. Unter der Leitung von Yann LeCun, dem VP & Chief AI Scientist bei Meta, repräsentiert dieses Modell einen signifikanten Fortschritt in der Art und Weise, wie Maschinen die Umwelt wahrnehmen und interpretieren.
Im Kern ist V-JEPA ein nicht-generatives Modell, das durch die Vorhersage von fehlenden oder maskierten Teilen eines Videos in einem abstrakten Repräsentationsraum lernt. Diese Methodik unterscheidet sich grundlegend von generativen Ansätzen, die versuchen, jede Lücke auf Pixel-Ebene zu füllen. Stattdessen konzentriert sich V-JEPA auf das Verständnis der höheren, konzeptionellen Ebene der Videoinhalte, was eine effizientere Verarbeitung und ein tieferes Verständnis ermöglicht.
Technische Innovation und Effizienz
Ein Schlüsselelement, das V-JEPA von vorherigen Modellen abhebt, ist seine außerordentliche Effizienz im Training und in der Mustererkennung. Durch die Fokussierung auf abstrakte Repräsentationen statt auf direkte Pixelvergleiche ermöglicht V-JEPA eine erhebliche Reduzierung der für das Training benötigten Datenmengen. Diese Effizienzsteigerung, die zwischen dem 1,5-fachen und dem 6-fachen liegt, markiert einen bedeutenden Fortschritt in der maschinellen Lernforschung.
Flexible Anwendungsmöglichkeiten
Die Architektur von V-JEPA ist so gestaltet, dass sie nach dem Prinzip des Self-Supervised Learning funktioniert. Das Modell wird vollständig mit unbeschrifteten Daten vortrainiert, wobei Beschriftungen erst in einem nachgelagerten Schritt für spezifische Aufgaben verwendet werden. Diese Herangehensweise macht V-JEPA nicht nur effizienter im Umgang mit Daten, sondern auch flexibler in seiner Anwendbarkeit auf eine Vielzahl von Aufgaben, ohne die Notwendigkeit, das Modell von Grund auf neu zu trainieren.
Einblick in die Maskierungsmethodik
Ein interessantes Detail von V-JEPA ist seine innovative Maskierungsmethodik. Im Gegensatz zu Ansätzen, die nur kleine Bereiche eines Videos verdecken, maskiert V-JEPA große Teile des Videos sowohl räumlich als auch zeitlich. Diese Strategie zwingt das Modell, ein tieferes Verständnis der dargestellten Szenen zu entwickeln, indem es lernt, die fehlenden Informationen basierend auf dem Kontext der sichtbaren Teile zu extrapolieren. Diese Methode stellt sicher, dass V-JEPA komplexe Interaktionen und Zusammenhänge innerhalb der Videos auf einer abstrakteren Ebene verstehen kann.
Zukünftige Forschungsrichtungen und Anwendungen
V-JEPA öffnet nicht nur neue Wege für das Verständnis von Videos durch KI, sondern legt auch den Grundstein für zukünftige Forschungen in Richtung multimodaler Ansätze, die visuelle Daten mit anderen Informationsquellen wie Audio kombinieren. Dieses Modell bietet eine solide Basis für die Entwicklung von KI-Systemen, die in der Lage sind, komplexe Aufgaben in einer Vielzahl von Bereichen, von der autonomen Navigation bis hin zur Unterstützung bei kognitiven Aufgaben, effizienter und effektiver als bisherige Technologien zu bewältigen.
Durch die Kombination aus fortschrittlicher Effizienz, Flexibilität und einem tiefgreifenden Verständnis der physischen Welt stellt V-JEPA einen bedeutenden Schritt auf dem Weg zu Yann LeCuns Vision einer fortgeschrittenen Maschinenintelligenz dar. Mit seiner Fähigkeit, die komplexen Interaktionen und Dynamiken unserer Welt zu verstehen und vorherzusagen, steht V-JEPA an der Schwelle zu einer neuen Ära der Künstlichen Intelligenz.
Fazit Meta AI V-JEPA
Das Modell V-JEPA von Meta AI repräsentiert eine bahnbrechende Entwicklung in der Welt der Künstlichen Intelligenz, indem es einen Schritt näher an das Ziel heranrückt, Maschinen zu schaffen, die die Welt nicht nur sehen, sondern auch verstehen können. Durch die innovative Nutzung eines nicht-generativen Ansatzes, der auf der Vorhersage von fehlenden oder maskierten Teilen eines Videos in einem abstrakten Repräsentationsraum basiert, hebt sich Meta AI V-JEPA deutlich von bisherigen Modellen ab. Seine Fähigkeit, komplexe Interaktionen und Dynamiken durch Beobachtung zu begreifen, signalisiert einen bedeutenden Fortschritt hin zu einer KI, die menschenähnliches Verständnis und Interaktion mit der Umwelt ermöglicht.
Die technische Innovation und Effizienz von Meta AI V-JEPA, gepaart mit seiner Flexibilität und der einzigartigen Maskierungsmethodik, bieten nicht nur einen Einblick in die gegenwärtigen Fähigkeiten Künstlicher Intelligenz, sondern auch einen Vorgeschmack auf deren zukünftige Entwicklungsmöglichkeiten. Mit der Öffnung neuer Forschungsrichtungen, insbesondere in Bezug auf multimodale Ansätze, legt Meta AI V-JEPA den Grundstein für eine Zukunft, in der KI-Systeme eine noch aktivere Rolle in einer Vielzahl von Anwendungsbereichen spielen könnten.
Die Einführung von Meta AI V-JEPA steht somit nicht nur für einen technologischen Durchbruch, sondern auch für einen Aufruf, die Potenziale und Grenzen der Künstlichen Intelligenz neu zu denken. Es lädt die Wissenschafts- und Forschungsgemeinschaft dazu ein, die Möglichkeiten dieser neuen Technologie zu erforschen und weiterzuentwickeln, um die Vision einer fortgeschrittenen Maschinenintelligenz Wirklichkeit werden zu lassen. Meta AI V-JEPA ist ein leuchtendes Beispiel für das Streben nach einer KI, die die Welt nicht nur durch Daten und Algorithmen, sondern durch ein tieferes, konzeptionelles Verständnis erfassen kann.
Quelle: Meta AI, Meta AI Paper, GitHub
#KuenstlicheIntelligenz #artificialintelligence #KI #AI #Maschinenintelligenz #Technologie #Forschung #MetaAI #VJEPA #Zukunft #Ethik #Innovation #Wissenschaft #Verstehen